
Seth Rao
CEO at FirstEigen
10 Data Ingestion Tools to Fortify Your Data Strategy
What data ingestion tools should you use in your organization? It depends on what type of data you’re ingesting and how fast you need it ingested. The quality of the ingested data also matters, which you can ensure by supplementing data ingestion with data quality monitoring.
Quick Takeaways
- Data ingestion imports data from multiple sources to a single destination.
- Data ingestion tools transfer both structured and unstructured data, either in batches or in real time.
- Some of the more popular data ingestion tools include Airbyte, Amazon Kinesis, Apache Flume, Apache Gobblin, Apache Kafka, Apache NiFi, Dropbase, Integrate.io, Matillion, and Precisely Connect.
Understanding Data Ingestion
Data ingestion is the process of importing data from one or more sources to a destination site for further use and analysis. Ingested data can come from a variety of sources, including existing databases, data lakes, and real-time data from IoT devices and other apps and services.
There are three primary ways to ingest data:
- Real-time, where data is collected and transferred as it is captured; this is typically the fastest form of data ingestion.
- Batch-based, where data is collected or stored beforehand and ingested in batches at regular intervals.
- Lambda architecture, which combines real-time and batch ingestion – quickly for real-time and slower for batch.
The type of data ingestion tool you use depends on the type of data you intend to ingest.
(The following video explains more about what data ingestion is and how it works.)
What is a Data Ingestion Tool?
A data ingestion tool is a software solution designed to collect, import, and process data from various sources into a storage system, such as a data warehouse or data lake. These tools play a crucial role in ensuring that data from multiple origins, like databases, APIs, and files, is consistently gathered and made available for analysis and reporting.
By automating the data collection process, a data ingestion tool helps maintain the accuracy and timeliness of the data, allowing businesses to make informed decisions based on the most current information. These tools are essential for handling large volumes of data efficiently, ensuring that it is ready for use across different platforms, including cloud environments like Azure and Snowflake.
How Data Ingestion Tools Work?
You ingest data into your company or organization with a data ingestion tool. This is a software product or service that transfers data – both structured and unstructured – from the original source to your target destination.
The data ingestion tool helps move data through a larger data pipeline. The pipeline consists of a series of steps that process the data from one point to another, from original storage through ingestion and ETL (extract, transform, load), to the final data warehouse for use and analysis.
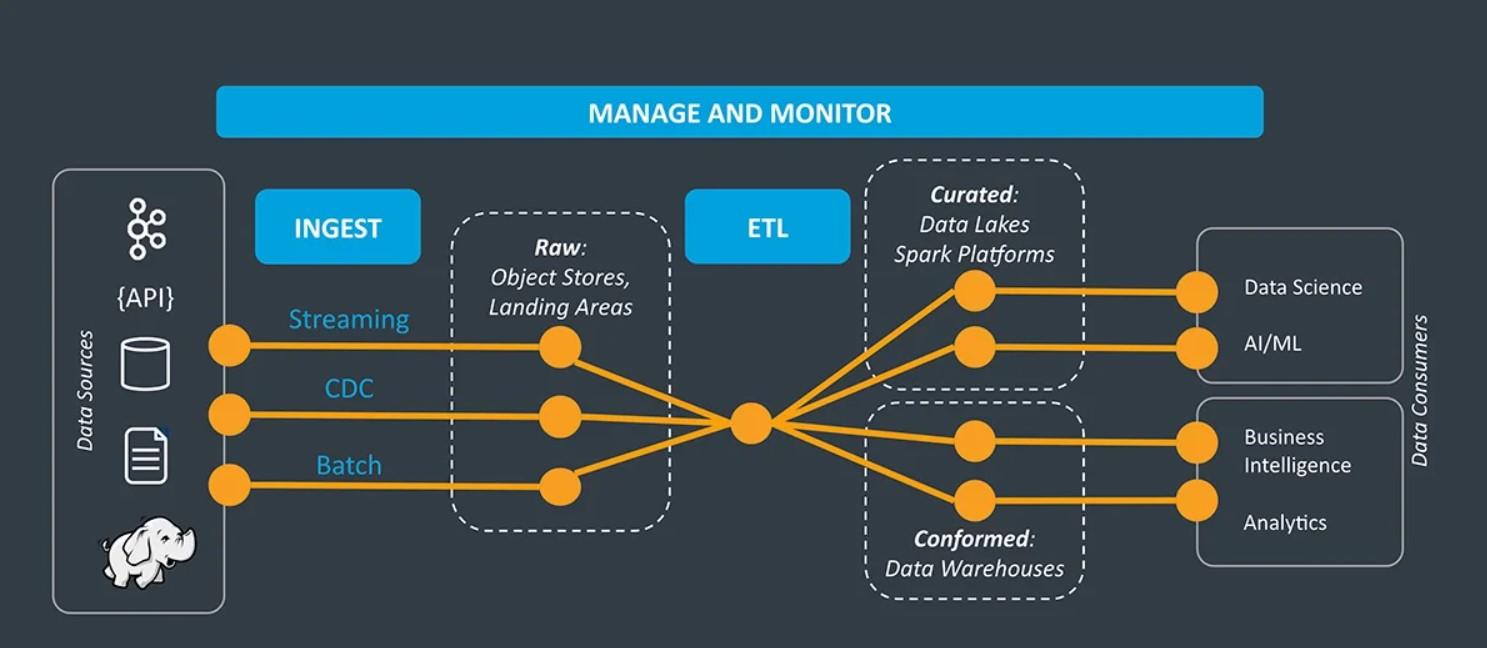
The ingestion process itself consists of several key steps. In batch ingestion, for example, the steps include:
- Authenticate the source data
- Create the dataset
- Create the batch
- Upload the file
- Complete the batch ingestion

Data ingestion tools automate what would otherwise be a long and tedious manual process. You can use data ingestion tools to transfer data from one type of storage to another (from an on-premises server to a cloud-based service, for example), from one database to another, or from other sources both inside and outside your firm.
10 of the Best Data Ingestion Tools to Explore
The 10 best data ingestion tools, reviewed and highly rated, are listed below for your consideration.
1. Airbyte
Airbyte is an open-source data ingestion tool (with a free version for small businesses) that focuses on extracting and loading data. It’s designed to ease the setup of data pipelines and then maintain data flow through the pipeline. It integrates with more than 120 data connectors, including Google Analytics, Salesforce, and local files. It provides access to both raw data and normalized data (for analysis).
2. Hevo
Hevo is a fully automated, no-code Data Pipeline Platform that supports 150+ ready-to-use integrations across Databases, SaaS Applications, Cloud Storage, SDKs, and Streaming Services.
3. Amazon Kinesis
Amazon Kinesis is a cloud-based service for data ingestion and processing. It’s capable of ingesting and analyzing large distributed data streams from thousands of different sources and is easily scalable.
4. Apache Flume
Apache Flume is a data ingestion tool designed to handle large amounts of data. It is primarily focused on extracting, ingesting, and loading data from a variety of sources into a Hadoop Distributed File System (HDFS). Users find Flume both robust and easy to use.
5. Apache Gobblin
Like Apache Flume, Apache Gobblin is also designed to load large data volumes from multiple sources into HDFS. It handles not just ingestion and ETL but also basic data quality management, error correction, and task partitioning.
6. Apache Kafka
Apache Kafka is noted for its high throughput and low latency, which makes it ideal for high-volume real-time streaming data pipelines. It easily connects to a variety of external systems for data import and export.
7. Apache NiFi
Apache NiFi is specifically designed to automate the flow of data between software systems. Like Apache Kafka, NiFi provides high-throughput and low-latency performance, as well as robust loss tolerance.
8. Dropbase
Dropbase is a platform that transforms offline data into live databases in real time. It can ingest and process data from a variety of sources, including Excel spreadsheets and CSV files, and enables team collaboration on data projects.
9. Integrate.io
Integrate.io is a data ingestion and integration tool with a drag-and-drop interface that makes it easy to ingest data from various types of data sources. It provides more than 100 data connectors and also offers data transformation functionality.
10. Matillion
Matillion is a data ingestion and ETL tool that offers more than 70 connectors for a variety of data sources. It’s especially useful for SMBs who want to migrate data from existing databases and applications to a cloud-based database. Its free tier is especially attractive.
Top 5 Open Source Data Ingestion Tools for Cost-Effective Data Strategies
Open-source data ingestion tools offer flexibility without the cost of licensing. Here are five top options:
- Meltano: Meltano, an open-source alternative to Fivetran, offers data extraction, loading, and transformation with community-driven development.
- Talend Open Studio: Talend Open Studio provides a drag-and-drop interface for complex data ingestion, with strong community support for various environments.
- Singer: Singer simplifies data extraction using a standard JSON format, ideal for integrating diverse data sources.
- Embulk: Embulk handles large data volumes with scalability and integrates with various databases and cloud services.
- Apache NiFi Registry: NiFi Registry manages and versions data flow configurations, perfect for complex, multi-environment data pipelines.
Best Practices for Choosing Big Data Ingestion Tools
Choosing the right big data ingestion tool involves:
- Flexibility: Opt for tools that adapt to changing data needs with customizable features.
- Security: Ensure tools offer robust security and compliance with industry standards.
- Real-Time Processing: Select tools that support real-time data streaming for timely insights.
- Ease of Use: Choose tools with intuitive interfaces and strong developer support to reduce complexity.
- Avoid Vendor Lock-In: Prioritize tools with broad compatibility across platforms to maintain.
Why You Need to Monitor Data Ingestion Quality?
Maintaining high data quality is essential when you’re ingesting data from various sources. While some data ingestion tools monitor the quality of the data ingested, many simply import data as-is, faults and all. This leaves you with a database of questionable-quality data that may or may not be usable as intended.
Ensuring data quality is also important when you’re migrating data to the cloud. You don’t want your data quality to be compromised during the transfer when random data errors can be introduced.
For this reason, you need to pair your data ingestion platform with a high-performance data monitoring solution, such as DataBuck from FirstEigen. DataBuck offers seven key data monitoring functionalities that identify data errors and either correct them or delete suspect records. Adding DataBuck data monitoring to data ingestion provides you with the data and the data quality your business requires.
Let DataBuck Monitor Your Data Ingestion Process
Whether you’re ingesting batch or real-time data, turn to DataBuck from FirstEigen to ensure high-quality results. DataBuck is an autonomous data quality management solution that automates more than 70% of the data monitoring process. It is fast and accurate and ensures that the data you ingest is always of the highest quality.
Contact FirstEigen today to learn how DataBuck can improve your firm’s data ingestion process.
Check out these articles on Data Trustability, Observability & Data Quality Management-
- 6 Key Data Quality Metrics You Should Be Tracking
- How to Scale Your Data Quality Operations with AI and ML?
- 12 Things You Can Do to Improve Data Quality
- How to Ensure Data Integrity During Cloud Migrations?
- Data Ingestion Process Flow
- Snowflake Data Ingestion
- Guide to Data Pipeline Tools
Did You Find This Helpful?
Thanks you for response.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

What Do Failed AI Projects Have in Common?
Most AI failures are not model failures — they are data, governance, operational trust, and weak AI-ready foundations. “AI alone is not the solution – trusted, validated, continuously governed data is the…

Why Data Trust Is the Real Foundation of AI Success
Enterprises are racing to adopt AI—LLMs, copilots, and autonomous agents that can trigger actions across systems. But as AI moves…

AI-Powered Data Quality Validation for Smarter AML Detection
Fraud, Anti-Money Laundering (AML) and counter-terrorist financing (CTF) programs are only as good as the data they consume. Advanced monitoring…
Bad Data Is Costing You More Than You Think

Would you like to tell us why?