
Seth Rao
CEO at FirstEigen
Data Quality vs. Data Trustability: Understanding Key Differences and Why They Matter
Do you know the difference between data quality and data trustability? Both are concerned with data quality and usability but differ in how they approach the issue. Data quality tracks the accuracy of data within a data pipeline. Data trustability has a larger scope, using machine learning to identify data errors from data creation to data analysis.
While data quality and data trustability are different in both scope and approach, they share the common goal of making data more accessible and useful. Your organization needs both.
Quick Takeaways
- Data quality monitoring ensures that data is accurate, complete, consistent, timely, unique, and valid
- Data trustability uses machine learning to automate the creation of new data-quality rules
- Data trustability is faster than data quality monitoring and self-evolving to create new and different algorithms for newly discovered data types
- Data quality works at the end of the data monitoring process
- Data trustability works across the entire pipeline
What is Data Quality?
Data quality is important to all modern organizations. Businesses need high-quality data to inform their day-to-day operating decisions, as well as their long-term strategic decisions. Managers need to know what is happening in their businesses and not just guess at it.
Poor quality data enables poor decisions. Imagine sending invoices to customers and not having their correct addresses. That type of poor-quality data wastes resources (wasting postage on letters that never get delivered) and results in lower revenues from all those undelivered bills.
The State of CRM Data Health in 2022 survey from Validity found that almost half of all respondents lost more than 10% of their annual revenue because of poor-quality CRM data. IBM estimates that bad data costs U.S. companies more than $3 trillion annually. It’s not an insignificant problem.
Companies evaluate data quality using six key metrics. High-quality data is equally:
- Accurate
- Complete
- Consistent
- Timely
- Unique
- Valid

Data that falls short in any of these metrics could be unusable—although it could be fixed. For example, inaccurate mailing addresses can often be corrected by referring to the Postal Service’s up-to-date database of addresses. Incomplete data, such as missing ZIP codes, can sometimes be filled in. And duplicate data sourced from different-but-similar databases (i.e., non-unique data) can typically be merged into a single record.
Cleaning poor-quality data is the province of data monitoring software, such as FirstEigen’s DataBuck. Data monitoring software looks for data that is deficient in one or more of these key metrics and isolates it for future action. Some bad data can be cleaned, although some are unfixable and must be deleted.
What is Data Trustability?
Data trustability, like data quality, is concerned with the data quality in an organization. Trustability goes beyond traditional data quality monitoring by looking for data that deviate from established norms.
Data trustability uses machine learning (ML) technology to examine the data flowing through an organization’s pipeline. The ML component creates algorithms based on observing the organization’s data. The data trustability software uses these algorithms to construct “fingerprints” representing the existing data.
These ML-created data fingerprints represent ideal data models. The data trustability software compares real-world data to these data models and flags data that aren’t similar enough to the data fingerprints—and thus are likely to be of poorer quality.
Data experts use data trustability tools to identify common issues with data quality, including:
- Dirty data (data that contains invalid or inaccurate values)
- Incomplete data (records with fields left empty)
- Inconsistent data (records that don’t adhere to standard data formats)
- Duplicative data (records for the same subject from two different sources)
- Anomalous data (records that deviate from a dataset’s norms, as indicated by mismatching data fingerprints)
How Do Data Quality and Data Trustability Differ—and How Are They Similar?
Data quality and data trustability have the same goal, to ensure higher data quality. Where they differ is how they approach this goal.
Traditional data quality monitoring examines each piece of data itself to determine whether it meets quality standards. Data monitoring software typically works from a set of human-defined rules and checks each record’s metadata to see if it adheres to those rules. Even when automated, it is still a time-consuming process.
Data trustability is a more automated process that looks at the bigger picture. Machine learning technology not only creates fingerprints for common data types, but it also learns from all the data flowing through the system to create its own algorithms and rules without the need for human intervention. This approach finds more data errors than traditional data monitoring and is considerably faster.
Data trustability extends beyond data observability to identify and resolve most data issues. ML enables data trustability to see more potential errors in more places than either data observability or data monitoring tools can. It sees the whole picture, not just part of it.
Data Trustability is Fast and Efficient
Because data trustability use ML technology, it’s considerably faster than traditional data quality monitoring. Data trustability uses ML to eliminate the need for human interaction, which speeds up the entire process. Data that used to take days to analyze can now be filtered and cleaned within minutes.
Data Trustability is Self-Evolving
Not only is trustability faster than traditional data monitoring, but it’s also self-evolving. ML technology constantly learns from the data flowing through the system and uses that knowledge to write new algorithms and data monitoring rules. This technology enables the system to quickly and automatically adapt as the system ingests new and different types of data, with the need for human intervention.
Data Trustability Works Across the Entire Data Pipeline
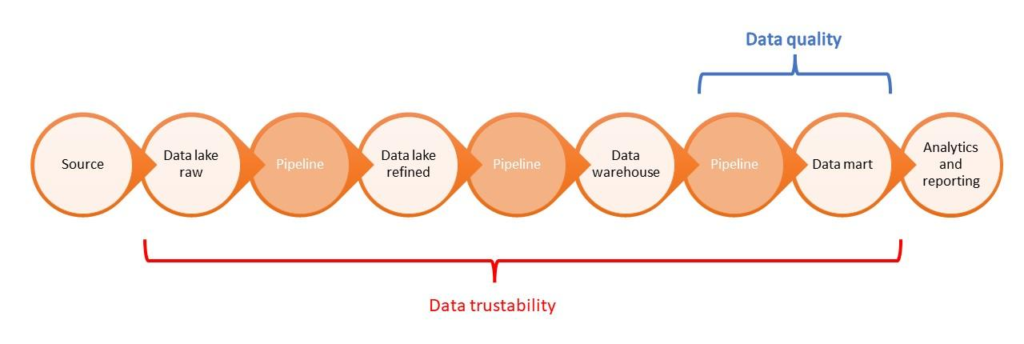
Traditional data quality monitoring tends to focus on the end of the data pipeline after new data has been created or ingested. It doesn’t stop poor-quality data from being ingested, impacting other data in the pipeline.
Data trustability, on the other hand, works across the entire data pipeline. It starts observing data as its created or ingested and follows that data throughout the entire process. Data trustability can catch data errors at multiple points in the pipeline. It lets the system more quickly identify and fix data quality issues and deal with them before they affect the organization’s overall data.
Let DataBuck Improve Both Data Quality and Data Trustability
To ensure the highest-quality data for your organization, you need data quality monitoring and trustability. That’s what you get with DataBuck from FirstEigen. Using AM/ML technology, DataBuck can automatically validate thousands of data sets in just a few clicks. DataBuck is the surefire way to jump on board the data monitoring bandwagon.
Contact FirstEigen today to learn more about data quality and data trustability.
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQs
Data quality focuses on the accuracy, consistency, and completeness of data, ensuring it meets business requirements. Data integrity ensures the data remains unaltered and accurate throughout its lifecycle. While quality is about usability, integrity safeguards against unauthorized changes.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

The Power of Data Quality for AI Success
AI agents are only as reliable as the data they act on. As enterprises race to deploy AI, data quality has quietly become the deciding factor between success and costly failure. The Problem Nobody Is Solving Most AI conversations…

Mainframe Data Reconciliation for Cloud Migration
Cloud migration is no longer just an infrastructure decision. For data leaders and data engineers, it is a trust decision. …

What Do Failed AI Projects Have in Common?
Most AI failures are not model failures — they are data, governance, operational trust, and weak AI-ready foundations. “AI alone is not the solution – trusted, validated, continuously governed data is the…
Bad Data Is Costing You More Than You Think
