
Seth Rao
CEO at FirstEigen
Data Pipeline Observability: What It is and Why It Matters
Data observability is the big buzzword these days, but do you know what it is or what it does? In particular, do you know why data observability is important for data pipelines?
You use a data pipeline to move data into and through your organization. You use data observability to ensure that your data pipeline is working as effectively and efficiently as possible. They are two synergistic concepts working together to deliver high-quality data to the people in your organization who need it.
Quick Takeaways
- A data pipeline moves data from various sources to the end user for consumption and analysis
- Data observability monitors the health of the data pipeline to ensure higher-quality data
- Data observability manages data of different types from different sources
- Data observability improves system performance
- Data observability provides more useful data to end users
What is a Data Pipeline?
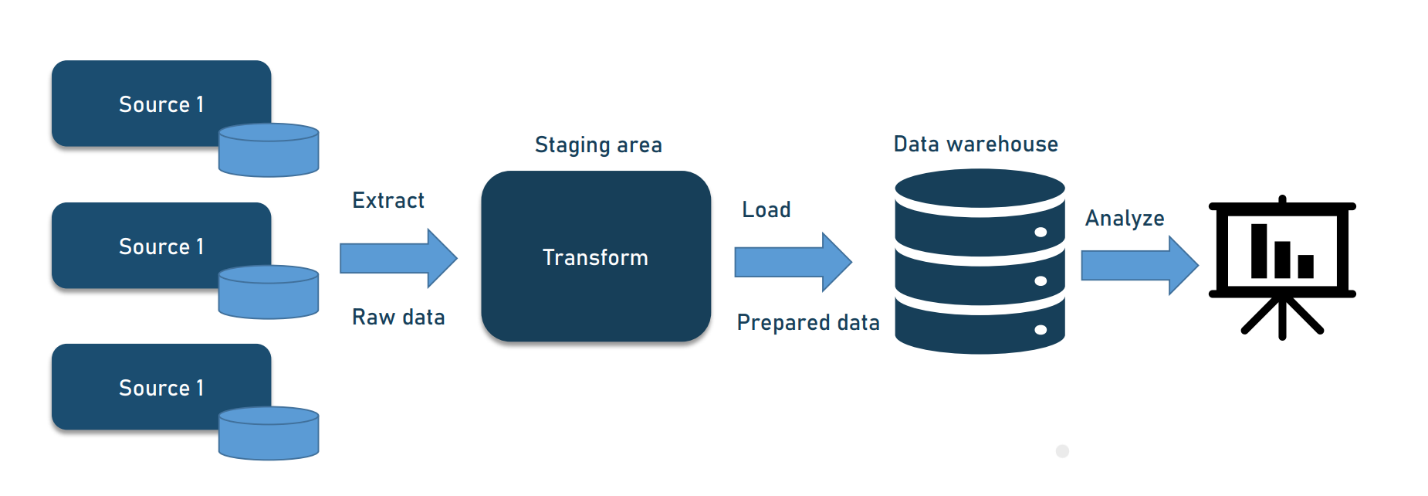
The world runs on data. According to current estimates, the average person creates 2.5 quintillion bytes of data every day—and a lot of that data flows into your company to use.
The flow of data into and through your organization is your data pipeline. Raw data enters your pipeline from various sources and transforms into structured data you can use for operations and analysis. The transformation and delivery of that data involve multiple processes, all part of the pipeline.
Unfortunately, data doesn’t always flow smoothly through the pipeline. Data ingested is often rife with errors and inaccuracies. Flaws in the pipeline itself can compromise even the cleanest data. For example, a pipeline can drop data when it gets out of sync, resulting in data leaks.
How can you ensure that your data pipeline does more good than harm and delivers the highest possible quality data? That’s where data observability comes in.
Key Features of Modern Data Pipelines
Modern data pipelines have evolved to meet the fast-paced demands of today’s business environment. Here are some of their most significant features:
- Real-Time Data Processing: Unlike traditional methods that delay insights, modern data pipelines offer continuous data ingestion and processing. This capability enables businesses to make swift decisions by reacting to trends as they happen—be it analyzing social media buzz or monitoring transactional data in near real-time.
- Scalability and Flexibility in the Cloud: The integration of cloud technology provides seamless scalability, enabling pipelines to handle variable data loads efficiently. This adaptability means companies can forgo hefty hardware costs, adjusting resources on-demand, and benefitting from enhanced performance and easy management across multiple locations.
- Streamlined Performance with Resource Segregation: By employing isolated processing clusters for different tasks such as transformation and analytics, modern pipelines eliminate performance bottlenecks. This resource isolation ensures every task achieves optimal speed and efficiency, allowing concurrent processing without contention.
- Empowered Data Access for Users: Modern data pipelines democratize data access by equipping users with intuitive, user-friendly tools. This reduces dependency on specialized data engineers and encourages business users to harness data through SQL-like interfaces, fostering a culture of self-service analytics.
- High Availability and Resilience: Built-in redundancy and failover mechanisms ensure that data remains available even during disruptions. These features reduce downtime risks, providing faster recovery times and minimizing potential financial penalties from lost data access.
- Data Integrity with Exactly-Once Processing: To prevent errors during data transfer, modern pipelines use advanced checkpointing techniques. These ensure that data events are captured accurately, avoiding duplicates or omissions, thereby maintaining data integrity.
- Efficiency Through Self-Service Management: With a suite of interconnected tools ranging from data integration platforms to data lakes, modern pipelines streamline the creation and maintenance processes. This self-service and automation reduce manual intervention, thereby simplifying ongoing operations.
These features collectively enable businesses to harness the full potential of their data, transforming it into actionable insights quickly and efficiently.
Understanding the Role of Deployment Monitoring Tools in Data Pipeline Observability
Deployment monitoring tools play a pivotal role in the landscape of data pipeline observability. These tools are crucial for ensuring smooth operations and pinpointing potential issues before they escalate.
- Enhancing Cloud Efficiency: Platforms designed for cloud environments integrate monitoring solutions that are highly specialized for their services. These solutions are essential for managing dynamic workloads, offering unmatched scalability and resilience. By leveraging these tools, businesses can enhance performance and ensure swift adaptation to ever-changing cloud conditions.
- Streamlined On-Premise Operations: For organizations that prioritize data sovereignty or adhere to stringent compliance standards, on-premise monitoring tools offer unparalleled control. These solutions can be finely tuned to meet the specific needs of a company’s network, ensuring robust data governance and tailored oversight.
- Batch Processing Oversight: In the realm of batch data, monitoring tools focus on maintaining the integrity and timing of batch jobs. They diligently track metrics such as job successes, failures, and latency, as well as flag discrepancies. This vigilance helps mitigate risks associated with delayed or inaccurate data, ensuring reliable and timely data flow.
By integrating these monitoring solutions, organizations can gain deep visibility into their data pipelines. This not only aids in preempting potential disruptions but also optimizes data movement and processing, ultimately driving better decision-making across the enterprise.
What is Data Pipeline Observability?
The Data Pipeline Observability refers to the ability to monitor, track, and analyze data as it flows through the pipeline, providing real-time insights into data quality, performance, and integrity. It involves collecting and analyzing data from various points in the pipeline to identify issues, optimize processes, and ensure data reliability.
Imagine a bustling city where data is the lifeblood, flowing through intricate networks like vehicles on busy streets. Each dataset, much like a vehicle, must reach its destination without delays or detours. This is the role of a data pipeline—ensuring smooth, efficient data movement from one point to another. However, the complexity of these pipelines, with multiple stages and potential bottlenecks, can lead to errors, inefficiencies, or data quality issues. This is where data pipeline observability becomes essential.
Observability dives deeper than traditional monitoring by providing a holistic view of the pipeline’s performance. It doesn’t just alert you when something goes wrong; it helps you understand why it went wrong by analyzing metrics, logs, and traces throughout the pipeline. This comprehensive visibility enables data teams to monitor each phase—from data ingestion to transformation and storage—ensuring that any issues can be swiftly identified and addressed.
For instance, consider a scenario where a data transformation process within the pipeline results in unexpected data anomalies. With observability, you can trace back through the logs and metrics to pinpoint the exact stage where the issue occurred, understand its impact on downstream processes, and take corrective action. This proactive approach helps maintain the pipeline’s health, ensuring it delivers consistent, high-quality data for decision-making.
What Is Data Observability?

Did you know that poor-quality data can cost your organization between 10% and 30% of its revenue? It’s a potential problem so large you can’t ignore it—which is where data observability comes in.
Data managers and engineers use data observability to make all the parts of the data system more visible. Unlike traditional data monitoring, which is concerned with improving the quality of data flowing through the system, data observability is concerned with the quality of the overall system. Data observability creates better systems that, indirectly, result in higher-quality data.
The 360-degree data view provided by data observability exposes potential issues affecting data quality. By monitoring the data flow in real-time, data observability can predict and plan for increased data loads, eliminating potential bottlenecks.
Data observability builds on the following five pillars:
- Freshness. Is the data as current as possible?
- Distribution. Does the data fall within an acceptable range?
- Volume. Are the data records complete?
- Schema. How is the data pipeline organized?
- Lineage. What is the status of the data as it flows through the pipeline? How Does Data Observability Work with a Data Pipeline?
Building on these five pillars, data observability can determine how effectively and efficiently a data pipeline works. It can also identify areas that aren’t working as well as others and propose solutions to improve pipeline quality and performance. By enhancing the pipeline itself, data observability improves the quality of the data flowing out of the pipeline.
Why is Data Pipeline Observability Important?
In today’s data-driven world, businesses rely heavily on data pipelines to extract, transform, and load data for analytics and decision-making. However, as data ecosystems grow more complex, ensuring the reliability and quality of data pipelines has become a critical challenge. This is where data pipeline observability comes into play.
Key Benefits of Data Pipeline Observability
- Enhanced Data Visibility: Data pipeline observability breaks down data silos and provides a unified view of the entire data ecosystem. It allows teams to track data movement, monitor pipeline performance, and ensure that data flows seamlessly across systems. This comprehensive visibility helps maximize the value of data in business intelligence (BI) and analytics workloads.
- Adapting to Data Changes: In a dynamic business environment, data sources and requirements can change frequently. Observability provides real-time insights into these changes, enabling teams to adjust data processes promptly and stay competitive.
- Proactive Issue Detection: Continuous monitoring of data pipelines helps detect anomalies and potential issues before they escalate. Data observability tools alert data teams to inconsistencies, schema changes, or data delays, allowing for quick resolution and minimizing downstream impact.
- Minimizing Data Downtime: Data downtime — periods when data is inaccurate, missing, or delayed — can disrupt critical business operations. Data observability reduces downtime by automating data quality checks and ensuring timely data availability, thereby boosting trust in analytical outputs.
- Driving Better Business Decisions: Organizations betting on data for strategic decision-making can’t afford data pipeline failures. Observability enables continuous data validation, supporting better business decisions by ensuring data reliability at every stage of the data lifecycle.
Ensure your data pipelines are always accurate, consistent, and trustworthy
Essential Monitoring Tools for Data Pipeline Observability
To achieve top-notch data pipeline observability, leveraging the right set of monitoring tools is essential. Here’s what you need:
- End-to-End Monitoring Platforms: These tools offer a complete overview of your data pipeline from start to finish, covering data ingestion, processing, and storage. They are crucial for ensuring seamless operation and quickly addressing any issues that arise.
- Real-Time Monitoring Solutions: If your data pipeline handles live, streaming data, real-time monitoring is indispensable. These tools provide instant alerts for any processing delays or irregularities, allowing for immediate corrective actions to maintain the flow and integrity of your data.
- Log Management and Analysis Tools: Vital for debugging and understanding your data flow, these solutions collect log data and perform in-depth analysis. They enhance your system visibility, allowing for quick problem identification and resolution.
- Performance Monitoring Tools: These focus on critical system metrics such as CPU load, network speed, and memory usage. Monitoring these areas provides insights into the overall health of your data pipeline infrastructure, enabling you to optimize and sustain peak performance.
- ETL Process Monitoring: Specifically designed for the Extract, Transform, Load (ETL) operations, these tools ensure that data transformations are accurate and complete. Rapid detection and resolution of issues during the ETL process help maintain data quality and consistency throughout the workflow.
Using these tools will give you a comprehensive toolkit for maintaining a robust and efficient data pipeline, ensuring that all components are well-monitored and optimized for peak performance.
Experience seamless data reliability and end-to-end pipeline observability
How Does Data Observability Work with Your Data Pipeline?
Think of data observability as a way to monitor the performance of your data pipeline. It works across the entire pipeline from beginning to end.
On the Front End
Data observability monitors and manages data health across multiple data sources at the beginning of the pipeline. Data observability allows you to ingest all structured and unstructured data types without affecting data quality.
One way data observability handles disparate data types is by standardizing that data. Data observability works with data quality management tools to identify poor-quality data, clean and fix inaccurate data, and convert unstructured data into a standard format that’s easier for your system to use.
Throughout the Pipeline
Throughout the entire pipeline, data observability monitors system performance in real time. Data observability tracks all aspects of your system performance, including:
- Memory usage
- CPU performance
- Storage capacity
- Data flow
By closely tracking data as it flows through the pipeline, data observability can identify, deter, and resolve any data-related issues that may develop. This helps to maximize system performance, which is essential when your system is ingesting and moving large volumes of data that can slow down more traditional systems.
Data observability tracks and compares large numbers of pipeline events and identifies significant inconsistencies. Focusing on these variances helps data managers identify flaws in the system that might impact the flow and quality of data in the pipeline. You can identify potential issues before they become debilitating problems, keeping the pipeline open and avoiding costly downtime.
On the Back End
Most users interact with your organization’s data at the end of the pipeline. Data observability creates a system that ensures clean and accurate data from which your users can gain the most value and insights.
In addition, data observability uses artificial intelligence (AI) and machine learning (ML) to track current system usage, redistribute workloads, and predict future usage trends. This helps you manage data resources, plan for future needs, and control IT costs. Data keeps flowing, no matter what, thanks to data observability.
Why Invest in Data Pipeline Observability?
As the analytics industry expands and data volumes grow exponentially, businesses must prioritize data reliability to remain competitive. Investing in data pipeline observability tools like FirstEigen’s DataBuck empowers data engineering teams to monitor pipeline transformations, diagnose issues quickly, and maintain stable, high-quality data flows. This leads to improved operational efficiency, enhanced data-driven decision-making, and greater business success.
By integrating advanced observability practices with FirstEigen, organizations can transform their data pipelines into a reliable backbone for all analytics and business intelligence initiatives.
How Can Organizations Choose the Right Toolset for Data Pipeline Observability?
Selecting the best data pipeline observability tool is a crucial task for any organization aiming to maintain smooth data operations. The decision should be guided by a deep understanding of your organization’s unique needs and constraints.
Key Considerations
- Scalability
- Evaluate whether the tool can grow with your data needs. A scalable solution is essential to manage increasing data volumes and complexity, ensuring it remains effective as your data operations expand.
- Visibility
- Ensure the tool provides comprehensive insights throughout all stages of your data pipeline. A clear view into the data flow helps in identifying potential bottlenecks and optimizing pipeline performance.
- Reliability
- Investigate the tool’s track record for consistent performance. Reliable tools help in pinpointing issues quickly, ensuring that your team can address them with minimal disruption to operations.
Proactive Problem-Solving
Beyond traditional monitoring, effective observability extends to the proactive identification and resolution of issues. Tools that support advanced analytics and predictive capabilities can significantly enhance your ability to manage and optimize data pipelines.
Balanced Approach
Consider a combination of tools if one does not fully meet your needs. Integrating various features and functionalities from multiple platforms can lead to a more robust and tailored observability strategy. Ensuring that your chosen tools integrate well with existing systems will also streamline the implementation process.
By carefully evaluating these factors, organizations can build a solid foundation for optimal data pipeline performance, leading to improved data operations and strategic insights.
Create a More Efficient Data Pipeline with DataBuck
Data observability improves your organization’s data flow and increases productivity. Data observability gives you a pipeline that provides more usable and higher-quality data.
You can enhance data observability for your data pipeline with DataBuck from FirstEigen. DataBuck is an autonomous data quality management solution powered by AI/ML technology that automates more than 70% of the data monitoring process. It can automatically validate thousands of data sets in just a few clicks and constantly monitor data ingested into and flowing through your data pipeline. Include DataBuck as part of your data observability and create a true data trustability solution.
Contact FirstEigen today to learn more about using data observability for your data pipeline.
Check out these articles on Data Trustability, Observability & Data Quality Management-
- Guide to Data Observability
- Data Observability for Data Lake, Warehouse, and Pipeline
- Data Testing Vs. Data Observability
- Data Observability Platform
- Data Observability for Data Lakes
- Differences Between Data Quality and Data Observability
- Data Pipeline Monitoring Services
- Data Pipeline Observability Tools
FAQs
Data pipeline observability refers to the process of monitoring, tracking, and analyzing data pipelines to ensure data quality, reliability, and operational efficiency throughout the data lifecycle.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

The Power of Data Quality for AI Success
AI agents are only as reliable as the data they act on. As enterprises race to deploy AI, data quality has quietly become the deciding factor between success and costly failure. The Problem Nobody Is Solving Most AI conversations…

Mainframe Data Reconciliation for Cloud Migration
Cloud migration is no longer just an infrastructure decision. For data leaders and data engineers, it is a trust decision. …

What Do Failed AI Projects Have in Common?
Most AI failures are not model failures — they are data, governance, operational trust, and weak AI-ready foundations. “AI alone is not the solution – trusted, validated, continuously governed data is the…
Bad Data Is Costing You More Than You Think
