Is your organization ready to implement a data mesh architecture? Building a data mesh involves transitioning from a centralized to a decentralized data management model. You need to create a framework that pushes data storage and management from a monolithic entity to multiple data domains while improving access and scalability. To do this, you need to know the principles of data mesh architecture and how to apply them in the real world.
Quick Takeaways
- A data mesh is a distributed framework for decentralized data storage and management.
- The four principles of data mesh are data as a product, domain-oriented ownership, self-service data infrastructure, and federated data governance.
- A data mesh architecture improves data visibility, scalability, flexibility, and collaboration.
- To build a data mesh architecture, start by assigning independent data product teams, defining data domains, and implementing company-wide data governance policies.
What is a Data Mesh?
A data mesh is a distributed framework designed for managing data in large organizations. Unlike traditional centralized data architectures, a data mesh takes a decentralized data approach, weaving data storage and access into a mesh-like structure. This architecture incorporates data from multiple sources and stores it in a way that allows easy access for individuals and teams throughout the organization. Though more complex than a centralized structure, a data mesh offers superior data access, scalability, and security.
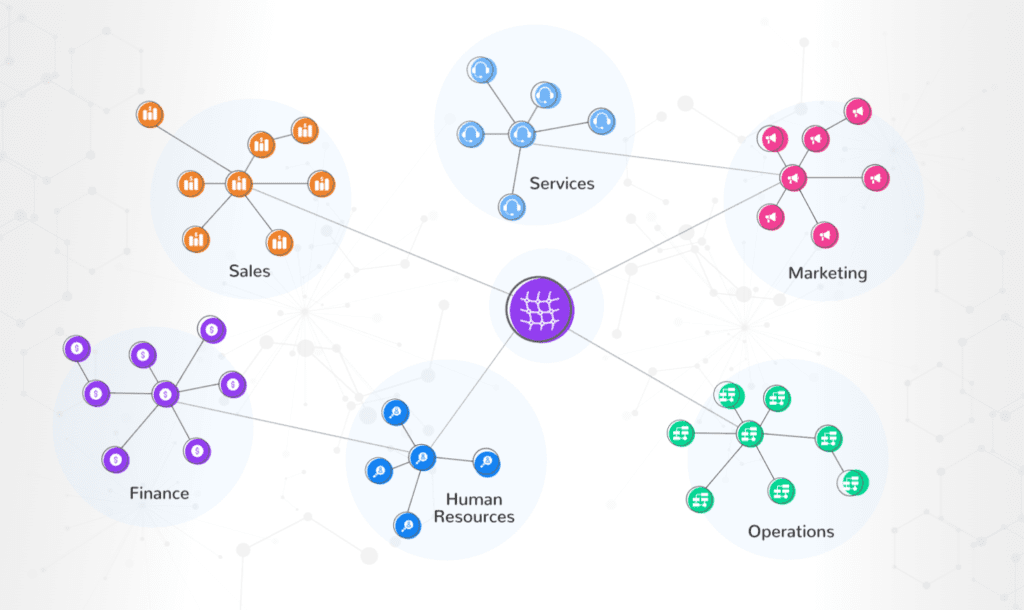
Benefits of Data Mesh Architecture
According to the Data and Analytics Leadership Annual Executive Summary 2023, 41.5% of leaders surveyed plan to invest in data mesh in 2023. This pivot from centralized to decentralized data architecture is driven by several reasons, including the following:
- Easy scalability. With a mesh architecture, managing more data is as simple as adding more nodes. The decentralized nature of a mesh network means that no major system upgrades are necessary. Growth comes either by dispersing data throughout the mesh or adding low-cost servers in new nodes.
- Democratic data processing. Unlike centralized systems where a single entity controls data management, data mesh spreads control to domain experts who can create more meaningful data products.
- Increased flexibility. It’s easier to make changes to a decentralized structure than a centralized one. This prevents bottlenecks and enables the system to evolve as necessary.
- Lower costs. Distributed data architectures run more efficiently, are less prone to catastrophic failures, are easier to repair, and can be upgraded at less cost. The result is lower operating and storage costs.
- Improved data visibility and access. Wakefield Research reports that 69% of data executives find their organizations’ data trapped in silos and not fully utilized. Data mesh makes all data available to all users, reducing silos and enhancing collaboration.
- Increased collaboration. A data mesh architecture eliminates inefficient data silos. This enables and encourages collaboration between teams, which is less doable with centralized structures.
- Enables remote work. Remote workers become additional in a data mesh, simplifying access for a growing remote workforce.
Understanding the Four Key Data Mesh Principles
Understanding the four core principles inherent in a data mesh is essential for building an efficient network.
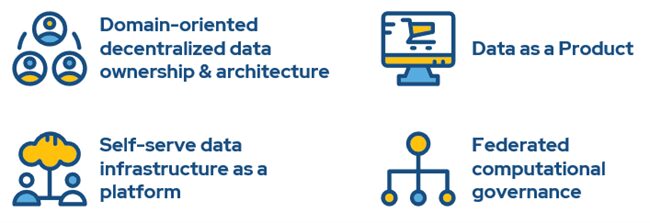
Data as a Product
In a data mesh, data is not merely a resource but a product with defined ownership and accountability. Each data product is a valuable asset.
A data product should be:
- Discoverable
- Addressable
- Trustworthy
- Self-describing
Domain-Oriented Ownership
A data mesh requires domain-oriented ownership. There is no centralized entity owning all the organization’s data. Instead, ownership is delegated to the teams closest to the data they use.
Self-Service Data Infrastructure
With decentralized data ownership comes decentralized management. Teams require tools and services to manage their data storage and processing independently. All data management is self-service.
Federated Data Governance
In a data mesh, data security is a shared responsibility. Leadership must establish company-wide standards and policies for data quality and security, which individual domain owners must implement.
Establishing a Data Mesh Architecture, Step by Step
How best can your organization create a data mesh architecture? While the task can seem daunting, it simply requires following these basic steps.
1. Form Data Product Teams
Transitioning from a centralized to a decentralized structure requires creating cross-functional teams within each data domain. Each team should include data engineers and domain experts.
2. Analyze Existing Data
Before you convert any data, you need to understand your current data. Catalog your existing data and assign detailed metadata to know what you’re working with.
3. Define Data Domains
Organize your analyzed data into logical business domains, either by location, department, business unit, or other relevant factors. This domain organization will shape your mesh structure.
4. Define Data Products
Each data domain should then define data products that are important to the consumers of their data. These data products should be clearly defined with a target audience in mind.
5. Establish Data Quality Guidelines
While data management is domain-specific, data quality standards should be dictated from above. Each domain team should work with similar data quality monitoring tools to maintain consistent quality throughout the organization.
6. Implement Federated Data Governance Policies
Likewise, data governance policies should be set at a company-wide level. Federated data governance should define standards for data schemas, naming conventions, access controls, and the like.
7. Choose the Right Technologies
Should your data mesh exist on-premises or in the cloud? Assess if existing data warehouses and lakes can be integrated into your new mesh. You need to determine the right technologies for your data mesh needs.
8. Monitor, Scale, and Evolve
Your work isn’t done when you flip the switch on your new data mesh. You need to monitor mesh performance to determine what’s working and what isn’t, then fine-tune your system for better performance. You also need to scale and evolve your mesh as your data needs change and grow. It’s a never-ending iterative process.
Use DataBuck to Monitor Data Mesh Data Quality
Whichever type of data architecture your organization uses, data quality is imperative. This is especially true with a data mesh architecture, where data is ingested from multiple sources and distributed via multiple data domains. FirstEigen’s DataBuck uses artificial intelligence technology to monitor all data ingested into and flowing through a data mesh. It identifies and either cleanses or deletes questionable data in real time, ensuring consistent, high-quality data throughout the mesh.
Contact FirstEigen today to learn more about data quality in data meshes.
Check out these articles on Data Trustability, Observability, and Data Quality.
- 6 Key Data Quality Metrics You Should Be Tracking
- How to Scale Your Data Quality Operations with AI and ML
- 12 Things You Can Do to Improve Data Quality
- How to Ensure Data Integrity During Cloud Migrations