
Seth Rao
CEO at FirstEigen
Data Testing or Data Observability: The Ultimate Guide to Data Quality Enhancement
Poor-quality data is a blight on every organization that depends on data to run its operations. Using inaccurate and incomplete data can affect operations and long-term strategic planning, lead to bad decisions, and make a company less competitive in the market. You can address the problem of poor-quality data through data testing and observability.
You can use data testing to identify and hopefully fix individual pieces of bad data and use data observability tools to ensure the integrity of your entire data system. When it comes to data testing vs. observability, both are essential.
Quick Takeaways
- Data testing looks at individual pieces of data for inaccuracies, incompleteness, and other flaws
- Data observability looks at the entire data pipeline for flaws that can affect all the data flowing through it
- Data testing differs from data observability in terms of coverage, scalability, focus, and speed
- Companies need both data testing and data observability to ensure the highest quality data possible
What is the Difference Between Data Testing And Data Observability?
Data Testing focuses on verifying the accuracy and validity of data at specific points in the pipeline. Data Observability, on the other hand, provides a holistic view of data quality by monitoring the entire data pipeline in real-time. While Data Testing checks for specific issues, Data Observability ensures continuous health and reliability across the data lifecycle, helping to quickly identify and resolve problems.
What is Data Testing?
Data testing tests the data flowing through a system to determine its quality. It’s a form of data monitoring, accomplished by conducting static tests for various indicators of data quality. Data that passes these tests is deemed high quality and usable. Data that doesn’t pass these tests can’t be used until it’s cleaned.
Data quality testing solutions test for a variety of issues, including:
- Null values
- Uniqueness
- Volume
- Distribution
- Known invariants
When a test identifies an issue, data flow is halted so that bad data doesn’t reach the end of the pipeline and pollute any analysis. Some poor-quality data can be cleaned by removing duplicates, correcting inaccuracies, filling in empty fields, and the like. Some poor-quality data cannot be cleaned, however, and must be deleted from the system. In no instance should poor-quality data be allowed to infect the higher-quality data in a system.
Data testing is essential for catching specific and identifiable problems in a dataset before the data is accessed by users.
What is Data Observability?
Data observability is different from data testing. Where data testing tests the data flowing through a pipeline, data observability monitors the data pipeline itself. Data observability is concerned with the quality of the entire system. The thinking is that better data systems should result in higher-quality data.
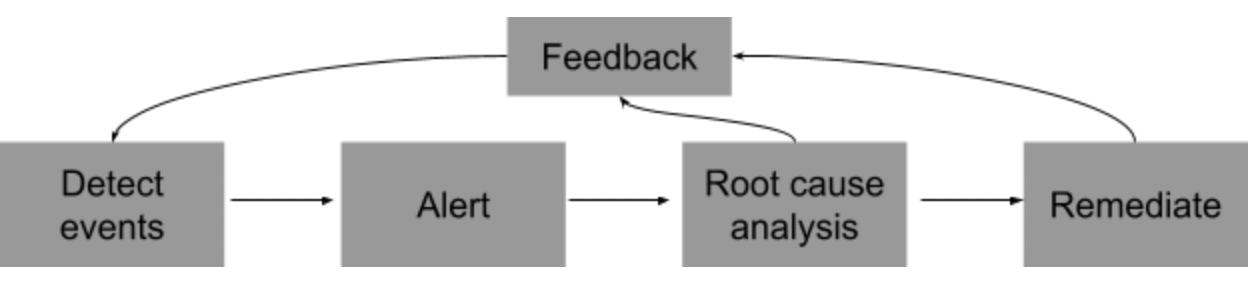
One of the benefits of data observability is that it identifies potential system issues that can impact data quality. Data observability solutions monitor real-time data flow, enabling data managers to prepare for increased data loads before the system becomes overloaded.
The so-called five pillars that buttress data observability include:
- Freshness – How current is the data?
- Distribution – Is the data within an acceptable range?
- Volume – How complete are the data records?
- Schema – Is the data system properly structured?
- Lineage – How are data assets connected throughout the pipeline?
Data observability builds on these five pillars to determine the effectiveness and efficiency of the data pipeline. It also pinpoints parts of the pipeline with subpar performance and suggests ways to improve the performance of the entire pipeline. And, by improving the pipeline itself, data observability improves the quality of all the data flowing through the pipeline.
Data Testing vs. Data Observability: What’s the Difference?
Data testing and data observability share the same goal to ensure the highest possible quality data. They just go about it in different ways.
Here, then, are the four primary ways that data testing differs from data observability.
Coverage
Data testing is typically applied in specific parts of the data pipeline, often near the beginning to test data flowing into the system. Data observability, in contrast, affects the entire pipeline, offering end-to-end coverage.
Scalability
Data testing is not easily scalable. To add more coverage, you have to add more tests, which is both costly and time consuming.
Data observability is more easily scalable. Most data observability systems incorporate machine learning (ML) so that the system learns from past data. This lets the system quickly adjust both to increased data flows and new types of data flowing into the system.
Focus
Data testing focuses on finding individual pieces of data of insufficient quality. Data observability focuses on the root causes of poor data quality. By fixing the root cause of a problem, data observability affects the quality of all data upstream and downstream from the issue.
Speed
Data testing works one step at a time – and it takes time to implement, maintain, and do its job. Data observability is more holistic, affecting more data in less time. It’s a faster solution, no matter how much data flows through the pipeline.
What Do You Need: Data Testing or Observability?
If you’re already testing or monitoring your data, do you also need data observability? The answer is an unqualified yes.
The issue is that bad data is unusable and, if used, can misinform those in the organization trying to use that data. The costs of bad data are real and large. It affects 88% of all companies, costing the typical organization an average of $15 million a year.

Data testing is essential in fighting this problem. Data quality testing helps you identify bad data in your system so that you can isolate it and either fix or delete it. Without data testing, that bad data will infect your entire system.
Data observability doesn’t do that. It doesn’t focus on individual pieces of data. Instead, it looks at the functioning of the entire system. By optimizing the entire data flow, the quality of all data is improved.
Data observability is like the tide that raises all boats, while data testing tries to identify leaky boats before they sink, one vessel at a time. They both have their place in the fight against poor data quality.
Elevate Your Organization’s Data Quality with DataBuck by FirstEigen
DataBuck enables autonomous data quality validation, catching 100% of systems risks and minimizing the need for manual intervention. With 1000s of validation checks powered by AI/ML, DataBuck allows businesses to validate entire databases and schemas in minutes rather than hours or days.
To learn more about DataBuck – contact FirstEigen today.
Check out these articles on Data Trustability, Observability & Data Quality Management-
- Guide to Data Observability
- Data Observability for Data Lake, Warehouse, and Pipeline
- Data Observability Platform
- Data Observability for Data Lakes
- Data Observability for Data Pipelines
- Differences Between Data Quality and Data Observability
- Difference Between Observability and Monitoring
- Cloud Leak Prevention Solutions
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

The Power of Data Quality for AI Success
AI agents are only as reliable as the data they act on. As enterprises race to deploy AI, data quality has quietly become the deciding factor between success and costly failure. The Problem Nobody Is Solving Most AI conversations…

Mainframe Data Reconciliation for Cloud Migration
Cloud migration is no longer just an infrastructure decision. For data leaders and data engineers, it is a trust decision. …

What Do Failed AI Projects Have in Common?
Most AI failures are not model failures — they are data, governance, operational trust, and weak AI-ready foundations. “AI alone is not the solution – trusted, validated, continuously governed data is the…
Bad Data Is Costing You More Than You Think
