
Seth Rao
CEO at FirstEigen
9 Key Factors to Ensure Data Reliability & Improve Accuracy
Do you know how to improve the reliability of your company’s data? Data reliability affects how you run your business. Unreliable data can lead to poor business decisions and difficulty running your company’s day-to-day operations. It is in your company’s best interest to improve data reliability—and here are nine ways to do it.
Quick Takeaways
- Reliable data is necessary for organizations to make accurate and informed decisions
- To improve data reliability, start by assessing your current situation and then build a robust data infrastructure
- You need to clean existing data and then analyze and optimize new data creation and collection
- Data reliability improves when you break down data silos, integrate apps, organize your data, and employ robust reporting and dashboards
What is Data Reliability?
Data reliability ensures that data remains accurate, consistent, and trustworthy across its lifecycle. It guarantees that the same dataset yields identical results under similar conditions. Reliable data is essential for businesses to make informed decisions, optimize operations, and maintain compliance. Without reliable data, decision-makers face uncertainty and risks that could harm their business outcomes.
Why is Data Reliability Important?
Reliable data is complete, accurate, properly formatted, and up to date. Businesses rely on high-quality data to:
- Monitor day-to-day operations
- Drive revenues
- Reduce costs
- Improve operational efficiency
- Make better-informed strategic decisions
Unreliable data can cost a business in many ways. Experts estimate that between 60% to 85% of all business initiatives fail because of poor quality data. There’s a real cost to unreliable data; Gartner reports that poor data quality costs the average organization between $9.7 million and $14.2 million each year.
Reliable data helps decision-makers take the guesswork out of the day-to-day and strategic decisions they have to make to keep their businesses running. Without reliable data, those same decisions become more tenuous and less accurate, ultimately affecting the success of the business.
What Are the Benefits of Data Reliability?
Reliable data offers businesses:
- Accurate Decision-Making: Empower leaders to make data-driven decisions without second-guessing data integrity.
- Improved Efficiency: Reduce operational disruptions caused by incorrect or incomplete data.
- Cost Savings: Avoid the costs associated with fixing bad data or correcting errors in analytics.
- Regulatory Compliance: Ensure adherence to industry regulations and avoid penalties by maintaining accurate records.
- Enhanced Customer Insights: Understand customer behaviors and preferences more accurately for better targeting.
Common Challenges in Achieving Data Reliability
- Data Silos: Isolated systems and databases lead to fragmented data that is hard to integrate.
- Data Duplication: Duplicate records inflate costs and create inconsistencies.
- Lack of Standardization: Disparate formats and inconsistent data make analysis difficult.
- Manual Processes: High manual intervention increases the risk of human error.
- Scalability Issues: Legacy systems often struggle to handle growing volumes of data.
Use Cases to Solve With Data Reliability
Reliable data addresses various challenges across industries:
- Finance: Detect fraudulent activities by monitoring transaction data for anomalies.
- Healthcare: Improve patient outcomes by maintaining accurate medical records.
- Retail: Optimize inventory management with consistent sales data.
- Regulatory Compliance: Ensure clean and auditable records for reporting purposes.
- Manufacturing: Use accurate machine data to prevent equipment failures through predictive maintenance.
Data Reliability vs. Data Validity
Both reliability and validity are essential for high-quality data, but they serve different purposes:
- Data Reliability: Ensures data remains consistent and repeatable over time and across workflows.
- Data Validity: Confirms that the data accurately represents the entity or process being measured.
Example: A sales dataset is reliable if it consistently records transactions correctly. It is valid if the recorded transactions accurately reflect real-world sales.
Ensure Consistent, Reliable Data Across Your Organization
How to Improve the Reliability of Data?
Improving data reliability doesn’t have to be rocket science. There are nine key factors that any business can address that will improve the reliability of its data.
1. Assess Your Current Situation
The first factor in improving data reliability is to develop an effective foundation for your data collection strategies. You need to assess your current situation to determine:
- Where each piece of data comes from
- How you’re storing data
- How you are using data
First, determine where you are currently at with your data before developing a plan for going forward. That’s how you get started improving data reliability.
2. Build a Robust Data Infrastructure
After you’ve assessed your current situation you can put plans in place to build a robust data infrastructure for both new and existing data. Wherever you’re collecting data—from your CRM system, other internal databases, or outside sources—you need to be able to collect as much data as necessary to feed your operations and decision-making, but not anything that you won’t actually use. You need a secure, yet easy-to-use central data repository and you need to define how your data will be stored, formatted, and organized. You need to ensure that everyone in your organization who needs access to specific data gets it, but no one else.
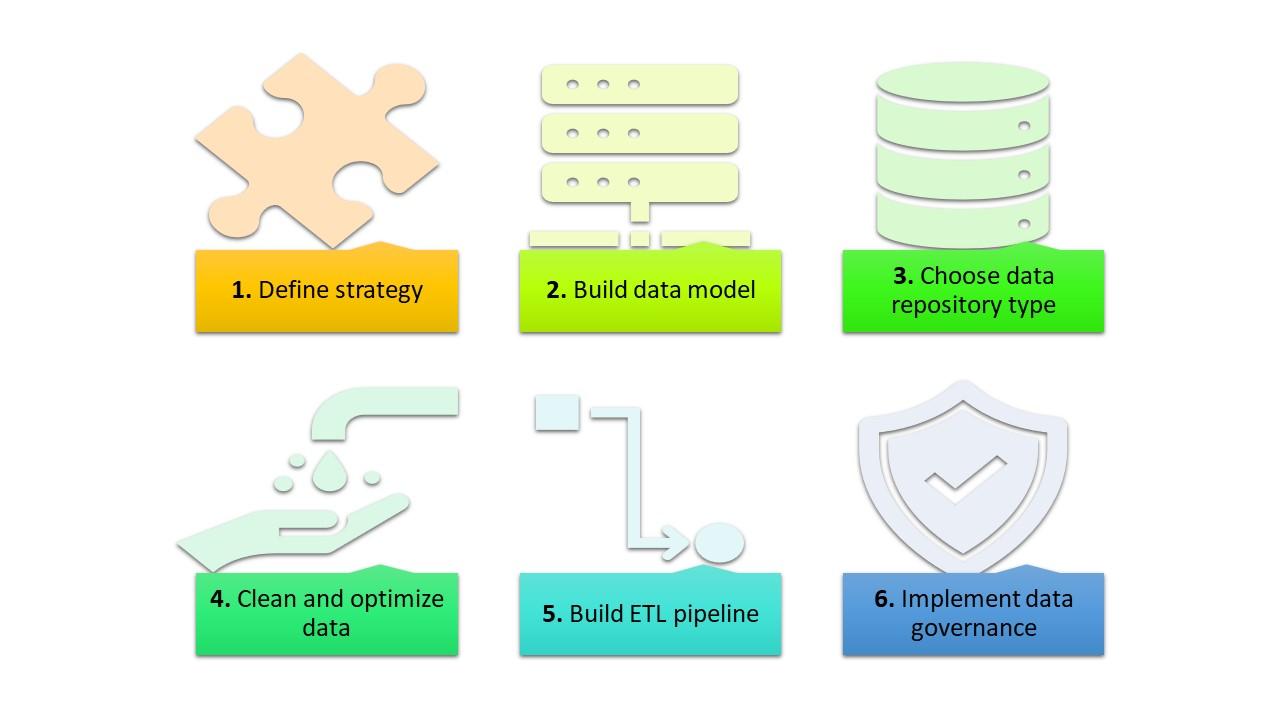
Building a robust data infrastructure is a six-step process:
- Define your strategy
- Build a data model
- Choose your data repository type (data lake, data warehouse, or hybrid)
- Clean and optimize your data
- Build an extract, transform, and load (ETL) process
- Implement ongoing data governance
3. Clean Existing Data
You’ll be ingesting plenty of new data over time, but you also need to deal with the existing data you’ve historically collected. Don’t assume that your existing data is clean; in fact, it’s safe to assume that it is probably of fairly low quality and needs some work. In particular, you want to examine your existing data and fix or remove records that are:
- Inaccurate
- Incomplete
- Duplicative
- Outdated
- Incorrectly formatted
Data cleaning is best accomplished with an automated data quality monitoring (DQM) solution, such as DataBuck from FirstEigen. You want a DQM platform that can automate the entire process so that you don’t have to waste valuable resources manually evaluating the quality of your existing data.
4. Analyze Data Creation and Ingestion
Your data repository isn’t static; you’ll be continuously adding new data in the days, months, and years to come. It’s important that you analyze the new data you’re creating internally and ingesting from external sources to ensure that it is as clean and reliable as possible.
The longstanding 1-10-100 rule states that it costs just $1 to prevent bad data, $10 to correct bad data, and $100 to fix problems resulting from bad data. Thus, it is prudent to spend the money you need up-front to ensure that you’re working with clean data from the initial ingestion.
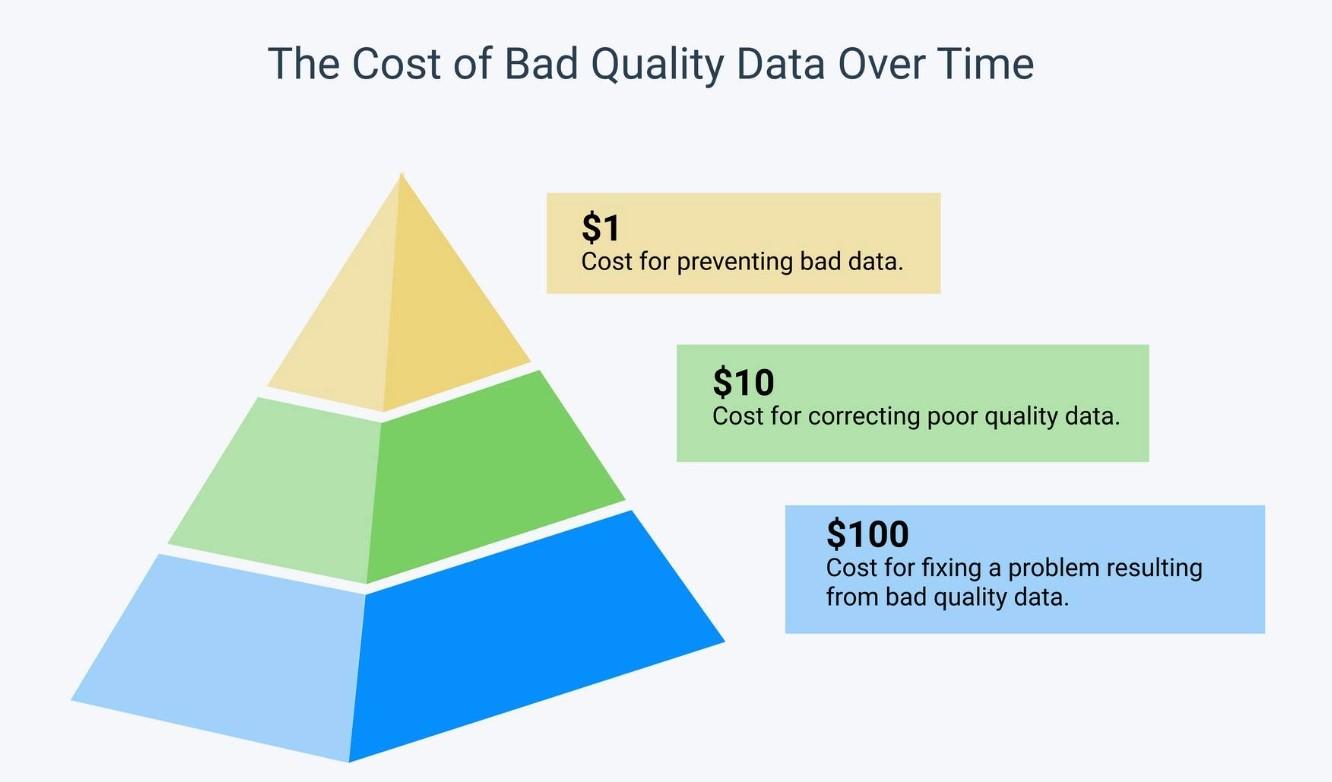
Image Source: Internet
5. Optimize Data Collection Processes
Once you’ve analyzed your internal and external data collection processes, you need to optimize that data collection to minimize the incidence of unreliable data. Here’s how to do that.
Start by analyzing your internal processes for entering new data. Seek to automate data entry wherever possible to minimize human errors. Make sure that all data entry conforms to your standardized data formats and is validated for accuracy and completeness.
Next, look at all other sources from which you ingest new data. Make sure that their data formats match your established data format and use a DQM solution during the ingestion process to week out inaccurate and unreliable data.
6. Break Down All Data Silos
Many companies —especially larger ones— collect data in different places throughout the organization. You might have similar data collected in different departments or in different physical locations. This is not a good thing.
Data silos work against your goal of improving data reliability. Not only do silos often make it difficult to find and share data across your organization, they also often adhere to different standards of organization and quality.
To ensure the most reliable data—and ensure that all data is available to all employees who need it—you need to break down your organization’s data silos. Instead, institute a centralized CRM platform and central data repository for use by all departments and locations. And work towards building a culture of sharing and collaboration, not of isolation.
(The following video describes why data silos are bad for business.)
7. Integrate Apps to Connect Data
As you’re removing your organization’s data silos, you also need to integrate all the different apps and platforms used by your employees. This helps to connect data across your organization and provide a unified view of all your data. Integrating your various apps and systems also synchs up all your data. This way, when a piece of data is updated in one location it is automatically updated wherever else it is used.
8. Organize Your Data
To get maximimum use of the data you collect, you need to organize it. This makes it easier to locate specific data and speeds up the data retrieval process.
Every organization has its own unique way of segmenting its data. You typically do so via the use of labels, tags, groups, and other information, often stored in metadata. You may want to segment your data by customer type, demographics, sale type, purchasing history, or the like.
9. Employ Robust Reporting and Dashboards
Finally, make sure you gain maximum insight from your data by creating robust reports and interactive dashboards. Track those key metrics that matter most to your business to ensure you get the detailed analysis you need.
The Role of Automation in Data Reliability
Automation is key to achieving data reliability at scale. Tools like DataBuck use AI and machine learning to:
- Automate 70% of data monitoring tasks
- Detect and flag inconsistencies in real time
- Generate a Data Trust Score for ongoing assessments
By reducing manual effort, automation allows teams to focus on strategic initiatives rather than data troubleshooting.
Improve Your Data Quality and Reliability Today
Improve Data Reliability and Validity With DataBuck
When you want to improve data reliability, turn to the experts at FirstEigen. Our DataBuck platform uses artificial intelligence and machine language to automate more than 70% of the data monitoring process. DataBuck works with both existing and new data to ensure that it is reliable, accurate, and up to date—automatically.
Contact FirstEigen today to learn about using DataBuck to improve data reliability.
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQ
Data reliability refers to the accuracy, consistency, and trustworthiness of data, ensuring it is suitable for decision-making and business operations.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

What Do Failed AI Projects Have in Common?
Most AI failures are not model failures — they are data, governance, operational trust, and weak AI-ready foundations. “AI alone is not the solution – trusted, validated, continuously governed data is the…

Why Data Trust Is the Real Foundation of AI Success
Enterprises are racing to adopt AI—LLMs, copilots, and autonomous agents that can trigger actions across systems. But as AI moves…

AI-Powered Data Quality Validation for Smarter AML Detection
Fraud, Anti-Money Laundering (AML) and counter-terrorist financing (CTF) programs are only as good as the data they consume. Advanced monitoring…
Bad Data Is Costing You More Than You Think
