
Seth Rao
CEO at FirstEigen
How to Scale Your Data Quality Operations With AI and ML?
How can you cost-effectively scale your data quality operations as your business scales? The key is to employ artificial intelligence and machine learning technology that can take on an increasing amount of the data quality management chores as they learn more about your organization’s data. It’s all in the about making the best use of the data you collect – and making sure that data is as complete and accurate as possible.
Quick Takeaways
- Data quality is important for the efficient and effective running of your business.
- As more data is collected from more data sources, it becomes more difficult and more expensive to monitor data quality.
- Data quality operations can be more easily scaled via the use of data quality management solutions that employ artificial intelligence and machine learning technology.
- AI/ML help to automate data quality operations, enabling the monitoring of more data at little or no additional cost.
What is Data Quality and Why is It Important?
All organizations run on the data they collect, and yours is no exception. If you collect inaccurate or incomplete data, your ability to run daily operations and engage in long-term planning is compromised. If you collect high-quality data, everything is easier – and you make more informed decisions.
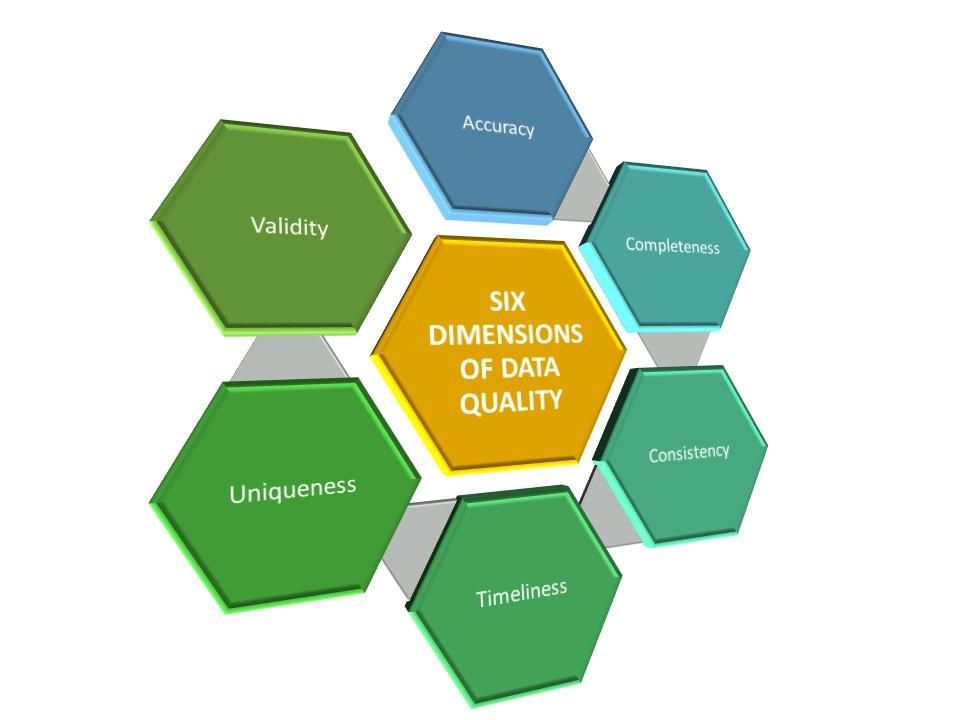
For data to be useful it must be of sufficient quality. Data quality is tracked in six key dimensions:
- Accuracy when compared to other known data
- Completeness, with no missing fields
- Consistency across multiple systems and across time
- Timeliness, as fresh data is typically more accurate than older data
- Uniqueness, so there is no duplication of data
- Validity, so that data is in the correct format
Data quality is important in providing accurate analysis and insights. It’s the old adage of “garbage in, garbage out;” bad data quality can lead to misinformed and possibly harmful decisions. Data quality is also important in eliminating data-related waste; you don’t want to send a mass mailing to a list where half the email addresses are invalid. The higher the data quality, the more effectively and efficiently you can run your business.
Unfortunately, bad data abounds and continues to affect organizations both large and small. According to a study of data quality published in the Harvard Business Review, only 3% of organizations had acceptable data quality. Almost half (47%) of recently created records had at least one critical error.
Why Scalability is an Issue in Data Quality Management?
To reduce the harmful effects of bad data, it’s essential to employ data quality management (DQM). DQM examines existing data, identifies issues such as missing fields or erroneous information, and then “cleans” the data by filling in missing fields, fixing inaccurate information, and removing unfixable or duplicative records. Equally important, new data is constantly monitored and cleaned in the same fashion, in real time.
The challenge comes as the amount of data used in your organization continues to increase. Data continues to accrue from a variety of traditional sources, including CRM, SAP, and ERP systems. An increasing amount of data is now arriving from IoT devices. This growing influx of data threatens to overwhelm current DQM systems based on manually created rules.
The data diversity—structured, unstructured, and semi-structured—adds another layer of complexity to maintaining high data quality at scale.
Traditional rule-based DQM methods struggle to keep pace with the increasing volume and complexity of data. Scaling these methods is resource-intensive, requiring manual interventions and expensive system upgrades.
Even if a DQM system can handle the increasing amount of data, the cost of doing so could become prohibitive. Currently, the cost of DQM scales alongside the amount of data monitored. The more data you receive the more it costs to manage and clean it. Scalability, then, is a significant issue in the world of data quality management.
How Can AI and ML Help Scale Data Quality Operations?
Existing DQM methods are simply insufficient for dealing with large volumes of unstructured or heterogenous data. The solution to efficiently scaling your data quality operations lies in artificial intelligence (AI) and machine learning (ML) technology.
Gartner predicts that by the end of 2022, 60% of all organizations will leverage ML in their data quality operations. That’s because AI and ML can “learn” your current rules regarding data quality and automate the process of identifying and fixing poor data. The technologies can also be trained to create new DQ rules based on your evolving data needs and sources.
The more DQ rules you have the harder it is to manually apply them. One of FirstEigen’s customers is a bank that was onboarding 400 new applications a year. With an average of four data sources per app and 100 checks per source, they needed to create 160,000 checks. That simply wasn’t feasible without the use of AI/ML-based automation; their existing system did not efficiently scale.
Investing in AI/ML DQM solutions, such as DataBuck, enables data quality operations to efficiently scale as the amount of data collected continues to grow. Without AI/ML, your organization runs the risk not only of increasing costs of managing data quality but also of having that data quality deteriorate.
(The following TED-Ed video explains how artificial intelligence learns.)
Challenges in Scaling Traditional Data Quality Approaches
As organizations grow, so does the complexity of their data landscape. Traditional DQM systems rely heavily on manual processes and predefined rules, which become inefficient and costly at scale. Such methods are not equipped to handle the large volumes of diverse and dynamic data organizations now deal with—from customer data to IoT device outputs.
This limitation creates operational bottlenecks and increases the risk of errors in decision-making. The manual creation and application of DQM rules cannot keep up with the rate at which data is generated and collected. AI/ML-based solutions address this by automating the learning and implementation of these rules, making scalability much easier.
Where AI/ML Are Used in Data Quality Management?
AI/ML technologies can be employed throughout the DQM process. As AI/ML systems learn more about your organization and your data they’re able to make more intelligent decisions about the data they manage. Consider the following:
- For data creation and acquisition, ML can auto-fill missing values and automate data extraction
- For data unification and maintenance, ML can correct inaccurate data, match data with existing data sets, and remove duplicate data
- For data protection and retirement, AI/ML can identify sensitive data for regulatory compliance, as well as detect possible fraudulent behavior
- For data discovery and use, AI/ML can make recommendations for new rules and link relevant data to provide new insights

By taking over formerly manual DQM tasks, AI/ML can handle increasing volumes of data without similarly increasing costs. This enables your organization to handle more and more diverse data and data sources without large additional system expenditures. Adding more data won’t overload the system – in fact, the more data sets the AI system has to analyze, the more and faster it will learn.
The Future of AI in Data Quality Management
Looking ahead, the integration of AI and machine learning into DQM will not only scale operations but also transform how organizations manage data altogether. In the future, AI systems will evolve to better understand the context of data within specific business processes, making quality management more intelligent and intuitive.
As AI technologies advance, organizations that invest in AI-driven Data Quality Management solutions will be better equipped to handle the exponential growth in data, ensuring that they remain agile and competitive in a data-driven world. AI and ML will be critical to unlocking new data insights, improving operational efficiency, and driving more accurate business outcomes.
Let DataBuck Help Scale Your Organization’s Data Quality Operations
When you need to scale your data quality operations to keep up with an increasing amount of incoming data, turn to DataBuck from FirstEigen. DataBuck is an autonomous data DQM solution powered by AI/ML technology that automates more than 70% of the data monitoring process. It can automatically validate thousands of data sets in just a few clicks and easily scale as your data needs increase. Contact FirstEigen today to learn how DataBuck can scale with your company’s data quality operations.
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQs
AI and machine learning (ML) improve data quality management by automating data validation, correction, and monitoring processes. Unlike traditional rule-based systems, AI/ML technologies can learn from data patterns, adapt to changing datasets, and predict potential quality issues before they become problems. These technologies enable organizations to scale their data quality operations efficiently, handling larger volumes of data without requiring manual intervention.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

The Power of Data Quality for AI Success
AI agents are only as reliable as the data they act on. As enterprises race to deploy AI, data quality has quietly become the deciding factor between success and costly failure. The Problem Nobody Is Solving Most AI conversations…

Mainframe Data Reconciliation for Cloud Migration
Cloud migration is no longer just an infrastructure decision. For data leaders and data engineers, it is a trust decision. …

What Do Failed AI Projects Have in Common?
Most AI failures are not model failures — they are data, governance, operational trust, and weak AI-ready foundations. “AI alone is not the solution – trusted, validated, continuously governed data is the…
Bad Data Is Costing You More Than You Think
