In the 21st century, data has become a natural resource. Like oil or precious metals in the ground, the data created in human digital activities exist in a raw form that becomes valuable when extracted and used. The potential value of extracted, analyzed data has precipitated the development of new methods and practices for processing raw data in useful ways. The term DataOps – a combination of “data” and “operations” – describes the most sophisticated iteration of these methods and practices.
The global amount of data human beings create and replicate annually has grown more than 1,200% in the last ten years– from 6.5 zettabytes in 2012 to 79 in 2021. By 2025, it will more than double to 181 zettabytes.
The value this data represents tracks with this compound growth. Market research valued the global market for big data analytics at $37 billion in 2018. This market value will reach $105 billion by 2027, demonstrating a sustained CAGR of 12.3% for the decade.
With the rapid growth in data analytics on the horizon for the foreseeable future, businesses that traffic in data should take the time to familiarize themselves with DataOps. Read on to learn what DataOps is and some of the problems it can solve.
Key Takeaways
- DataOps is a set of practices in data analytics that aims to reduce cycle time.
- DataOps inherits conceptual frameworks from three related production philosophies: DevOps, Agile software development, and lean manufacturing.
- DataOps applies automation solutions to the problems of high cycle times and limited validations in data analytics.
What is DataOps?
DataOps is a set of practices in data analytics that aims to reduce cycle time – the time that elapses between the start of a process in data analytics and the delivery of finished, ready-for-use analytics.
Compared to the human mind, the computational abilities of programs often seem infinite. We stare at the ceiling for 30-60 seconds doing visualized mental math to add two 4-digit numbers in our heads. By contrast, programs on our phones and computers make exceedingly more complicated calculations – with much larger numbers.
Nevertheless, even programs have upper limits for the amounts of information they can process quickly and accurately. In the last few decades, innovations on the internet, smartphones, social media, and other technologies exponentially increased the scale of data regularly handled in research and commerce. In the process, what is now called big data revealed practical limitations for relational database management systems.
As data scientists developed new solutions for big data problems, DataOps evolved on the operations side of things as a practical approach to data management in organizations.
3 Methodologies DataOps Use
DataOps, as an organizational practice, inherits many frameworks from three widely successful methods of design and production.
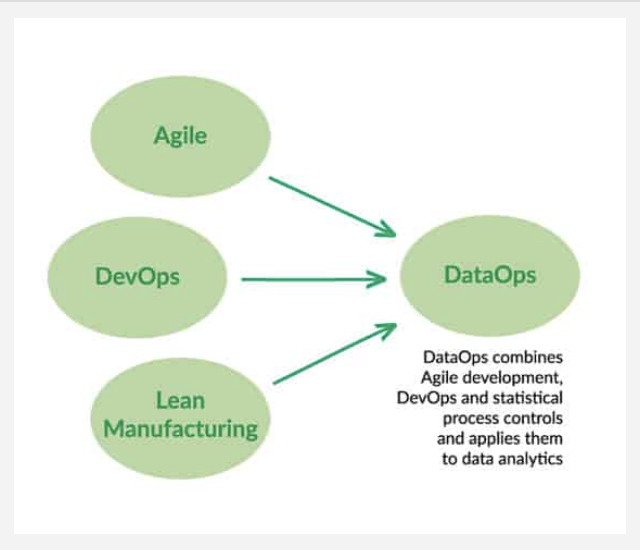
1. DevOps
DevOps – a portmanteau of “development” and “operations” – is an approach to software engineering that delivers up-to-date continuous deployments of software.
To understand what this means, it helps to think about how developers used to sell software. Twenty years ago, you bought programs such as Windows or Microsoft Office as bundles of CDs to install on a desktop. Once installed, you ran that version on its own until the developer released an entirely new version to replace it a few years later.
In the meantime, while developers worked on fixing bugs and improving their products, users had no way to experience the benefits of ongoing development. The DevOps approach integrates software development and IT operations to shorten the systems lifecycle that causes software products to lag months to years behind their best live versions.
2. Agile Software Development
In software engineering, Agile development contrasts with the more traditional Waterfall approach. Rather than completing phases such as building and testing linearly, Agile development attempts to complete multiple stages simultaneously through constant cross-functional feedback.
3. Lean Manufacturing
Manufacturers use the concept of lean manufacturing to minimize production waste while maintaining high efficiency. In IT processes, being lean refers to the use of statistical process control (SPC) and step-by-step verification in the development pipeline to prevent errors from accumulating downstream.
The Combined DataOps Framework
DataOps attempts to integrate these three frameworks into a single coherent method for faster and more reliable data analytics.
- From DevOps and Agile software development it draws continuous deployment and multiphase workflows.
- It applies lean manufacturing SPCs to the data production pipeline to eliminate aberrations early and deliver cleaner and more reliable end-user data.
What Kind of Problems Does DataOps Solve?
DataOps is most easily understood as a problem-solving approach to data analytics. Rather than delivering different kinds of analytics, DataOps attempts to remove data production roadblocks and deliver the same analytics faster and with higher quality. Specifically, DataOps addresses two kinds of problems.
High Cycle Times
Data scientists currently spend half their time in manual processes of data loading and cleansing. These tasks slow cycle times to a crawling pace of weeks to months for a few dozen lines of SQL. Given the high degree of education and training data scientists receive, this amounts to an unsustainable waste of valuable human resources.
Bad Data
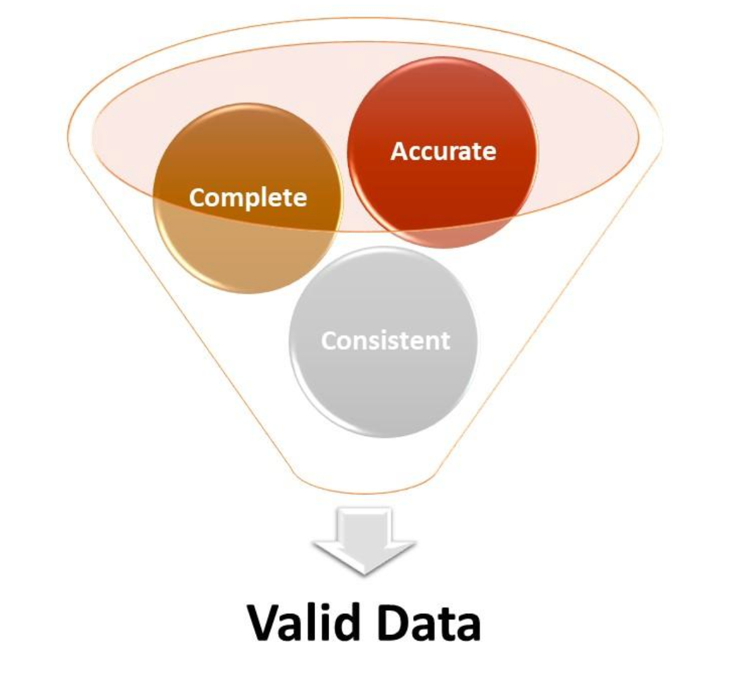
Bad data costs businesses more than $700 billion annually. Nevertheless, manual validations are expensive and most companies that traffic in big data only have the resources to validate about 5% of their data. Without a systemic validation solution, companies cannot know whether they are analyzing data that is accurate, complete, and consistent.
For DataOps, these problems represent opportunities to replace repetitive manual processes with automation and to reduce organizational barriers to collaboration between data scientists, analysts, and IT personnel. Where DataOps introduces automation, the processes should always accommodate subsequent growth at any scale and unpredictable changes in data variety.
FirstEigen: Faster Data Analysis and Fewer Errors
Traditional data validation solutions can’t keep up with the explosive growth of big data. As scaling costs continue to rise, so does the rate at which errors enter your increasingly unmonitored data. Doubling down on failing methods won’t solve the problem. FirstEigen’s DataBuck addresses the problem of data validations head-on by automating menial processes and improving those processes over time with machine learning.
To learn more and schedule a free demo of DataBuck, contact FirstEigen today.
Check out these articles on Data Trustability, Observability, and Data Quality.
- 6 Key Data Quality Metrics You Should Be Tracking (https://firsteigen.com/blog/6-key-data-quality-metrics-you-should-be-tracking/)
- How to Scale Your Data Quality Operations with AI and ML (https://firsteigen.com/blog/how-to-scale-your-data-quality-operations-with-ai-and-ml/)
- 12 Things You Can Do to Improve Data Quality (https://firsteigen.com/blog/12-things-you-can-do-to-improve-data-quality/)
- How to Ensure Data Integrity During Cloud Migrations (https://firsteigen.com/blog/how-to-ensure-data-integrity-during-cloud-migrations/)