
Seth Rao
CEO at FirstEigen
Understanding Data Trust: How to Enhance Data Quality and Trustworthiness With Trusted Data Formats?
Do you trust the data used by your organization? A data trust score measures how much you trust your data and is based on how accurate, up-to-date, and relevant your data is. In the end, the data trust score reflects your data’s quality—high-quality data is more trustworthy than low-quality data.
Quick Takeaways
- Organizations have to trust their data, or they won’t be able to make informed business decisions
- The data trust score measures how well a given data set can be trusted to be of high quality
- Calculate a data trust score from five key data metrics: validity, completeness, popularity, discoverability, and usage
- To improve data trust scores, improve data quality
What is Data Trust?
Data trust is the confidence that a dataset is accurate, reliable, and actionable. Without it, decisions based on faulty data can lead to wasted resources, damaged reputations, and missed opportunities.
According to Talend’s Data Health Barometer survey:
- 36% of respondents reported low trust in their data
- Only 29% felt confident making decisions based on available data.
Building trust in data requires organizations to address key concerns, including data quality, completeness, and usability. By improving these areas, businesses can reduce decision-making risks and maximize the value of their data.
The Growing Importance of Data Trust
- Data Proliferation: The annual generation of zettabytes of data (1 zettabyte = 1 billion terabytes) highlights the immense challenge of managing, integrating, and validating this data.
- Diverse Data Sources: Modern organizations collect data from SaaS applications, IoT devices, unstructured sources like social media, and traditional systems, increasing the complexity of ensuring data integrity
- Compliance Requirements: Regulations such as GDPR and CCPA emphasize the need for trusted data practices to protect privacy and prevent misuse.
Six Dimensions of Data Quality for Building Data Trust
The foundation of data trust lies in ensuring data quality. The six dimensions below, defined by the Data Management Association, can help organizations assess their data:
- Accuracy
- Definition: Does the data accurately represent the real-world entity or event?
- Example: Misaligned date formats (MM/DD/YYYY vs. DD/MM/YYYY) can cause missed deadlines or financial discrepancies.
- Completeness
- Definition: Does the data set include all the necessary information?
- Example: Missing postal codes in address records reduce usability and limit customer communication.
- Consistency
- Definition: Is the data uniform across multiple systems and reports?
- Example: A single date represented differently (e.g., 11/12/2023 vs. 2023-12-11) creates inconsistencies across departments.
- Timeliness
- Definition: Is the data current and accessible when needed?
- Example: Financial decisions require up-to-date earnings data to avoid revenue loss.
- Uniqueness
- Definition: Does the dataset eliminate redundancy and duplicates?
- Example: Duplicated customer profiles result in inaccurate reporting and wasted resources.
- Validity
- Definition: Does the data conform to required formats, types, and ranges?
- Example: Invalid addresses or phone numbers compromise operational efficiency.
Organizations must evaluate these dimensions continuously to ensure that data remains decision-ready and compliant.
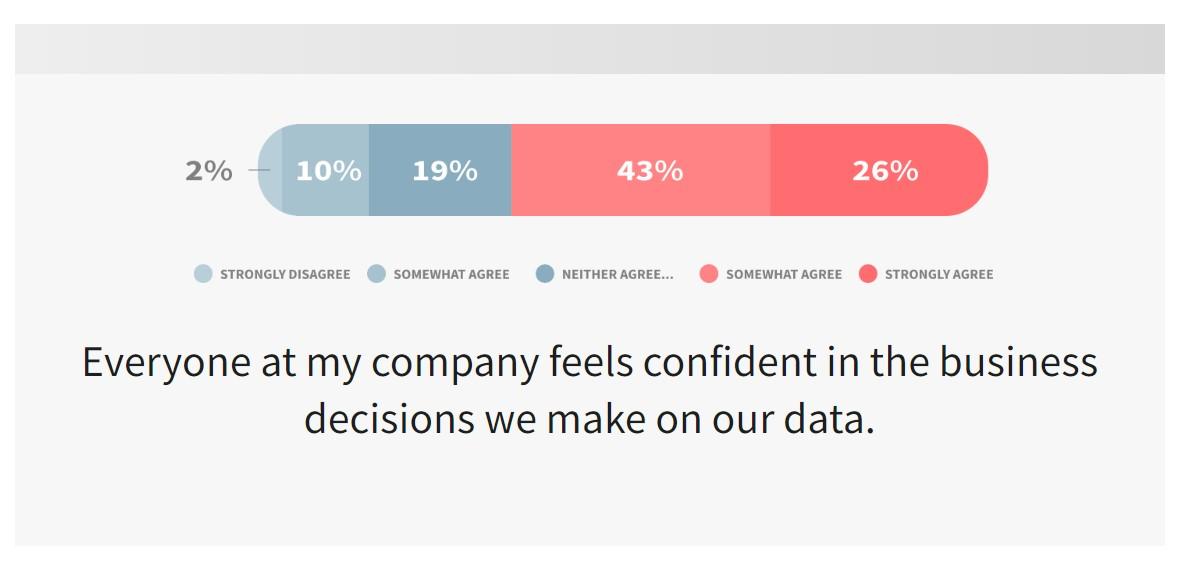
Image Source: Internet
The term “data trust” reflects your confidence that a given set of data is accurate and actionable. High-quality data is more trustworthy than low-quality data and more readily usable by key staff. Data that cannot be trusted cannot be used with any degree of confidence to make key operational or strategic business decisions.
Start Your Data Accuracy Journey Today
What is a Data Trust Score?
The data trust score is an attempt to quantity how trusted data is. A higher data trust score means that data is more likely to be trusted. A lower data trust score means that there are enough issues with the data to cause a lack of trust.
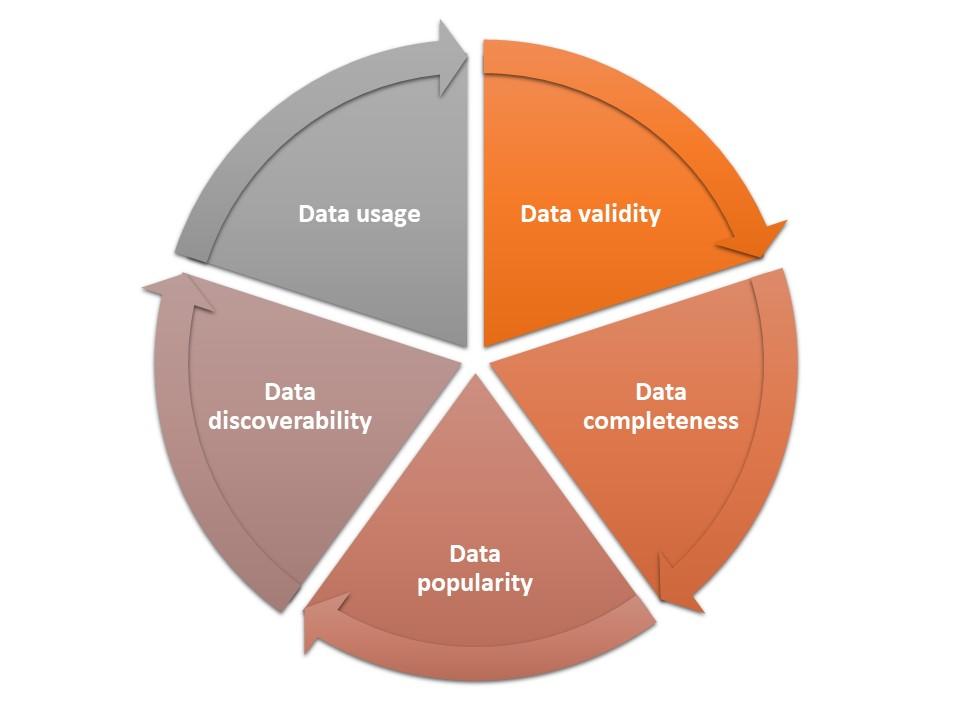
The data trust score is based on five key metrics:
- Data validity, which measures data quality by tracking the number of valid values in a dataset
- Data completeness, which measures the number of incomplete records in a dataset
- Data popularity, which measures a dataset’s reliability, based on certification levels and user ratings
- Data discoverability, which reflects the use of metadata (such as tags, descriptions, keywords, and the like) to make it easier to find and access specific data in a dataset
- Data usage, which tracks how often a dataset is used as a source for data pipelines
How well a dataset performs in these five areas results in the overall data trust score. This score is expressed on a scale from 0 to 5, with 5 being the highest level of trust and 0 being completely untrustworthy.
Why is a Data Trust Score Important?
Companies need to trust the data they use, although it’s understandable if they don’t. According to Experian, 77% of businesses say that inaccurate data hindered their ability to respond to COVID-related market changes. When data is limited, outdated, or unreliable, management can’t trust it—and their decision-making suffers.
One of the chief benefits of a data trust score is that it quantitatively measures the trustability of a dataset. Management no longer has to guess how much to trust given data. They can use the data trust score to determine which data earns their trust.
How Can Your Organization Improve Data Trust?
With so much data entering your system daily, how do you know which data to trust—and how can you improve overall data trustability?
Consider the following best practices to improve your organization’s data trust scores. These approaches focus on improving data quality throughout the data pipeline—the higher the data quality, the more you can trust it.
1. Recognize That It Costs More to Fix Bad Data Than It Does to Create Good Data
Some bad data can be fixed. Some can’t. But even if you can repair inaccurate or incomplete data, it’s not as cost-effective as creating or ingesting better data.
Consider the 1-10-100 rule. This rule states that you can spend $1 to improve data from the start, spend $10 to correct bad data later, or lose $100 by not fixing bad data at all. In other words, it costs less to improve data quality at the outset than to fix it later or suffer through the failures and mistakes resulting from using bad, unrepaired data.
This means you should focus your organization’s efforts on creating more accurate data and using only third-party data that meet data quality standards. Letting poor-quality data in at the outset will only cost you more later.
2. Employ Data Monitoring
Unfortunately, you probably won’t be able to create or ingest 100% perfect data. Imperfections and inaccuracies creep into even the best datasets, and you need to identify those errors before they affect your trust in the data. Use data monitoring tools such as FirstEigen’s DataBuck to monitor the data your organization creates and ingests and isolate poor-quality data for future action.
3. Clean or Delete Poor-Quality Data
What do you do with the poor-quality data you identify? The choice is three-fold. You can leave it alone and let it degrade the overall data quality and data trustability of your data. You can opt to delete bad records, which improves the resulting quality and trustability of your database even as it lowers the quantity of data. Or you can choose to repair bad data.
The latter approach improves the overall quality of your data without affecting the quantity available. There are many ways to clean poor-quality data, including:
- Comparing data values to known values in another database
- Completing incomplete fields
- Standardizing data created with different schema
- Converting unstructured data to a standardized structure
4. Add Metadata to Provide More Visibility
Metadata improves visibility, searchability, and quality. It helps you identify what’s supposed to be in a given file or dataset. If data arrives without metadata, it’s often worth the effort to add it manually. It’s certainly worth the effort to include metadata when creating new data.
5. Focus on Data Quality Metrics
One essential way to improve your data trust score is to improve your data quality, which requires focusing on six key data quality metrics:
- Accuracy
- Completeness
- Consistency
- Timeliness
- Uniqueness
- Validity
Focusing on these metrics will help you improve data quality and increase trust in your data.
Implementing a Data Trust Model in Your Organization
Starting Your Journey
Implementing a Data Trust model involves striking a delicate balance between data standardization and interoperability. Here’s how you can get started:
Define Your Framework: You need a flexible yet structured framework. A balance between open access and structured templates ensures usability without overwhelming complexity.
Utilize Existing Data: Leverage historical data to inform your strategy. Most organizations already possess valuable data that can be an excellent foundation for your data trust model.
Foster Agreement: Reach a consensus on data definitions and usage. The most significant discussions often revolve around standardizing terminology and ensuring everyone shares the same understanding.
Creating Core Agreements
Alignment on Terminology: Establish common definitions for all terms across departments and locations, which is particularly crucial in multinational environments where language barriers can add complexity.
Clear Objectives: Ensure everyone is aligned on the ultimate goals, such as driving insights that lead to tangible actions like investment decisions or product recalls.
Ensuring Business Benefit
Identify Clear Benefits: Highlight how the data trust model supports business objectives. When benefits are clear, stakeholders are more likely to engage and implement necessary changes.
Make It a Priority: Assign the responsibility of data management to specific roles. Without designated individuals, implementation efforts may falter.
Enhancing Communication and Collaboration
Implementing a Data Trust can significantly improve communication across your supply chain. By standardizing data sharing and language, you enable seamless collaboration and a unified understanding of data insights.
In summary, the key to successfully implementing a Data Trust model lies in establishing a balanced framework, fostering organizational agreement, and clearly articulating the business benefits. By doing so, you can streamline data processes and drive informed decision-making.
Experience Seamless Data Trust and Reliability!
Use DataBuck to Improve Your Data Trust Score
The data trust score reflects the quality of your data and how much you trust that data when making important business decisions. When you want to improve your data quality and trust score, turn to DataBuck from FirstEigen. DataBuck is an autonomous data quality management solution that automatically monitors data ingested into and flowing through your data pipeline. This results in higher-quality data—and better data trust scores.
Contact FirstEigen today to learn more about data quality and data trust scores.
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQs
Data trust refers to the confidence users have in the data they access and use, based on its accuracy, completeness, timeliness, and consistency. High data trust ensures that decisions made using the data are reliable.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

AI-Powered Data Quality Validation for Smarter AML Detection
Fraud, Anti-Money Laundering (AML) and counter-terrorist financing (CTF) programs are only as good as the data they consume. Advanced monitoring…
Managing Tariff Implications Through Data Integrity in Global Supply Chains
In today's global marketplace, supply chains span continents. From consumer electronics to industrial machinery, companies rely on global sourcing and...

Data Quality Issues Affecting the Pharmaceutical Industry: Finding a Solution
Pharmaceutical enterprises worldwide navigate a complex ecosystem where vast amounts of sensitive datasets are central to their operations. The data…
Get Started!
