
Seth Rao
CEO at FirstEigen
The Essential Guide to Mastering Data Quality Monitoring
Data Quality Monitoring is vital for maintaining the accuracy, consistency, and reliability of your business data. As data flows through various systems, it can be prone to errors and inconsistencies that, if left unchecked, can impact decision-making, operational efficiency, and compliance.
Effective data quality monitoring involves continuous assessment using various techniques and tools to identify and rectify issues promptly. By implementing robust monitoring practices, businesses can ensure that their data remains a reliable asset, supporting strategic goals and improving overall performance. This guide will cover essential steps, techniques, and best practices for mastering data quality monitoring, helping you maintain high data standards in your organization.
What is Data Quality Monitoring?
Data quality monitoring is the practice of maintaining the accuracy, consistency, and reliability of information used in business processes. It involves regularly assessing data against predefined standards to promptly detect and address errors, ensuring robust data integrity.
Why Data Quality Monitoring is Crucial?
Data quality monitoring is crucial because it directly impacts decision-making, operational efficiency, and regulatory compliance. Reliable data is essential for accurate analytics, informed business decisions, and maintaining customer trust. Without proper monitoring, data errors can lead to costly mistakes and missed opportunities.
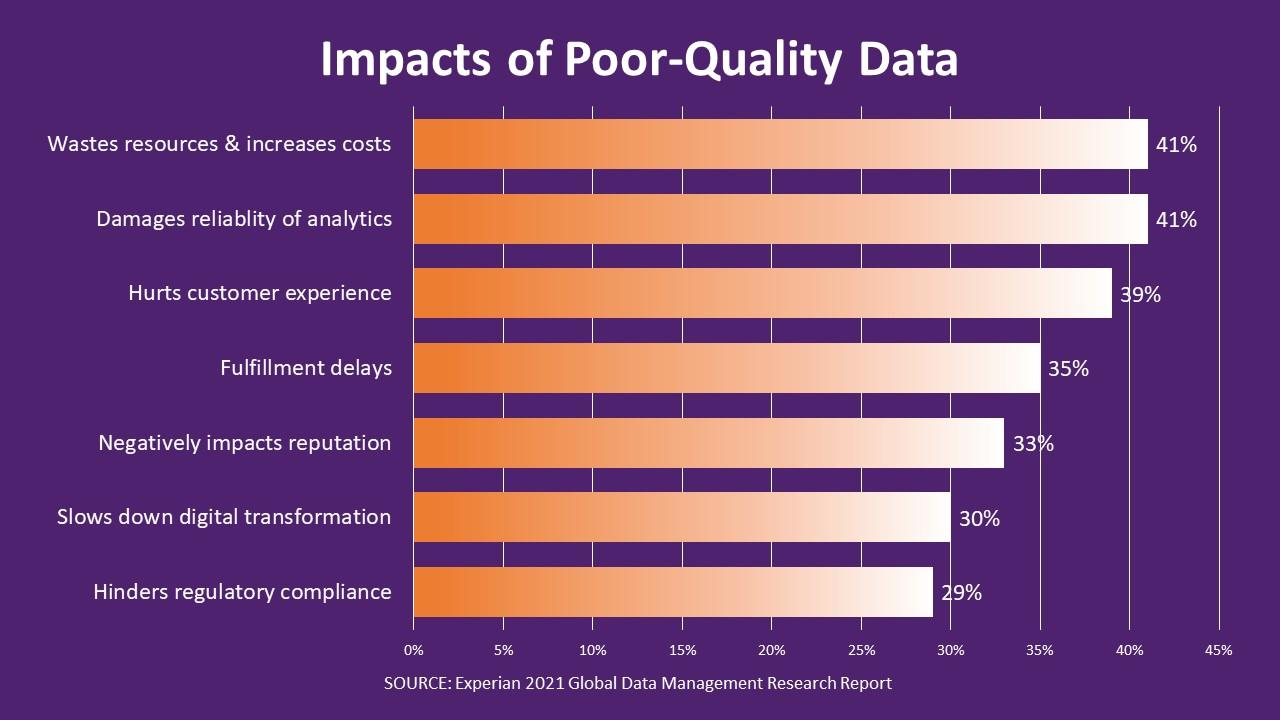
The Hidden Costs of Poor Data Quality
Poor data quality can lead to significant hidden costs, including failed analytics projects, non-compliance with regulations, and operational inefficiencies. Inaccurate data can cause incorrect decision-making, resulting in financial losses and damaged reputation. Companies may also face increased costs due to the need for additional data cleaning and correction efforts.
Unlocking the Benefits of a Robust Data Quality Monitoring System
- Improved Decision-Making: Ensures data accuracy and consistency, supporting strategic planning and daily operations
- Cost Reduction: Reduces operational costs by minimizing the need for extensive data cleaning and correction.
- Regulatory Compliance: Enhances compliance with regulatory standards by maintaining high data quality.
- Quick Issue Resolution: Helps in quickly identifying and rectifying data issues, and maintaining high data quality standards.
Exploring Types of Data Quality Monitoring
Different types of data quality monitoring are employed to ensure the integrity and reliability of data. These methods help in identifying and rectifying data issues promptly.
- Metadata-Driven AI-Augmented Monitoring: Utilizes AI to provide an overview of data quality across all data assets by automatically applying data quality rules and evaluating key dimensions like validity, completeness, and timeliness. This method is particularly useful for maintaining a high-level trust in your data catalog and is beneficial for analysts and business users alike.
- Precise/Targeted Data Quality Monitoring: Focuses on monitoring critical tables or specific attributes within a data warehouse or data lake. This method allows for more granular checks and is especially useful for regulatory reporting and other scenarios requiring detailed data quality assessments.
- AI-Powered Data Quality Monitoring: Employs AI to detect anomalies and patterns within data. This approach is effective for identifying unexpected issues or “silent problems” that traditional monitoring methods might miss. It continuously learns and improves based on user feedback, ensuring evolving data quality standards.
Key Metrics for Ensuring Data Integrity
Monitoring key data quality metrics is essential for maintaining high standards of data integrity. These metrics provide insights into various aspects of data quality, helping organizations to identify and address issues effectively.
- Accuracy: Measures how closely data values align with the true values. High accuracy is crucial for reliable decision-making and analytics.
- Completeness: Ensures that all necessary data is present. Missing data can lead to incorrect analyses and decisions, so completeness is a critical metric to monitor.
- Consistency: Assesses whether data is uniform across different systems and databases. Inconsistencies can cause confusion and errors in data interpretation and usage.
- Timeliness: Evaluate whether data is up-to-date and available when needed. Timely data is essential for making current and relevant decisions.
- Validity: Checks whether data conforms to the required formats and standards. Valid data is crucial for maintaining compliance and accuracy in data processing.
By focusing on these key metrics, organizations can maintain high data integrity, supporting reliable operations and informed decision-making.
Traditional Data Quality Monitoring Approaches
Traditional data quality monitoring approaches involve manual processes and rule-based methods to ensure data integrity. These methods have been foundational in the field of data management but come with certain limitations, especially in today’s dynamic data environments.
1. Conventional Data Quality Monitoring Practices
Conventional practices typically involve setting up predefined rules and manually checking data against these rules. This process often includes:
- Manual Data Validation: Writing SQL queries or using spreadsheets to validate data.
- Rule-Based Checks: Implementing rules for data consistency, completeness, and accuracy.
- Regular Audits: Periodic data audits to identify and correct issues.
While effective to some extent, these methods can be time-consuming and require significant human intervention.
2. In-Depth Monitoring at the Field Level
Field-level monitoring focuses on the smallest units of data within a dataset. This involves:
- Detailed Checks: Ensuring that each data field adheres to specific standards and formats.
- High Precision: Catching errors that broader checks might miss, such as incorrect data types or formatting issues.
- Data Quality Rules: Applying specific rules to individual fields to maintain high standards.
Field-level monitoring is crucial for industries where precision is paramount, such as healthcare or finance, but it can be labor-intensive and difficult to scale.
3. Comprehensive Monitoring at the Table Level
Table-level monitoring involves checking the overall structure and integrity of data tables. Key aspects include:
- Schema Validation: Ensuring that tables conform to the defined schema, with correct column types and relationships.
- Inter-Field Consistency: Verifying that related fields across rows and columns are consistent and accurate.
- Aggregate Checks: Using summary statistics and patterns to identify anomalies and errors.
This approach helps maintain the overall integrity of large datasets but may overlook field-specific issues.
4. Overcoming the Limitations of Narrow and Deep Monitoring
Narrow and deep monitoring methods, while thorough, often miss broader data quality issues due to their limited scope. Overcoming these limitations involves:
- Integrated Approaches: Combining field-level and table-level checks for a more holistic view.
- Automated Tools: Using automated data quality monitoring tools to scale the process and reduce manual effort.
- Continuous Monitoring: Implementing continuous data quality monitoring to catch issues in real-time and ensure ongoing data integrity.
5. How DataBuck Overcomes Monitoring Challenges?
DataBuck provides a modern solution to traditional data quality monitoring challenges by leveraging AI and automation. Key features include:
- Automated Rule Application: Automatically applying data quality rules across different datasets and environments.
- AI-Driven Anomaly Detection: Using AI to identify and learn from data anomalies, ensuring that unexpected issues are quickly addressed.
- Scalability: Enabling scalable data quality monitoring that can handle large volumes of data across multiple sources.
- Real-Time Insights: Offering real-time data quality monitoring dashboards to provide immediate visibility into data issues and their resolutions.
DataBuck simplifies the data quality monitoring process, making it more efficient and effective, and ensuring that your data remains accurate, consistent, and reliable.
Automate Your Data Quality Monitoring Today With DataBuck
The Necessity of Broad Metadata Monitoring
Broad metadata monitoring is essential for maintaining the overall health and reliability of data across an organization. It involves continuously tracking and analyzing metadata to ensure data quality, consistency, and compliance with governance standards. By monitoring metadata, organizations can gain a comprehensive view of their data assets, enabling better management and decision-making.
Metadata provides context to data, such as its origin, usage, and relationships with other data. Effective metadata monitoring helps in identifying discrepancies, managing data lineage, and ensuring that data meets organizational standards and regulatory requirements. It also supports the data quality monitoring process by highlighting potential issues that might not be immediately apparent through data content alone.
Achieving End-to-End Integration and Comprehensive Log Analysis
Achieving end-to-end integration and comprehensive log analysis is crucial for a robust data quality monitoring platform. This approach ensures that all data sources, transformations, and destinations are consistently monitored and evaluated for quality issues.
- End-to-End Integration:
- Data Integration: Combining data from various sources into a unified view, allowing for holistic monitoring and management.
- Data Lineage: Tracking data from its origin through all transformations and uses, which helps in understanding the data flow and identifying where issues may have occurred.
- Consistent Standards: Applying uniform data quality standards across all data sources and processes ensures that data remains reliable and accurate throughout its lifecycle.
- Comprehensive Log Analysis:
- Log Monitoring: Regularly analyzing logs from various systems and applications to detect anomalies, errors, and inconsistencies.
- Anomaly Detection for Data Quality: Using automated data quality monitoring techniques to identify unusual patterns that may indicate data quality issues.
- Real-Time Alerts: Implementing a data quality monitoring dashboard that provides real-time alerts for any detected issues, enabling prompt resolution.
Broad metadata monitoring combined with end-to-end integration and comprehensive log analysis creates a powerful framework for maintaining high data quality standards. Automated data quality monitoring solutions further enhance this framework by continuously scanning for issues and providing actionable insights.
What are the 3 Steps Processes of Data Quality Monitoring?
Simplifying the data quality monitoring process into three actionable steps ensures that organizations can maintain high data standards with minimal complexity. By focusing on efficient data ingestion, proactive issue identification, and effective data cleansing, businesses can ensure data reliability and accuracy.
Step 1: Efficient Data Ingestion
Efficient data ingestion is the foundation of effective data quality monitoring. This step involves:
- Data Integration: Combining data from various sources into a centralized repository. This process ensures that all data, regardless of its origin, is standardized and ready for analysis.
- Automated Data Quality Monitoring: Utilizing automated tools during the ingestion process to perform initial checks for consistency, accuracy, and completeness. This early intervention helps prevent errors from propagating through the system.
- Real-Time Data Processing: Implementing systems that allow for real-time data ingestion, ensuring that the most current data is always available for analysis and decision-making.
Efficient data ingestion sets the stage for high-quality data by ensuring that all incoming data meets predefined standards before it enters the system.
Step 2: Proactive Issue Identification
Proactive issue identification is crucial for maintaining continuous data quality monitoring. This step involves:
- Anomaly Detection for Data Quality: Using advanced algorithms and machine learning to detect anomalies and outliers in data. These anomalies can indicate potential errors or inconsistencies that need immediate attention.
- Data Quality Monitoring Techniques: Implementing various techniques such as data profiling and validation to identify issues before they impact the broader dataset.
- Automated Alerts: Setting up a data quality monitoring dashboard that provides real-time alerts when issues are detected. This allows for quick resolution and minimizes the impact on operations.
By identifying issues proactively, organizations can address data quality problems before they escalate, ensuring that data remains accurate and reliable.
Step 3: Effective Data Cleansing
Effective data cleansing is the final step in the data quality monitoring process, ensuring that any identified issues are resolved. This step includes:
- Data Standardization: Converting data into a consistent format across the dataset. This includes correcting errors, standardizing units of measure, and ensuring consistent data types.
- Data Deduplication: Identifying and removing duplicate records to ensure that each data point is unique and accurate.
- Validation and Correction: Using automated data quality monitoring solutions to validate data against predefined rules and correct any discrepancies found.
Effective data cleansing ensures that the dataset is free from errors and inconsistencies, making it reliable for analysis and decision-making.
Advanced Techniques for Data Quality Monitoring
To maintain high standards in data quality monitoring, advanced techniques must be employed. These techniques ensure that data remains accurate, consistent, and reliable across various business processes.
- Machine Learning for Anomaly Detection:
- Anomaly Detection for Data Quality: Machine learning algorithms can identify anomalies and patterns that traditional methods might miss. These anomalies can be indicative of errors, fraud, or other data quality issues.
- Continuous Improvement: Machine learning models can be trained and improved over time, adapting to new data and evolving to catch more sophisticated data quality issues.
- Automated Data Quality Monitoring:
- Automation Tools: Using automated tools and platforms reduces the manual effort involved in monitoring data quality. These tools can automatically apply data quality rules and check for consistency, completeness, and accuracy.
- Real-Time Monitoring: Implementing real-time monitoring ensures that data issues are detected and resolved as they occur, minimizing the impact on business operations.
- Data Quality Monitoring Dashboard:
- Visualization: Dashboards provide a visual representation of data quality metrics, making it easier to identify trends and issues.
- Customizable Alerts: Setting up customizable alerts in the dashboard ensures that stakeholders are immediately notified of any data quality issues, allowing for quick resolution.
- Data Profiling and Metadata Management:
- Data Profiling: Regularly profiling data helps to understand its structure, content, and relationships. This technique identifies anomalies, redundancies, and inconsistencies within the data.
- Metadata Monitoring: Monitoring metadata provides insights into data lineage, usage, and compliance with governance standards, ensuring that data remains reliable and trustworthy.
Best Practices for Maintaining Data Quality
Maintaining data quality is an ongoing process that requires adherence to best practices. These practices help ensure that data remains accurate, consistent, and fit for its intended purpose.
- Define Clear Data Quality Standards:
- Establish clear and consistent data quality standards that align with business objectives. These standards should cover all aspects of data quality, including accuracy, completeness, consistency, and timeliness.
- Implement Continuous Data Quality Monitoring:
- Adopt continuous data quality monitoring to ensure that data issues are detected and addressed promptly. This approach minimizes the risk of data quality degradation over time.
- Use Automated Data Quality Monitoring Solutions:
- Leverage automated data quality monitoring solutions to reduce manual intervention and improve efficiency. These solutions can perform routine checks, apply data quality rules, and generate real-time alerts for any issues detected.
- Regular Data Quality Audits:
- Conduct regular data quality audits to assess the effectiveness of existing data quality processes and identify areas for improvement. Audits help in maintaining compliance with governance standards and regulatory requirements.
- Data Stewardship and Governance:
- Assign data stewardship roles to individuals responsible for maintaining data quality. Implementing a robust data governance framework ensures accountability and continuous improvement in data quality practices.
The Future of Data Quality Monitoring Embraces End-to-End Data Observability
The future of data quality monitoring is moving towards end-to-end data observability, which provides a holistic view of the data landscape and ensures comprehensive monitoring and management.
- Integration of Data Quality Monitoring Techniques:
- Combining traditional data quality monitoring techniques with advanced methods such as AI and machine learning enhances the ability to detect and address data quality issues.
- Comprehensive Data Quality Monitoring Platform:
- A comprehensive data quality monitoring platform integrates various tools and techniques to provide a unified solution for monitoring and managing data quality. This platform should support data profiling, anomaly detection, and real-time monitoring.
- Real-Time Data Quality Monitoring:
- Implementing real-time data quality monitoring ensures that data issues are identified and resolved promptly, minimizing the impact on business operations.
- Data Observability for Proactive Management:
- Data observability goes beyond traditional monitoring by providing deeper insights into data health, lineage, and usage. It enables proactive management of data quality, ensuring that data remains reliable and fit for purpose.
- Advanced Analytics and AI:
- Utilizing advanced analytics and AI for data quality monitoring allows for the detection of complex patterns and anomalies. These technologies can predict potential issues and recommend corrective actions, ensuring continuous improvement in data quality.
By embracing end-to-end data observability, organizations can achieve a comprehensive and proactive approach to data quality monitoring, ensuring that their data remains a valuable asset for decision-making and operational efficiency.
Transform Data Quality Management With DataBuck’s AI-Powered Automation
Data quality monitoring is essential for ensuring the accuracy and reliability of your organization’s data. FirstEigen’s DataBuck provides an advanced, automated solution to streamline this process.
DataBuck automates over 70% of the data monitoring process using machine learning. Unlike traditional tools requiring manual rule writing, DataBuck auto-recommends essential validation rules, reducing time and effort in maintaining data quality.
Prevent Data Issues Before They Impact Your Business With Automated Monitoring
Key Features of DataBuck
- Automated Rule Recommendation:
- Baseline Validation: AI-driven recommendations for fundamental data quality checks.
- Custom Rules: Easily add custom rules for specific needs.
- High Security:
- Data Localization: Rules are applied where data is stored, maintaining security and compliance.
- User-Friendly Interface:
- Easy Edits: Non-technical users can modify validation checks through a simple UI.
- Scalability:
- Mass Validation: Validate thousands of datasets with a few clicks, allowing scalable data quality efforts.
Benefits of Using DataBuck
- Reliable Analytics and Reporting: Ensures data accuracy for trustworthy reports and models.
- Early Error Detection: Catches data errors early, reducing risks and costs.
- Cost and Effort Reduction: Automates monitoring, lowering maintenance costs and manual effort.
- Scalability: Scales data quality management without additional resources.
DataBuck addresses the limitations of traditional data validation methods by providing a scalable, secure, and user-friendly platform, ensuring your data remains reliable and supports your business goals efficiently.
Elevate Your Organization’s Data Quality With DataBuck by FirstEigen
DataBuck enables autonomous data quality validation, catching 100% of systems risks and minimizing the need for manual intervention. With 1000s of validation checks powered by AI/ML, DataBuck allows businesses to validate entire databases and schemas in minutes rather than hours or days.
To learn more about DataBuck and schedule a demo, contact FirstEigen today.
Check out these articles on Data Trustability, Observability & Data Quality Management-
- Differences Between Data Quality and Data Observability
- Data Quality Management: Framework and Metrics for Successful DQM Model
- 10 Common Data Quality Issues (And How to Solve Them)
- 6 Key Data Quality and Data Trustability Metrics You Should Automate on Azure and Snowflake
- The Importance of Data Quality for the Cloud and AWS
- The Role of ML and AI in Data Quality Management
FAQs
Data monitoring involves continuously tracking and analyzing data to ensure its accuracy, consistency, and reliability. It helps organizations detect anomalies, errors, and inconsistencies in real-time, enabling timely interventions.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

The Power of Data Quality for AI Success
AI agents are only as reliable as the data they act on. As enterprises race to deploy AI, data quality has quietly become the deciding factor between success and costly failure. The Problem Nobody Is Solving Most AI conversations…

Mainframe Data Reconciliation for Cloud Migration
Cloud migration is no longer just an infrastructure decision. For data leaders and data engineers, it is a trust decision. …

What Do Failed AI Projects Have in Common?
Most AI failures are not model failures — they are data, governance, operational trust, and weak AI-ready foundations. “AI alone is not the solution – trusted, validated, continuously governed data is the…
Bad Data Is Costing You More Than You Think
