
Seth Rao
CEO at FirstEigen
Data Mesh vs Data Lake: Understanding Key Architecture Differences, Benefits, and Trustability
Data Lake relies on a centralized data repository, while Data Mesh decentralizes data storage and management.
It’s a war between different philosophies of data architecture, but your organization will eventually have to choose sides. So which is better for your business? Which is better for quick decisions and which is better for more reliable and trustable data?
Quick Takeaways
- A data mesh decentralizes data storage and management across an organization
- A data lake consolidates all data into a single, centrally managed repository
- Data meshes enable speedier data analysis and are easier to scale
- Data lakes are better for handling large amounts of raw data and are easier to secure
- In both Data Mesh and Data Lake, Data Trust issues are best addressed way upstream and also validated throughout the pipeline
What is a Data Mesh?
Where data lakes are monolithic storehouses for data, a data mesh takes the opposite approach. Instead of centralizing data storage, a data mesh decentralizes data, dispersing it – or, more accurately, generating or ingesting it – in multiple connected nodes. It’s the mirror image of the old client/server model, with every node becoming both a client and a server, enabling all nodes to store, share, and access data from across the organization.

A data mesh is especially useful for large enterprises that generate lots of data, as well as large-scale applications that run across multiple organizations. It’s, at least in theory, an easier way to manage data in complex environments.
In a data mesh, each department or location becomes its own data domain, server, and data platform. Each domain is responsible for gathering, storing, and managing its own data. Data is served from each domain to the other domains in the mesh and shared across the organization. This gives business teams and departments complete ownership and control of their data, which can result in speedier data access and faster decision-making.
What is a Data Lake?
A data lake is a central location that stores data of all types and in all formats. It’s a traditional way to store data, by gathering it all in one easily managed and accessed location. Data in a data lake can come from multiple sources, both inside and outside an organization.
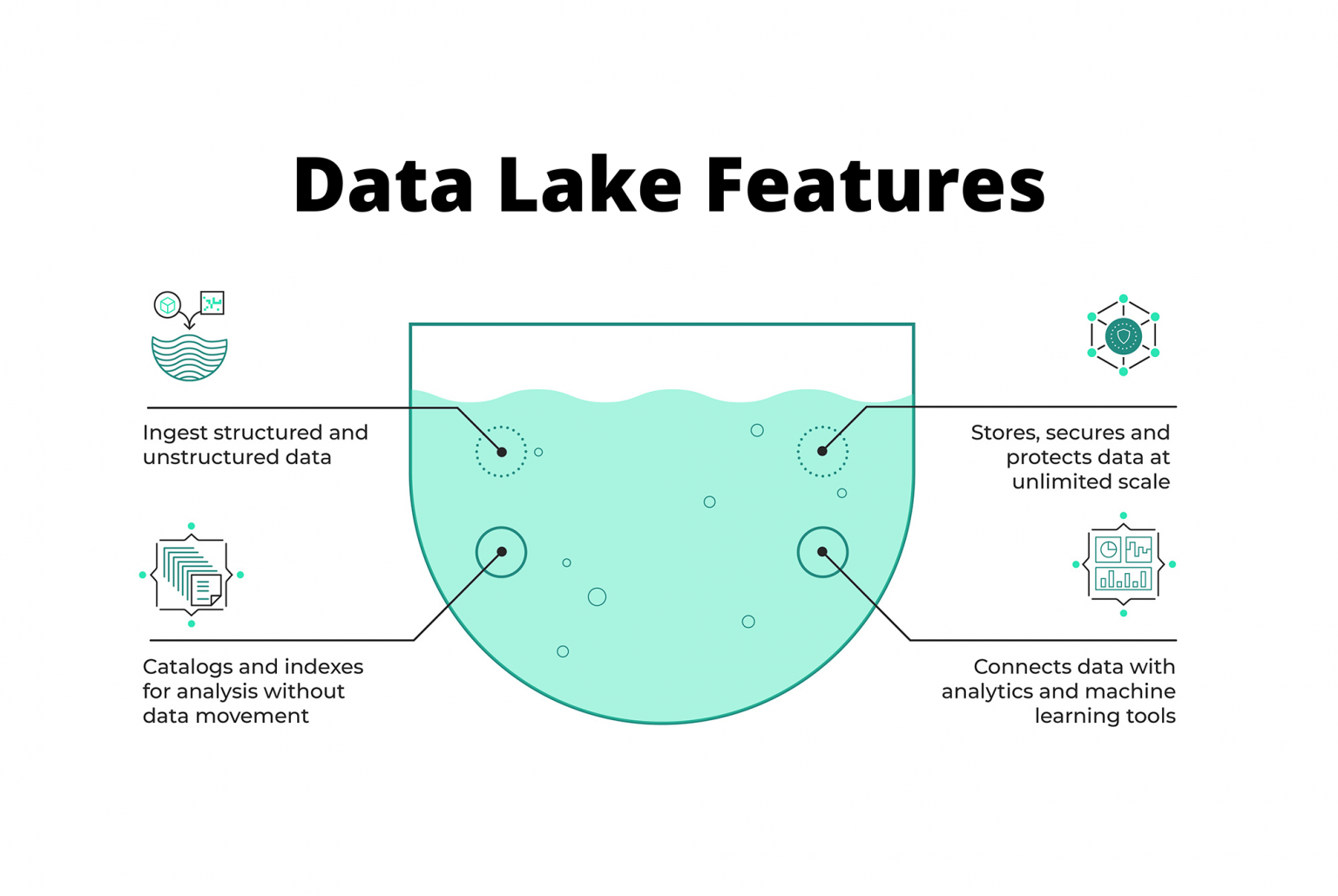
Data is ingested into the data lake from both internal and external sources. This data is seldom in a single standardized format and can be both structured and unstructured. This requires data managers to develop processes and technologies to catalog and index the data so that users can access it. This typically involves the use of artificial intelligence (AI) and machine learning (ML) technologies.
Data lakes offer many advantages to the average organization. Data lakes are:
- Relatively simple to construct and manage
- Cost-effective for storing large amounts of data
- Familiar to most IT workers
- Compatible with a wide variety of data quality and data management tools
- Easy to access by both in-office and remote workers
- Easy to secure against breaches and attacks
The key characteristics of data lakes are that they are both singular and centralized. Companies build data lakes to eliminate departmental and geographic data silos that are more difficult to access, manage, and defend.
Data Mesh vs. Data Lake: How They’re Different
Data lakes and data meshes take opposing approaches to storing and disseminating data. A data lake centralizes data whereas a data mesh decentralizes it. They are, in both design and execution, different methods of data architecture.
For the past several decades, enterprises have gravitated towards centralized data storage, whether in old-school databases or more contemporary data warehouses and data lakes. Companies discovered that multiple data silos were more difficult to manage and secure against outside intrusion, which became more important as the number and severity of cyberattacks and breaches ballooned over time. (According to Statista, the number of data compromises in the U.S. grew from 157 in 2005 to more than 1,800 in 2021.) In addition, the growth of the remote workforce over that same time period led companies to create an easily accessible single source of data stored in the cloud.
As a result of these and other trends, centralized data repositories, often in the form of data lakes, became the norm. The global market for data lake solutions and services almost doubled from $1.9 billion in 2016 to $3.74 billion in 2020 and is expected to reach $21.82 billion by 2030.
Benefits of Data Mesh
The winds are starting to shift again, however, as many companies realize the benefits of decentralized data distributed over a mesh. A data mesh can do the following:
- Be easily managed at a local level
- Scale more easily and cost-effectively than a data lake
- Enable decentralized organizations to better manage dispersed data
- Allow individual locations to store and analyze data unique to their operations more easily
Benefits of Data Lakes
Data lakes offer a different set of benefits to organizations. A data lake can do the following:
- Break up data silos and make all data visible and equally accessible to all employees
- Assemble all of the enterprise’s data to provide more inclusive and comprehensive analysis and insights
- Use IT resources more efficiently by eliminating duplicative efforts
- Create a centralized repository that’s easier to secure against outside attackers
Data Mesh vs. Data Lake: Which Should You Choose for Your Company’s Data?
Given the differences between the two approaches to data architecture, which is better for your organization: a data lake or a data mesh? It depends on what you need.
Choose a data mesh if:
- You need real-time reporting and analysis
- You have multiple disconnected systems, especially in disparate locations
- You need to quickly grow your data management operations
- You need to rapidly scale your operations
- You want the power to monitor Data Trustability at a local level as your requirements may be special
Choose a data lake if:
- You own large amounts of raw data
- You have both structured and unstructured data
- You want to reduce data storage and management costs
- You want to store your data in the cloud
- You want to establish Data Trustability upstream so the data cascading downstream has basic essential hygine and trust that more groups can easily “drink” from
Then there’s a third approach: combine data lakes and a data mesh into a single solution. This approach involves creating separate data lakes in multiple locations or departments but joining them together in a mesh network. For many organizations, this may be the best of both worlds.
Clean Up Both Data Lakes and Data Meshes with DataBuck
Data lakes and data meshes are both prone to frequent data errors. When even the most diligent companies monitor less than 5% of their data, large quantities of unmonitored and unreliable data find their way into centralized and decentralized data storage.
Whether your company uses a data lake or a data mesh, to get the most value out of your data, you need to monitor Data Trustability.
FirstEigen’s DataBuck is an autonomous, low-code, data trustability monitoring solution that uses machine learning to monitor your data in real time. You get higher-quality data, which lets you make more informed operating and strategic decisions. Let DataBuck monitor your data mesh or data lake and turn bad data into good data.
Contact FirstEigen today to learn more about data quality in data lakes and data meshes.
Check out these articles on Data Trustability, Observability & Data Quality Management-
- 6 Key Data Quality Metrics You Should Be Tracking
- How to Scale Your Data Quality Operations with AI and ML?
- 12 Things You Can Do to Improve Data Quality
- How to Ensure Data Integrity During Cloud Migrations?
- Data Infrastructure Strategy
- Observability vs Monitoring
- Data Quality vs Data Reliability
- Data Mesh Principles
FAQ
A Data Lake is a centralized repository where large volumes of structured and unstructured data are stored in their raw format. It offers scalability but can lead to bottlenecks in data management and governance. On the other hand, a Data Mesh is a decentralized architecture where data ownership is distributed across domain teams, making them responsible for managing and governing their data. While Data Lakes focus on centralization, Data Mesh focuses on autonomy and governance across different teams.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

The Power of Data Quality for AI Success
AI agents are only as reliable as the data they act on. As enterprises race to deploy AI, data quality has quietly become the deciding factor between success and costly failure. The Problem Nobody Is Solving Most AI conversations…

Mainframe Data Reconciliation for Cloud Migration
Cloud migration is no longer just an infrastructure decision. For data leaders and data engineers, it is a trust decision. …

What Do Failed AI Projects Have in Common?
Most AI failures are not model failures — they are data, governance, operational trust, and weak AI-ready foundations. “AI alone is not the solution – trusted, validated, continuously governed data is the…
Bad Data Is Costing You More Than You Think
