
Seth Rao
CEO at FirstEigen
How to Build Data Infrastructure: Strategies and Platforms for a Robust System
Building a robust data infrastructure is essential to survive in today’s ultra-competitive environment. Do you know how to create an efficient and effective data infrastructure? There are several vital steps to take, starting with defining your data strategy and cleaning your data for the highest possible data quality.
Quick Takeaways
- A robust data infrastructure enables secure and efficient data consumption
- Building a robust data infrastructure requires defining your data strategy, building a data model, choosing a data repository, cleaning and optimizing the data, building an ETL pipeline, and implementing detailed data governance
- The amount of data, its accessibility, and its quality make maintaining data infrastructure a challenge
What is a Data Infrastructure?
Technopedia defines data infrastructure as a type of digital foundation that enables the sharing and consumption of data. A robust data infrastructure includes several key elements, including:
- Data ingestion
- Data storage
- Data security
- Data retrieval
- Data analysis
The right data infrastructure enhances employee productivity and collaboration while enabling easy yet secure access to key data. The appropriate data infrastructure should reduce an organization’s operational costs while increasing employee efficiency.
Why Do We Need Data Infrastructure?
In today’s data-driven world, businesses generate and use vast amounts of information. A robust data infrastructure helps organizations:
- Ensure Reliable Decision-Making: Accurate data supports informed strategies.
- Enhance Collaboration: Unified data systems prevent silos and foster teamwork.
- Improve Data Security: Protect sensitive information with built-in safeguards.
- Support Scalability: As data volumes grow, infrastructure ensures continued efficiency.
- Ensure Regulatory Compliance: Align with GDPR, HIPAA, and other standards.
Without proper infrastructure, organizations struggle with disorganized, inaccessible, or low-quality data, hampering overall performance.
Eliminate 80% of Manual Checks with Automated Data Monitoring
Key Steps for Building a Robust Data Infrastructure
Building a robust data infrastructure involves six key steps – starting with defining your overall data strategy.
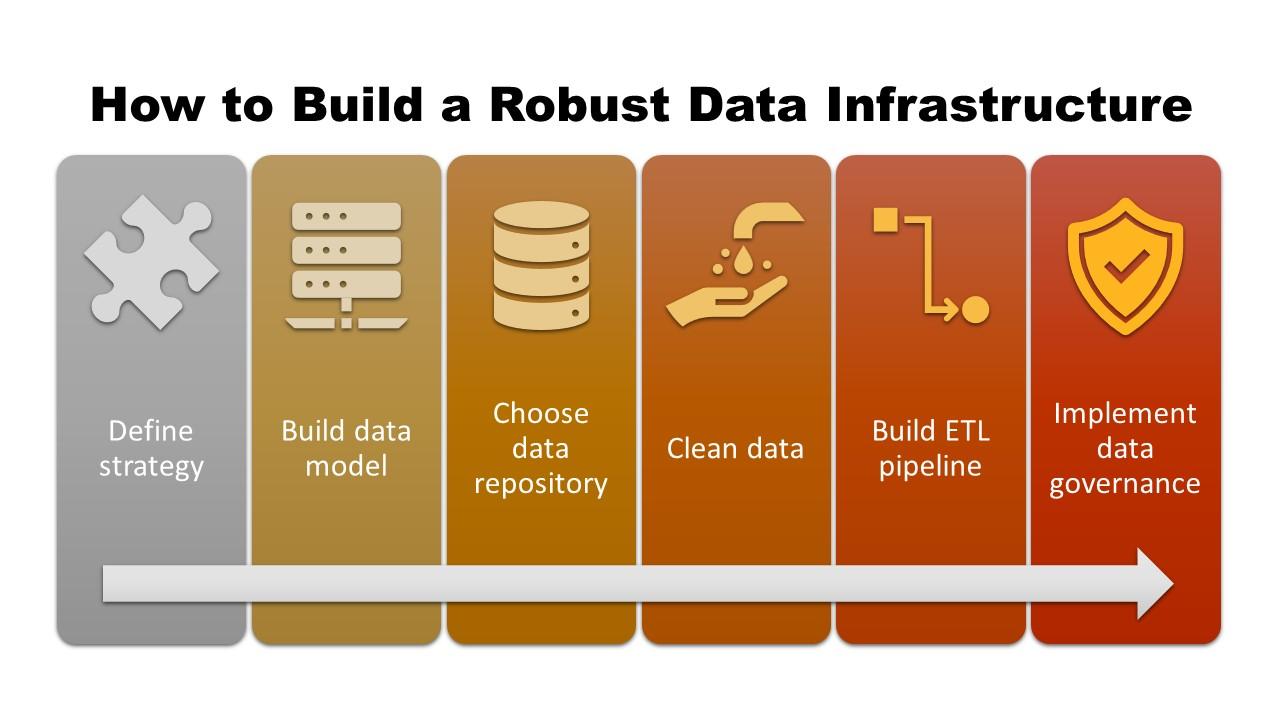
1. Define Your Data Strategy
The first step in establishing a robust data infrastructure is determining your organization’s needs. This typically involves performing a detailed data audit, where you identify:
- What data you collect
- Where that data comes from (different systems and databases)
- What form the data currently exists in (structured vs. unstructured, etc.)
- How the data is currently secured
- Who needs access to that data – and why
This information will help you define your overall data strategy and guide you through the remaining process of building your new data infrastructure.
2. Build a Data Model
The data model defines how your data will be structured and will reflect the type of data you create and ingest and how that data will be used. There are three types of data models in which you may engage:
- Conceptual, which defines high-level business structures and operations
- Logical, which defines different classes of data, their attributes, and the relationships between them
- Physical, which defines internal database tables, columns, and other schema
Your organization may work exclusively with one data model or utilize all three in successive project stages.
3. Choose a Data Repository
Not only do you have to define your data structure, but you also need to decide what type of data repository to use and where to house it.
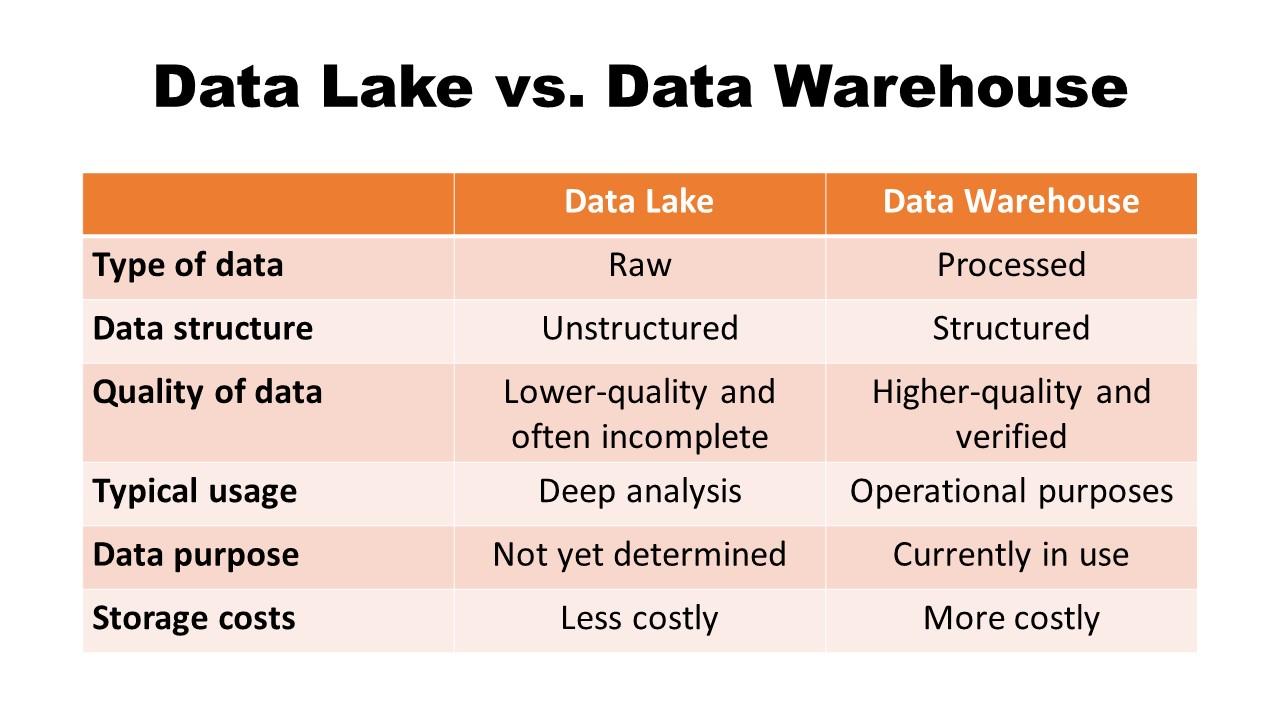
There are three primary types of data repositories you can choose from:
- Data lake, typically used to store raw, often unstructured data
- Data warehouse, typically used to store structured and filtered data
- Hybrid approach, which includes elements of both a data lake and a data warehouse
You also need to determine whether you’re going to host your data repository on-premises, on your servers, or in the cloud at a cloud-hosting service. While on-premises data storage puts the entire operation under your internal control, it isn’t as flexible as cloud-hosted storage, enabling easier and more secure remote access. It’s not surprising that 50% of all enterprise data is currently stored in the cloud.
4. Clean and Optimize Your Data
If you choose to create a data warehouse, you need to clean and optimize the data as it is ingested into the structured database. If you create a data lake, you need to clean and optimize data as it is retrieved. In either case, data quality management software is essential to ensure that the data you ultimately use is accurate, complete, and up-to-date.
The more data you manage, the more difficult this process becomes, which is why many organizations utilize automated data monitoring tools, such as FirstEigen’s DataBuck. This tool monitors data not just during ingestion but throughout the data lifecycle to eliminate errors from being introduced and ensure more usable data.
5. Build an ETL Pipeline
Moving data from other systems into the data warehouse or data lake involves the extract, transform, and load (ETL) process. The ETL process is where a standard structure is imposed on your data, making it more organized and ultimately more accessible.
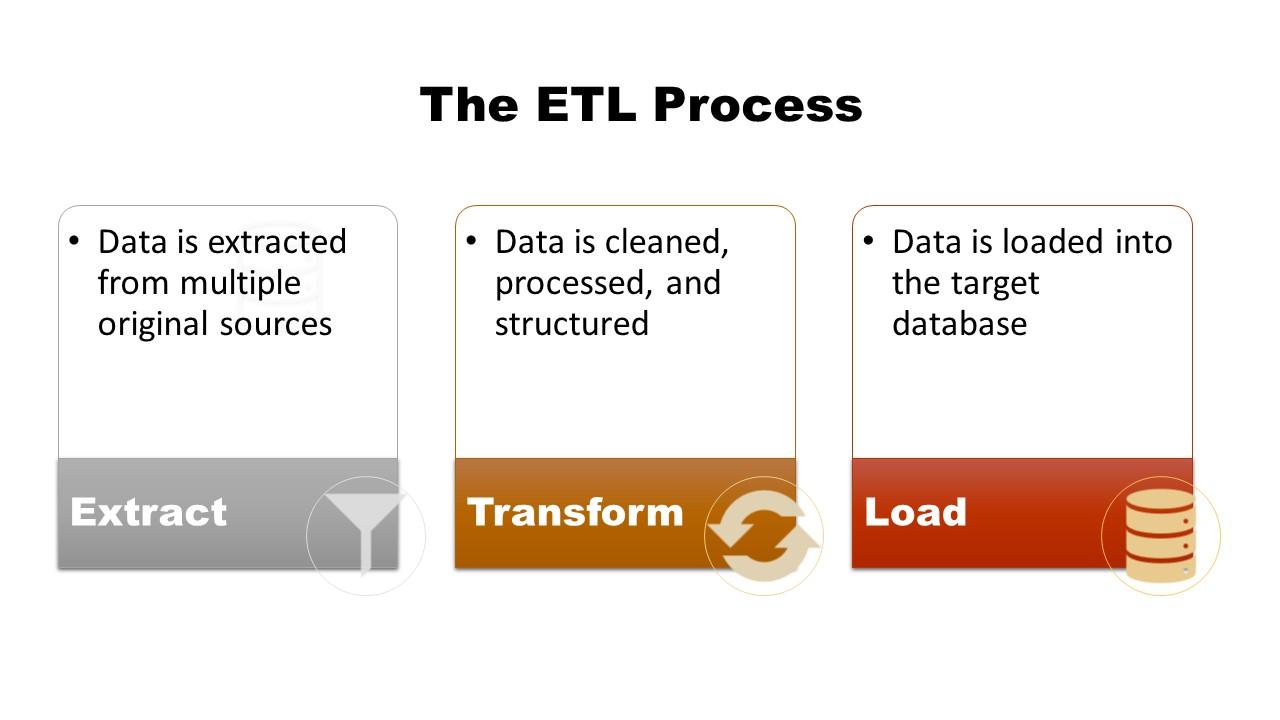
The ETL process works like this:
- Data is extracted from multiple sources – CRM systems, data lakes, other databases, etc.
- Data is transformed and processed into the standard data model
- Data is loaded into the target database
Your ETL pipeline must be secure against data leaks that affect the quality of data feeding into the ultimate data repository. Losing just 0.25% of the data transferred can affect the quality of later analysis.
6. Implement Data Governance
Once the data is loaded into your infrastructure, you need to implement detailed data governance that defines how that data is managed and controlled. A data governance framework typically deals with the following issues:
- Data quality
- Data availability
- Data usability
- Data integrity
- Data compliance
- Data security
Proper data governance results in numerous benefits to the organization, including:
- Improved compliance
- More consistent operations
- Enhanced security
- Defined audit trail
- Improved disaster recovery
Challenges for Building and Maintaining Data Infrastructure
Every organization faces some key challenges when building and maintaining a data infrastructure. These challenges can be overcome with the right data management solution but must be addressed proactively.
1. Data Volume
Businesses today generate an overwhelming amount of data. According to IDC, the amount created each year increased from 15.5 ZB in 2015 to 64.2 ZB in 2020. That number is expected to increase by 23% a year through at least 2025.
Dealing with all this data is a tremendous challenge. The more data your organization creates, the bigger the strain on your data infrastructure. It’s a significant challenge for your IT staff not to get buried under this ever-growing flow of data.
2. Data Accessibility
The more data you collect, the more difficult it is to find and retrieve specific content, especially if it is not properly stored and organized. Data that is siloed in different parts of an organization can be hidden from employees who need to use it. Data that is improperly labeled or filed can be almost impossible to find. With so much data coursing through your organization, finding that one document you need is often like searching for a needle in a haystack.
3. Data Quality
Even properly stored and organized data loses its value if it isn’t of high enough quality. According to Gartner, 20% of all data is compromised because of its poor quality, rendering it unusable.
To provide the most benefit to an organization, data must be:
- Accurate
- Complete
- Consistent
- Timely
- Unique
- Valid
This is true of newly created data, and data from other sources ingested into an existing data infrastructure – and is why data quality management needs to be a part of a robust data infrastructure solution.
Future Trends in Data Infrastructure
To future-proof your data infrastructure, consider these emerging trends:
- AI and ML Integration: Automating data quality checks and analytics.
- Edge Computing: Enhancing real-time data processing at the source.
- Data Fabric: Connecting disparate data sources for a unified view.
- Blockchain: Securing data sharing with immutable records.
Discover How DataBuck Reduces Data Errors by 90%
Let DataBuck Help You Build a Robust Data Infrastructure
High-quality data is essential to the usability of any data infrastructure. When you need to ensure the highest possible data quality, turn to DataBuck from FirstEigen. DataBuck is an autonomous data quality management solution that automates more than 70% of the data monitoring process. Our data management system ensures that the contents of your data infrastructure are complete, accurate, and timely.
Contact FirstEigen today to learn how you can use DataBuck in your data infrastructure plans.
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQ
Data infrastructure is the system and tools that manage and process data within an organization. It includes hardware, software, networks, and protocols that store, retrieve, and analyze data, ensuring it’s accessible and usable for decision-making.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

The Power of Data Quality for AI Success
AI agents are only as reliable as the data they act on. As enterprises race to deploy AI, data quality has quietly become the deciding factor between success and costly failure. The Problem Nobody Is Solving Most AI conversations…

Mainframe Data Reconciliation for Cloud Migration
Cloud migration is no longer just an infrastructure decision. For data leaders and data engineers, it is a trust decision. …

What Do Failed AI Projects Have in Common?
Most AI failures are not model failures — they are data, governance, operational trust, and weak AI-ready foundations. “AI alone is not the solution – trusted, validated, continuously governed data is the…
Bad Data Is Costing You More Than You Think
