
Angsuman Dutta
CTO, FirstEigen
Enhance AWS Glue Pipeline With Autonomous Data Validation
Data operations and engineering teams spend 30-40% of their time firefighting data issues raised by business stakeholders.
A large percentage of these data errors can be attributed to the errors present in the source system or errors that occurred or could have been detected in the data pipeline.
Current data validation approaches for the data pipeline are rule-based – designed to establish data quality rules for one data asset at a time—as a result, there are significant cost issues in implementing these solutions for 1000s of data assets/buckets/containers. Dataset-wise focus often leads to an incomplete set of rules or often not implementing any rules at all.
With the accelerating adoption of AWS Glue as the data pipeline framework of choice, the need for validating data in the data pipeline in real-time has become critical for efficient data operations and to deliver accurate, complete, and timely information.
This blog provides a brief introduction to DataBuck and outlines how to build a robust AWS Glue data pipeline to validate data as data moves along the pipeline.
What is DataBuck?
DataBuck is an autonomous data validation solution purpose-built for validating data in the pipeline. It establishes a data fingerprint for each dataset using its ML algorithm. It then validates the dataset against the fingerprint to detect erroneous transactions. More importantly, it updates the fingerprints as the dataset evolves over time thereby reducing the efforts associated with maintaining the rules.
DataBuck primarily solves two problems:
- Data Engineers can incorporate data validations as part of their data pipeline by calling a few python libraries. They do not need to have a priori understanding of the data and its expected behaviors (i.e. data quality rules)
- Business stakeholders can view and control auto-discovered rules and thresholds as part of their compliance requirements. In addition, they will be able to access the complete audit trail regarding the quality of the data over time
How Does DataBuck Enhance AWS Glue?
Integrating DataBuck with AWS Glue provides a robust, automated system to validate datasets in real-time, without manual rule-writing. Here’s how DataBuck enhances data validation:
- Freshness — determine if the data has arrived within the expected time of arrival.
- Completeness — determine the completeness of contextually important fields. Contextually important fields are identified using mathematical algorithms.
- Conformity — determine conformity to a pattern, length, and format of contextually important fields.
- Uniqueness — determine the uniqueness of the individual records.
- Drift — determine the drift of the key categorical and continuous fields from the historical information
- Anomaly — determine volume and value anomaly of critical columns
How DataBuck Works With AWS Glue?
In DataBuck, the user provides Snowflake connection information along with the database details and triggers the continuous data validation process. Once the data validation process is activated, DataBuck sends its ML engine to snowflake to analyze the data and identify data quality issues. Summary results are then presented to the user through the web console. At no point in this process, the user needs to write rules or move data out of snowflake.
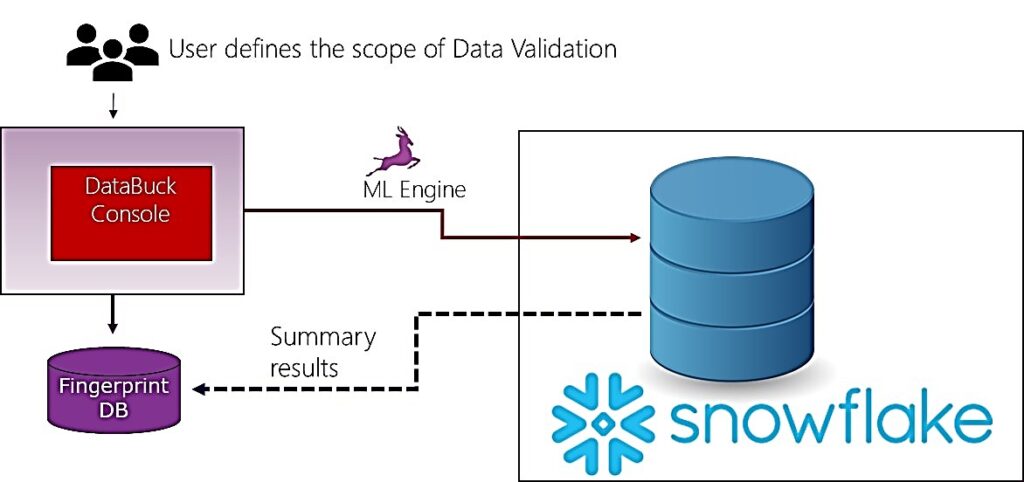
Steps to Set Up DataBuck With AWS Glue
Using DataBuck within Glue job is a three-step process as shown in the following diagram
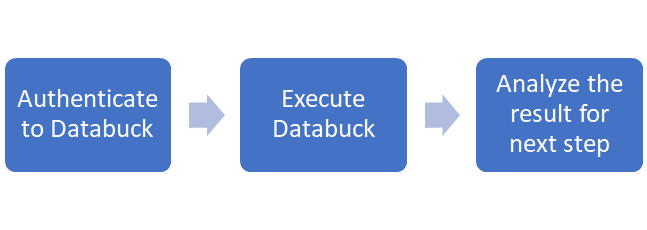
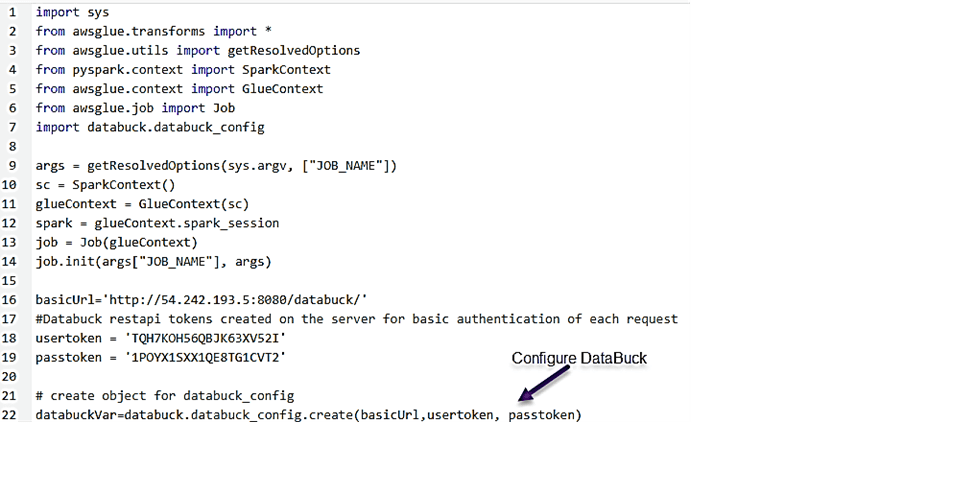
Step 1: Authenticate and Configure DataBuck
Step 2: Execute DataBuck

Step 3: Analyze the Result for the Next Step
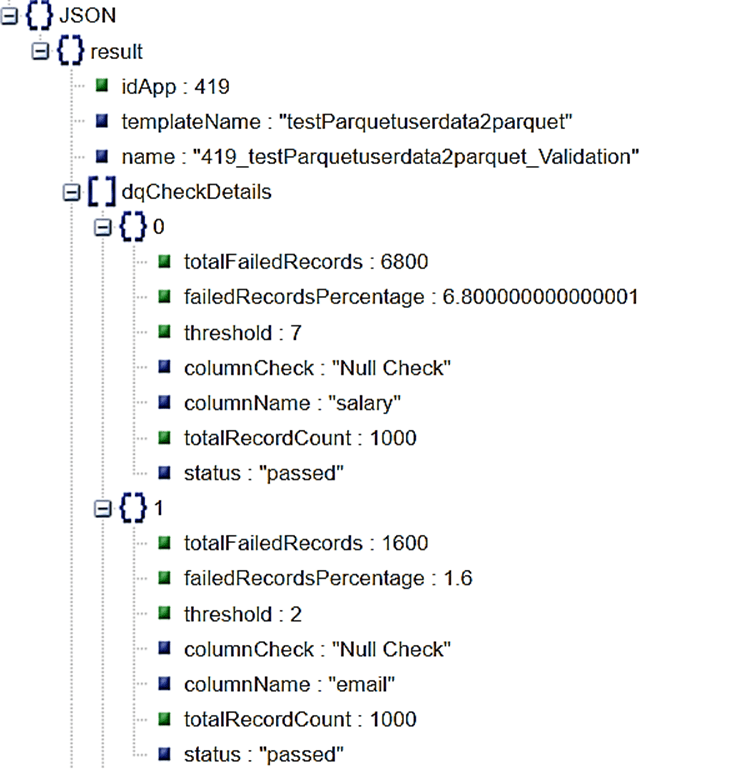
Business Stakeholder Visibility
In addition to providing programmatic access to validate AWS dataset within the Glue Job, DataBuck provides the following results for compliance and audit trail
1. Data Quality of a Schema Overtime
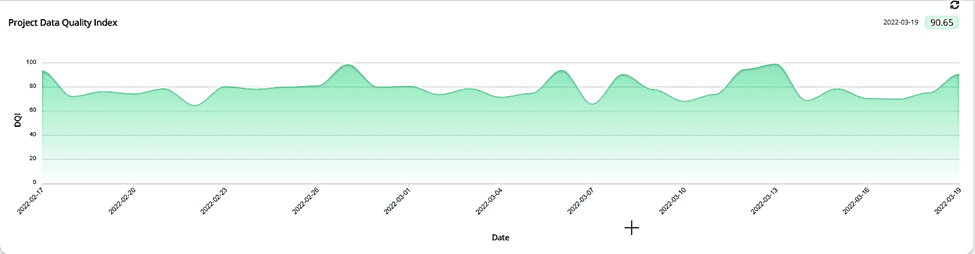
2. Summary Data Quality Results of Each Table

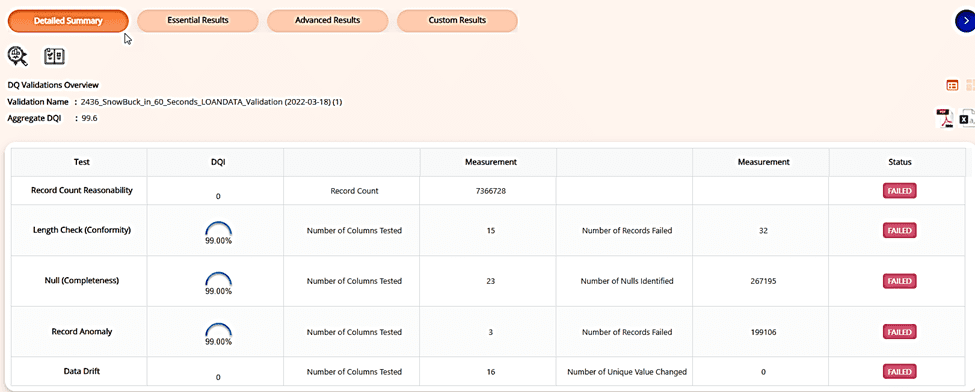
3. Detailed Data Quality Results of Each Table
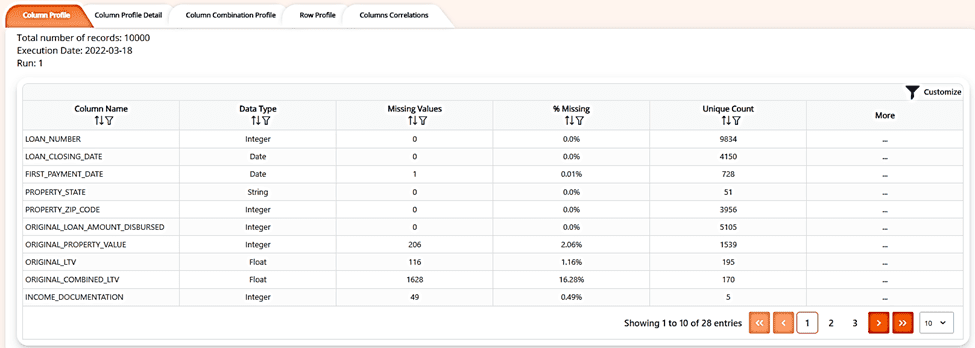
4. Detailed Data Profile of Each Table
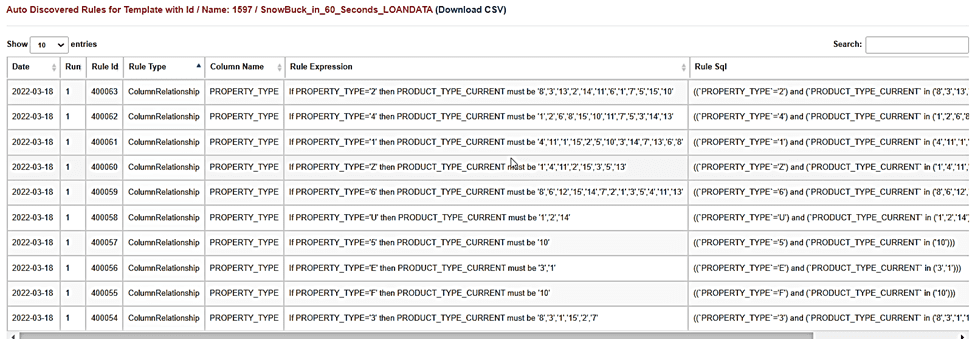
5. Discovered Data Quality Rules for Each Table
Summary
DataBuck provides a secure and scalable approach to validate data within the glue job. All it takes is a few lines of code and you can validate the data on a going manner. More importantly, your business stakeholder will have full visibility to the underlying rules and can control the rules and rule threshold using a business user-friendly dashboard.
Incorporating DataBuck with AWS Glue simplifies the process of validating large data pipelines. With minimal code, real-time data validation, and full business visibility, your organization can ensure data accuracy and compliance, making it easier to act on reliable data insights.
If you’re looking to enhance your AWS Glue pipeline with autonomous validation, contact us for a free demo of DataBuck today.
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQs
Data validation ensures the accuracy, completeness, and reliability of the data flowing through the pipeline. In AWS Glue, where large amounts of data are processed, real-time validation helps prevent data errors from affecting downstream processes, leading to more trustworthy insights and decisions.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

The Power of Data Quality for AI Success
AI agents are only as reliable as the data they act on. As enterprises race to deploy AI, data quality has quietly become the deciding factor between success and costly failure. The Problem Nobody Is Solving Most AI conversations…

Mainframe Data Reconciliation for Cloud Migration
Cloud migration is no longer just an infrastructure decision. For data leaders and data engineers, it is a trust decision. …

What Do Failed AI Projects Have in Common?
Most AI failures are not model failures — they are data, governance, operational trust, and weak AI-ready foundations. “AI alone is not the solution – trusted, validated, continuously governed data is the…
Bad Data Is Costing You More Than You Think
