
Seth Rao
CEO at FirstEigen
Your Guide to Overcoming Data Warehousing Challenges: Error Handling, Validation, and Common Issues
Without adequate data error handling in a data warehouse, the data stored can become unusable. Traditional methods of data error handling rely on a rule-based approach that is difficult to manage and does not easily scale. Today, data warehouses require a more scalable solution that can autonomously monitor large volumes of data, detecting and correcting errors in real time.
Let’s discuss how data error handling works and why it’s essential for the smooth running of your operations.
Struggling with Data Errors? Experience Real-Time Data Validation Now!
Quick Takeaways
- A data warehouse is a static database that stores data ingested from other operational databases.
- Poor-quality data – either from the original database or introduced during the ingestion process – can compromise the integrity of a data warehouse.
- Traditional data error handling solutions do not easily scale nor handle the volume and types of data produced today.
- New data error handling solutions must leverage AI and ML to function autonomously, validate in place, and scale as your needs change and grow.
Understanding Data Warehousing
A data warehouse is a relatively static database for storing an organization’s historical data. Unlike an operational database, which is accessed daily for operational purposes, a data warehouse functions more like a non-volatile archive of data that does not require regular access.
An operational database is constantly accessed by members of your organization. It includes data necessary for day-to-day operations and is constantly updated with new and changed data.
A data warehouse, in contrast, contains data that is not necessary for your organization’s day-to-day operations and does not need to be regularly updated. It is separate from operational databases but equally accessible.
A data warehouse can be located either on-premises, in the cloud, or in a combination of location. According to Yellowbrick’s Key Trends in Hybrid, Multicloud, and Distributed Cloud for 2021 report, 47% of companies house their data warehouses in the cloud, with just 18% being entire on-premises.
The data in a data warehouse is derived from data in various operational databases through the ETL (extract, transform, and load) process. The data warehouse is typically used to generate reports, answer ad hoc queries, and inform other business analysis.
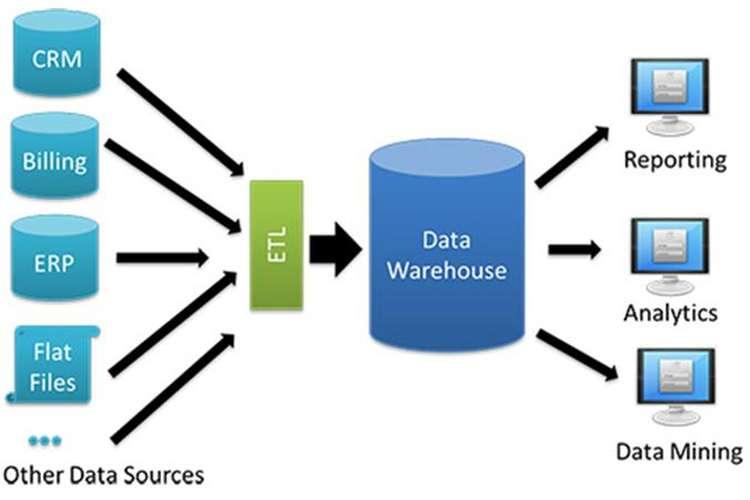
Image Source: Internet
Traditional Data Error Handling: Limitations and Risks
As data is ingested from operational databases into a data warehouse, errors can occur. The errors can be present in the operational databases or introduced during the ETL process and contribute to the estimate that 20% of all data is compromised, which can affect data analysis and decision-making. For this reason, data errors must be identified and properly handled before those errors jeopardize the integrity of the data warehouse.
Understanding the causes of data errors is crucial to maintaining data quality. Here are some common sources:
- Annotation Errors: Mistakes made during data input, validation, or processing can lead to inaccuracies. This often happens when human judgment is involved, highlighting the need for thorough training and clear guidelines.
- Incomplete Data: Missing or incomplete information within a dataset can severely limit the validity of analyses and conclusions. Ensuring data completeness through regular audits can help mitigate this risk.
- Inadequate Validation: When data validation and quality checks are insufficient, inaccurate or inconsistent data may persist in the system. Implementing robust validation protocols is essential to catch these errors early.
- Lack of Documentation: Poorly documented data sources and procedures can result in misunderstandings and misinterpretations. Comprehensive documentation helps in maintaining consistency and clarity throughout data processes.
By addressing these underlying causes, organizations can significantly reduce the risk of data errors and ensure that their data warehouses remain reliable and effective tools for decision-making.
Unless data errors are caught during the ingestion process, issues with poor data quality typically surface when stakeholders engage in data analysis using data in the data warehouse. Our research estimates that 20-30% of the time spent on reporting and analysis is actually spent on identifying and fixing data errors.
Data Source: Internet
Traditional tools used to validate ingested data do not scale easily. They typically establish data quality rules for just a single table at a time. This makes it difficult to work with large or multiple operational databases that might require data validation for hundreds of tables. The challenges for implementing new data-handling rules are several and substantial:
- Requires input from subject matter experts
- Rules have to be specific for each table
- Data has to be moved to a data quality tool for analysis
- Existing tools have limited capability for creating audit trails
- Existing rules need to be reevaluated as data evolves
The result is that current methods for handling data errors are time-consuming, resource-intensive, lack proper security, and do not easily scale.
What are Data Errors?
Data errors are essentially flaws or inaccuracies that disrupt the integrity of data during collection, processing, or storage. These errors can stem from various issues such as missing data, duplicates, outliers, inconsistencies, or incorrect entries. In today’s data-centric landscape, addressing these errors is crucial because they can significantly impact insights and decisions based on the data.
Types of Data Errors
- Missing Data: This occurs when expected data values are absent, potentially leading to skewed analysis. Techniques like imputation are often used to fill these gaps.
- Duplicates: Multiple identical entries can inflate or distort data statistics, requiring deduplication processes to ensure accuracy.
- Outliers: These are atypical values that can indicate either a genuine variation or an error. They necessitate detailed examination to determine their validity.
- Inconsistencies: When similar data points do not match, it can create confusion and lead to faulty conclusions.
- Inaccuracies: Typographical or input errors can occur, which require keen validation methods to correct.
Impact of Data Errors
The significance of a data error often hinges on its context. For instance, dealing with missing data might necessitate sophisticated modeling to predict and fill the voids reliably. Conversely, outliers require careful scrutiny—deciding whether they represent true anomalies or if they’re mere mistakes is essential for ensuring data validity.
In summary, the challenge lies not only in identifying data errors but also in rectifying them effectively to maintain data’s value as a reliable decision-making tool. This is why data quality management is an integral part of any robust data strategy.
Impacts of Data Errors Across Various Sectors
The effects of data errors can be profound and far-reaching. Here’s how they manifest in different areas:
Finance
In the financial sector, precision is paramount. Errors here can skew accounting practices, leading to inaccurate financial reports and poor investment choices. Such mistakes not only dent the credibility of financial institutions but can also result in hefty financial losses.
Healthcare
For healthcare, data plays a crucial role in ensuring patient safety and care quality. Mistakes in medical records can compromise machine learning algorithms, crucial for diagnosis and treatment. These inaccuracies risk not only the integrity of patient care but also the trust in healthcare systems.
Manufacturing
The production domain thrives on efficiency. Erroneous data can hinder machine learning applications, leading to product defects, unexpected equipment malfunctions, and increased costs. These issues jeopardize both productivity and profitability.
E-commerce
In the world of e-commerce, customer satisfaction relies heavily on data accuracy. Errors in pricing or inventory details can lead to customer frustration, financial losses, and a tarnished brand image, as algorithms fail to reflect the correct information.
Research
In the research sector, the validity of experimental outcomes depends on accurate data. Errors here can question the authenticity of studies, wasting resources, and potentially misleading future research directions.
Each industry faces unique challenges due to data errors, underlining the importance of accuracy to maintain operational integrity and trust.
Ensure Data Accuracy at Scale with AI-Powered Validation
Advanced Error Handling: Modern Solutions for Scalable Data Validation
Today’s increasing reliance on larger data warehouses that ingest data from a variety of sources requires new solutions for data error handling. Without proper data error handling, the resulting poor-quality data can result in increased costs and poor business decisions.
This situation requires a new framework for data error handling. This new framework should automatically identify and handle those key errors that contribute to poor data quality, including:
- Accuracy (Is data within expected parameters?)
- Completeness (Are all fields fully populated?)
- Consistency (Are data pulled from multiple data sets in sync with one another?)
- Timeliness (Is data new enough to be relevant?)
- Uniqueness (Are data points duplicative?)
- Validity (Is data of the proper type?)
To do this, the new framework should include several key criteria, as follows.
1. Function Autonomously
Any new data error handling solution needs to function autonomously, without the constant need for human input and review. In essence, the solution must be able to automatically:
- Create new validation checks when new tables are created
- Update existing validation checks when there are changes in the underlying data
- Validate incremental data as it arrives
- Issue alerts when the number of errors reaches a critical level
2. Leverage AI and ML Technologies
To function autonomously, a data error handling solution must use artificial intelligence (AI) and machine learning (ML) technologies. Using AI and ML enables the solution to immediately identify data errors without manual intervention, as well as establish new rules and validation checks as the system evolves. Because an AI/ML-based system operates independently, it should function efficiently regardless of the number of data tables involved.
3. Validate in Place
Data validation must take place at the source. Moving the data to another location for validation introduces latency and increases security risks.
4. Function as Part of the Data Pipeline
Additionally, data error checking should be part of the overall data pipeline, not a side activity.
5. Be Easily Scalable
Any new data error handling solution must be quickly and easily scalable. As the volume of data increases in the future, data validation should keep pace without getting bogged down or requiring additional computing resources.
6. Has API Integration
Any data error handling solution needs to easily integrate with other systems and platforms in your operation. That requires an open API that integrates with enterprise, workflow, scheduling, CRM, and other systems.
7. Generate Audit Trail
As data is validated, the data error handling solution should generate a detailed audit trail. This enables staff to quickly and accurately audit validation test results.
8. Provide Stakeholder Control
Finally, any robust data error handling solution should provide business stakeholders with complete control over the process. This includes being able to fully examine automatically created rules, modify or delete existing rules, and add new rules as necessary – without the need for complex coding or reprogramming.
How DataBuck Ensures Accurate and Reliable Data Warehousing
When you need better data error handling for your data warehouse, turn to DataBuck from FirstEigen. DataBuck is an autonomous data quality management solution that uses AI and ML technology to automate more than 70% of the data monitoring process. Our system is fast and accurate and ensures that the data you ingest into your data warehouse is always of the highest quality.
Contact FirstEigen today to learn how DataBuck can improve the data quality in your organization’s data warehouse.
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQ
Data warehouse validation ensures that data is accurate, complete, and consistent throughout its lifecycle. It involves processes like data integrity checks, schema validation, and cross-system verification to avoid errors.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

The Power of Data Quality for AI Success
AI agents are only as reliable as the data they act on. As enterprises race to deploy AI, data quality has quietly become the deciding factor between success and costly failure. The Problem Nobody Is Solving Most AI conversations…

Mainframe Data Reconciliation for Cloud Migration
Cloud migration is no longer just an infrastructure decision. For data leaders and data engineers, it is a trust decision. …

What Do Failed AI Projects Have in Common?
Most AI failures are not model failures — they are data, governance, operational trust, and weak AI-ready foundations. “AI alone is not the solution – trusted, validated, continuously governed data is the…
Bad Data Is Costing You More Than You Think
