
Seth Rao
CEO at FirstEigen
Why Every Catalog Needs a Data Trust Score?
Does your data catalog need a data trust score? With the increasing use of data catalogs in data management, the answer is a resounding yes. Assigning a data trust score to a catalog ensures that the data within is trustworthy for use in both day-to-day and long-term decision-making.
Quick Takeaways
- A data trust score quantifies the trustworthiness of data in a data catalog
- A high data trust score assures users that they can trust the data they use to make important decisions
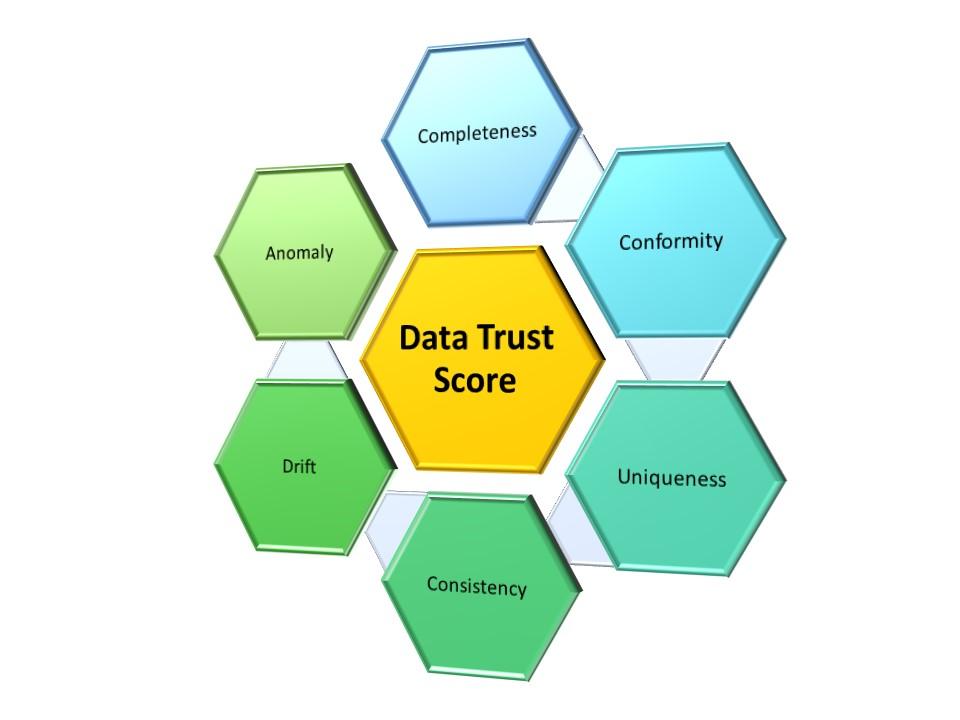
- To calculate data trust scores, data experts examine the data’s completeness, conformity, uniqueness, consistency, drift, and anomaly
- Data quality solutions use machine language to speed up the evaluation process and more accurately determine data trust scores
What Is a Data Trust Score?
Measuring the trust level of a data catalog is challenging. What do you measure and how?
A data trust score attempts to quantify this assessment. A data catalog with a higher data trust score is more trustworthy than one with a lower score. If the data trust score is too low, the lack of trust might make the data unusable.
Data experts compute data trust scores based on the weighted average of six data quality metrics:
- Completeness: How complete and accurate the values are in a set of data.
- Conformity: How well data in a dataset conform to standard patterns and formats.
- Uniqueness: How unique the individual records are in a dataset without duplications.
- Consistency: How consistent the relationships are between different fields.
- Drift: How much key data differs from historical information.
- Anomaly: How data in a set differ from the norm.
Data trust scores aren’t immutable. They can and often do change over time and with use of the data. Re-evaluating the trust score is necessary every time these changes in the data set impact any of these five parameters.
Why Data Trust Scores Are Valuable
For the data in a data catalog to be useful, it must be trustable. Unfortunately, 77% of organizations don’t fully trust their data. Why all this data distrust? According to Vanson Bourne’s Data Distrust report:
- 53% say it’s because they have too many disconnected data sources
- 40% say it’s because poor integration results in missing or incomplete data
- 31% say it’s because data is poorly structured or incorrectly formatted
This data distrust results in hesitant or uninformed decision-making. If a business can’t trust its data, let alone data sourced from third parties, it can’t make informed decisions. Daily operations can suffer, as can long-term strategic planning. Businesses hindered by untrustworthy data miss opportunities, react slower to marketplace changes and often make the wrong decisions.

In contrast, businesses that trust their data can act quickly when new opportunities present themselves and react just as quickly when problems arise. The data they need is readily available and of high quality, informing both short-term and long-term decision-making. Executives in these companies know their data is high quality and use it to make better decisions.
Does Your Data Catalog Need a Data Trust Score?
A data catalog is a systematized inventory of all your organization’s data assets. It manages data assets via the use of metadata and, in doing so, enables the searching and evaluation of a dataset—and access to that set’s data.
A properly constructed and ordered dataset provides context to those accessing the included data. It not only unifies an organization’s metadata, but it also helps users discover and utilize the data contained within. Data managers and analysts use data catalogs to extract insights and provide value for the good of the organization.
Poor-quality data in a catalog can cause users and management not to trust the entire data catalog. Distrust can affect your organization’s operational efficiency, risk management, compliance, and customer-forward efforts. To ensure that your company garners actionable insights from your data, you must ensure that the data within is accurate, complete, and valid. Only then can your data catalog be trusted.
Use data quality and observability tools to measure and improve data quality in a catalog to improve data trust scores. Then, communicate the improved trust scores to all stakeholders who depend on that data for their decision-making. When management knows they’re working with good information, better decisions result.
Employ these tools throughout the data pipeline and across time. By comparing different points of analysis, data managers can see how a data quality score changes based on various factors—and take proper action if the data quality is declining.
Challenges with Generating Data Trust Scores
Generating a data trust score is every bit as difficult as it seems. Given the large and increasing volumes of data generated and ingested by most organizations, it’s almost impossible to manually monitor and evaluate data quality. Data teams can experience a wealth of challenges when integrating data quality into a data catalog, including:
- Data assets obtained from third-party sources can be unfamiliar and differently structured
- Implementing data quality rules
- Each dataset requires its own set of data quality rules—and the more datasets you have, the more work involved
- Generating detailed audit trails is difficult
- Maintaining the implemented rules is cumbersome
All of this makes data quality evaluation difficult and time-consuming. Fortunately, businesses can employ machine learning (ML) technology to learn from the massive quantities of data involved, uncover hidden data patterns, and translate those patterns into new data quality rules. ML-based solutions, such as DataBuck, quickly analyze and evaluate large volumes of data, generate data trust scores, and improve the overall data quality.
Use DataBuck Monitor and Improve Data Trust Scores
DataBuck is an autonomous data quality management solution that monitors data trustability across the entire data pipeline. It works with all major data catalogs, including Alation, Ataccama, IBM, Informatica, Octopai, and Zeenea. DataBuck uses machine language to automatically evaluate data quality, calculate a trust score for the catalog’s data assets, and display the results in the data catalog. It can automatically validate thousands of data sets in just a few clicks—quickly validating trust in your organization’s data.
Contact FirstEigen today to learn more about data quality and data trust scores—and download our latest whitepaper, Autonomous Data Trust Scores for Data Catalogs.
Check out these articles on Data Trustability, Observability & Data Quality Management-
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

The Power of Data Quality for AI Success
AI agents are only as reliable as the data they act on. As enterprises race to deploy AI, data quality has quietly become the deciding factor between success and costly failure. The Problem Nobody Is Solving Most AI conversations…

Mainframe Data Reconciliation for Cloud Migration
Cloud migration is no longer just an infrastructure decision. For data leaders and data engineers, it is a trust decision. …

What Do Failed AI Projects Have in Common?
Most AI failures are not model failures — they are data, governance, operational trust, and weak AI-ready foundations. “AI alone is not the solution – trusted, validated, continuously governed data is the…
Bad Data Is Costing You More Than You Think
