
Seth Rao
CEO at FirstEigen
Data Warehouse Architecture: What Are the Types, Traditional vs. Cloud
What is Data Warehouse Architecture?
Data Warehouse Architecture refers to the design and structure of a system used to gather, store, manage, and analyze data from multiple sources to support decision-making processes. It encompasses the components and flow of data, from its initial collection to its final use in business intelligence and reporting. The architecture is typically categorized into traditional and cloud-based solutions, each with unique features, benefits, and limitations. Understanding these architectures is essential for organizations seeking to optimize data management, scalability, and overall business intelligence capabilities.
Quick Takeaways
- Traditional data warehouse architecture consists of three tiers: ingestion servers, transformational OLAP servers, and BI querying and reporting tools
- Cloud data warehouse architecture is more flexible than its traditional counterpart, employing clusters of nodes and slices to handle different types of data
- Cloud data warehouses are better for unstructured data, cost less to build and maintain, and are more easily scalable than traditional solutions
Type of Data Warehouse Architectures
There are several types of data warehouse architectures, each designed to meet different business needs. These include:
- Single-Tier Architecture: This architecture minimizes data storage by deduplicating data. It is typically used for smaller organizations that do not need enterprise-wide data access. However, performance can suffer when transactional and analytical processes are not separate.
- Two-Tier Architecture: In a two-tier model, data is extracted from transactional databases, transformed, and loaded into a centralized data warehouse. This architecture often includes data marts for specific business user applications. While it offers better performance than single-tier, scalability and support for large numbers of users can be challenging.
- Three-Tier Architecture: This is the most common approach, consisting of three layers:
- Bottom Tier: The data warehouse servers that store the data.
- Middle Tier: An OLAP (Online Analytical Processing) server that abstracts data for user queries and enhances scalability.
- Top Tier: A front-end layer with business intelligence tools and APIs for data extraction and analysis.
- Three-tier architecture is highly scalable and supports large, complex data processing.
Each architecture can be optimized with additional components, such as data marts, OLAP servers, or clusters for better performance, flexibility, and decentralization. The design can evolve as the data strategy grows, allowing for easy integration of new components or models like bus, hub-and-spoke, or federated architectures.
Understanding Traditional Data Warehouse Architecture
The global data warehouse market is expected to reach $51.18 billion by 2028. That’s a 10.7% CAGR from 2020 to 2028.
Data warehouses have traditionally been hosted on-premises. Enterprises provision servers, software, and other IT resources to ingest, house, and serve data to in-house customers.
Traditional data warehouse architecture has three tiers:
- Bottom tier – consists of the data warehouse servers that extract and store data obtained from a variety of sources
- Middle tier – consists of online analytical processing (OLAP) servers that transform the data into a standard structure
- Top tier – consists of front-end business intelligence (BI) tools that users employ for queries, reports, and analytics
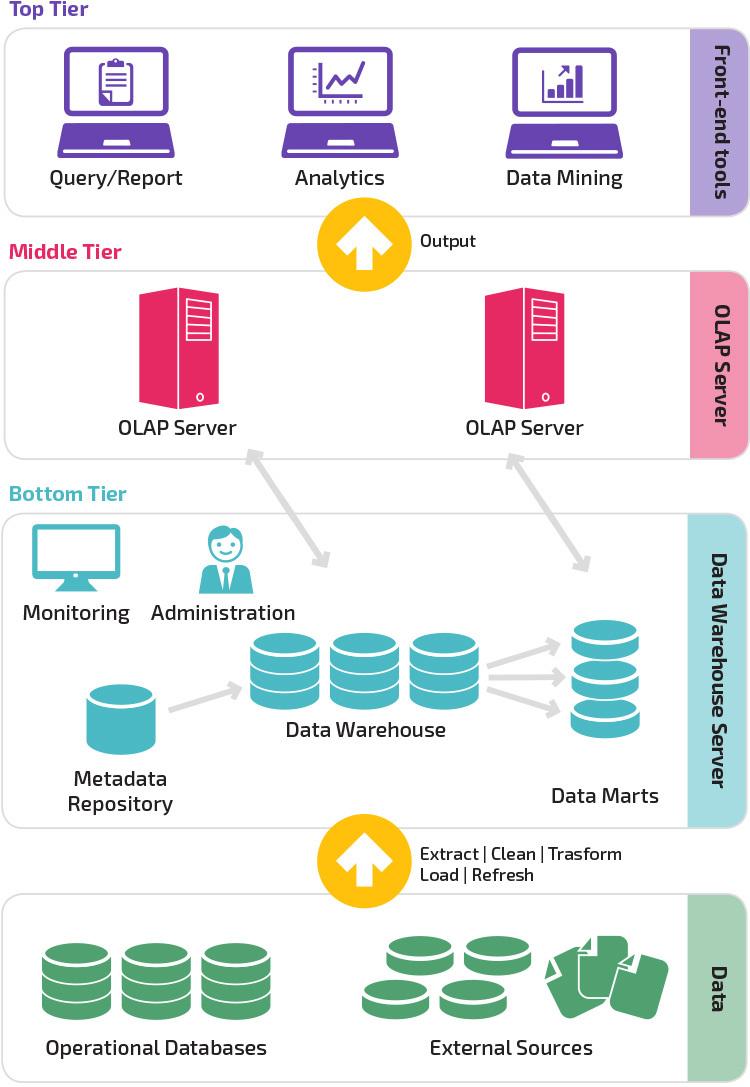
The original data can come from various sources. These can include operational databases, front-end applications, CRM systems, and ERP systems – both internal and external.
Data is pulled into the warehouse using Extract, Transform, and Load (ETL) tools. These ETL tools merge data from disparate sources into a single data store. Data quality monitoring and cleaning typically happens at this step.
The OLAP servers in the middle tier transform all that data into a single defined structure. This structured data is easier to manage and query than data in a number of different structures – or data with no structure at all.
Users interact with the data warehouse via the top tier’s BI tools. These tools enable users to search the data, generate reports, and analyze the data.
Understanding Cloud Data Warehouse Architecture
As with many computer-related functions, data warehouses are moving to the cloud. According to Yellowbrick’s Key Trends in Hybrid, Multicloud, and Distributed Cloud report, 47% of enterprise IT professionals say their data warehouses are cloud-based, with another 35% using a mix of traditional and cloud data warehouses.
Cloud-based data warehouses, such as Amazon Redshift and Google BigQuery, don’t have to conform to traditional architectures. This enables enterprises to construct unique approaches to the specific data they use. These cloud-based solutions don’t require significant IT investments or large IT staff. Setup is relatively quick and inexpensive, and the warehouses are easily scalable as needs – and data loads –change over time.
While different cloud providers offer different architectural approaches – Amazon Redshift is considerably different from Google BigQuery – most cloud data warehouses adhere to a general design. Most cloud data warehouse architecture includes the following elements:
- Clusters – large groups of nodes
- Nodes – computing resources with their own individual CPUs, RAM, and memory
- Partitions – a slice of a node, allocated its own memory and disk space on the node
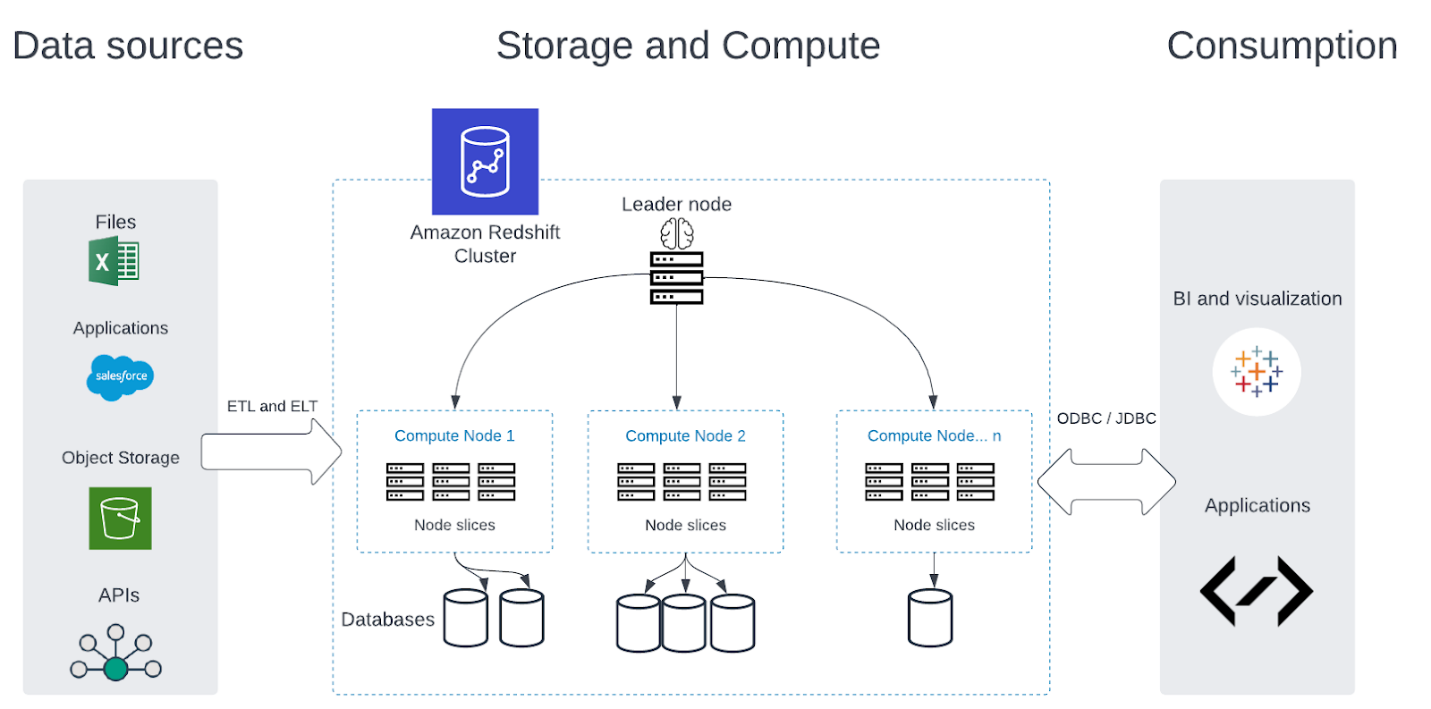
A cluster with two or more nodes is organized into leader nodes and compute nodes. The leader node communicates with client apps to execute client queries. Compute nodes do the grunt work of executing queries and serving results to the leader node.
Like traditional data warehouses, cloud-based data warehouses tend to have a three-part structure: data sources, storage and computing, and consumption.
For example, in Amazon Redshift, data is ingested from multiple sources. The ingested data moves to a computing cluster comprising a leader node and multiple compute nodes. Each compute node consists of multiple databases in their own slices. Consumption employs multiple BI and visualization tools to access data stored in the computing cluster.
Because of this approach, most cloud data warehouses don’t need to pre-structure data before it is stored and accessed. This enables the use of unstructured data, which can add a richer and more subtle texture to reports and analytics.
Traditional vs. Cloud Data Warehouses
While both traditional and cloud data warehouses serve the same functions of ingesting, storing, and serving data, their differing approaches make each more or less attractive in particular ways.
Consider the following:
- Data storage: Traditional data warehouses can handle only a limited amount of data. Cloud-based solutions can handle virtually limitless data.
- Data structure: Traditional solutions are best for structured data only, as they have difficulty handling unstructured and semi-structured data. Cloud data warehouses, on the other hand, can easily handle unstructured data as well as more standardized datasets.
- Interoperability: Cloud data warehouses have a virtual interoperable layer that enables easy integration of data from different systems. Traditional systems don’t, making interoperability more challenging.
- Up-front costs: Because cloud-based data warehouses require little on-premises equipment and technology, they cost much less to create than traditional data warehouses.
- Ongoing costs: Traditional data warehouses require costly ongoing maintenance and upgrades. Cloud data warehouses require monthly payments to the cloud provider that tend to even out ongoing maintenance costs.
- Performance: With traditional data warehouses, high data volumes increase the server load and diminish performance. Cloud-based solutions are speedier, with most providers guaranteeing 99.9% uptime.
- Flexibility: Cloud data warehouses can accommodate a variety of formats and structures. Traditional systems are much less flexible.
- Scalability: Scaling traditional systems is tedious, time-consuming, and costly. Cloud-based providers offer affordable on-demand scaling.
- Security: Traditional on-premises data warehouses are easier to secure. Cloud-based data warehouses have more potentially vulnerable entry points for malicious actors because they’re accessed via the Internet.
In short, if your organization needs a fast and flexible solution with lower up-front costs, moving to the cloud is the way to go. Cloud data warehouses are particularly attractive to smaller and medium-sized organizations that don’t have the financial or staff resources to build and maintain internal warehouses.
| Feature | Traditional Data Warehouse | Cloud Data Warehouse |
|---|---|---|
| Data Storage | Limited capacity, on-premises | Virtually unlimited, scalable |
| Data Structure | Best for structured data | Handles structured & unstructured data |
| Cost | High upfront investment, ongoing maintenance | Lower upfront costs, pay-as-you-go pricing |
| Scalability | Limited and costly to scale | Scalable on-demand |
| Performance | Decreases with higher data volumes | Consistent, high performance with cloud resources |
| Security | Easier to secure on-premises | More entry points but advanced security features in the cloud |
| Flexibility | Less flexible, requires manual adjustments | Highly flexible, supports various data formats |
Detect Data Issues Before They Impact Business Decisions
Transform Your Data Warehouse With DataBuck’s Data Quality Solutions
Whether you choose a traditional or cloud-based approach, FirstEigen’s DataBuck can improve the quality of data flowing into and through your data warehouse. Our DataBuck data quality management solution automates more than 70% of the traditional data monitoring process, utilizing machine learning to automatically generate new data quality rules as your data needs change. DataBuck works with all major traditional and cloud data warehouses and provides the high-quality data your organization needs to better run your business.
Contact FirstEigen today to learn more about data quality in data warehouses.
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQ
Data warehouse architecture refers to the design and structure of a data storage system that integrates data from various sources for querying and reporting. It includes components like ETL (Extract, Transform, Load), a central database, metadata, and access tools for data analytics. This architecture ensures that businesses can store historical data in a centralized location and use it for decision-making processes.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

What Do Failed AI Projects Have in Common?
Most AI failures are not model failures — they are data, governance, operational trust, and weak AI-ready foundations. “AI alone is not the solution – trusted, validated, continuously governed data is the…

Why Data Trust Is the Real Foundation of AI Success
Enterprises are racing to adopt AI—LLMs, copilots, and autonomous agents that can trigger actions across systems. But as AI moves…

AI-Powered Data Quality Validation for Smarter AML Detection
Fraud, Anti-Money Laundering (AML) and counter-terrorist financing (CTF) programs are only as good as the data they consume. Advanced monitoring…
Bad Data Is Costing You More Than You Think
