
Seth Rao
CEO at FirstEigen
Ingestion Monitoring vs Data Observability: Key Differences for Modern Systems
Data ingestion monitoring and data observability are two different yet complementary approaches to improving the quality of an organization’s data. When it comes to ingesting data from various sources, monitoring the quality of that data is essential. It’s also important that your data management systems work properly and don’t introduce new errors into ingested data. That’s how ingestion monitoring and data observability work together—they’re both effective on their own but produce even better results when used together.
Quick Takeaways
- Ingestion monitoring looks at new data entering a system to ensure adequate data quality
- Data observability looks at the data health of the entire system to identify and repair systemic issues that affect data quality
- Organizations can use ingestion monitoring and data observability together to clean today’s data and ensure that tomorrow’s data is even higher quality
What is Ingestion Monitoring?
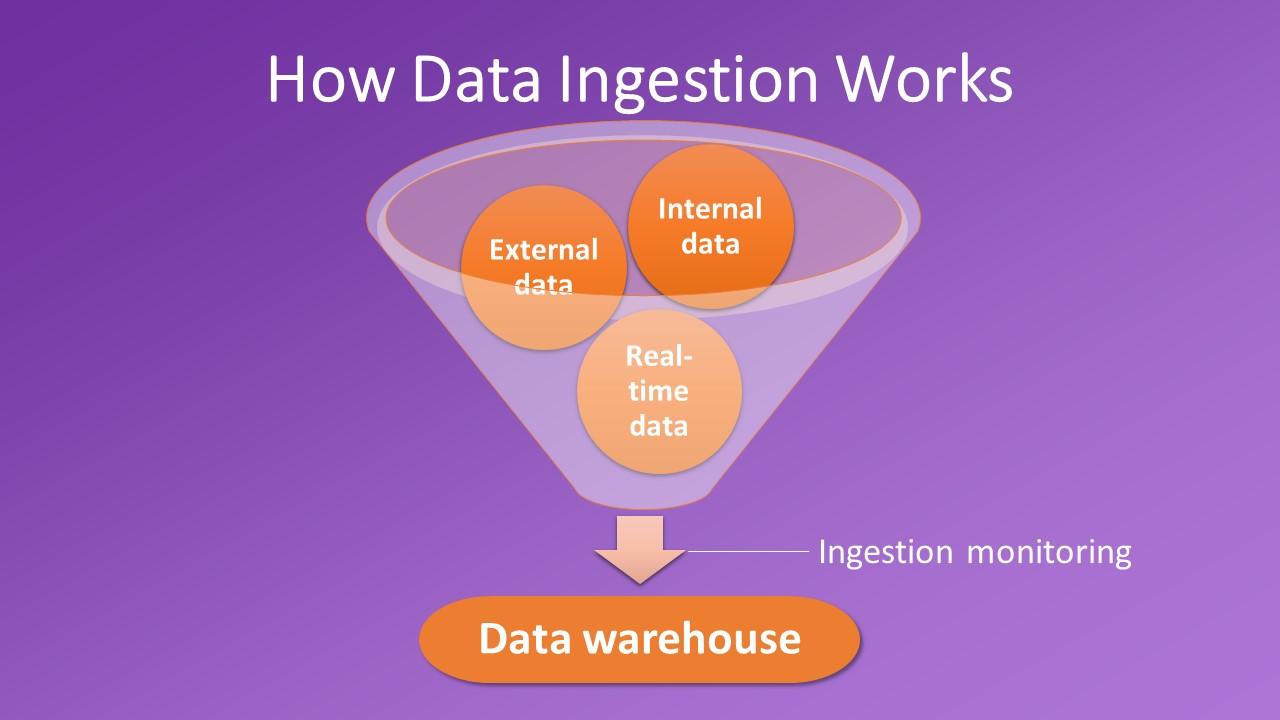
Data ingestion describes how data gets into a system. Data for ingestion can come from a variety of sources, both internal and external. The system can ingest it in real-time or in batches. It comes from existing databases, data lakes, real-time systems and platforms (such as CRM and ERP solutions), software and applications, and IoT devices.
A proper data ingestion process doesn’t just import raw data. Instead, it transforms data in various formats from various sources into a single standardized format. Data ingestion can even take unformatted data and fit it into an existing data format.
When ingesting data, it’s important to ensure it is of the highest possible quality. This is where ingestion monitoring comes in. Data ingestion monitoring involves identifying poor-quality or incorrectly formatted data, cleaning and formatting the data, and making the data ready for others to use.
Ingestion monitoring evaluates incoming data using the following metrics:
- Accuracy—whether the data is correct
- Completeness—whether all fields are populated
- Consistency—whether similar data from multiple databases are the same
- Timeliness—whether the data is recent
- Uniqueness—if there’s any duplicated data
- Validity—whether all data is in the proper format
Identifying and dealing with poor-quality data is critical before it enters your system. This could involve correcting inaccuracies, completing incomplete records, formatting unformatted data, removing duplicates, and even deleting data that you can’t repair easily.
Ingestion monitoring is important because it’s easier to catch and fix poor-quality data before it enters a system. Once data enters the system, it’s mixed with your existing data, which makes it more difficult to find and even more difficult to clean. Because you don’t want poor-quality data to dilute the quality of your existing data, you need to employ ingestion monitoring.
What is Data Observability?

Ingestion monitoring deals with ensuring data quality as it moves into a system. Data observability is about ensuring the quality of the data system itself.
Data observability tracks system quality in five key ways:
- Freshness—how current the data is
- Distribution—whether data values fall within an acceptable range
- Volume—whether the data is complete
- Schema—how the data pipeline is organized
- Lineage—how data flows through the pipeline
By working through each of these key metrics, a data observability solution can evaluate a data management system’s health, identify systemically affecting data quality, and suggest changes to the system that address these issues. Unlike ingestion monitoring, which evaluates the data itself, data observability is about evaluating and troubleshooting the entire data management system to resolve any issues that impact data quality.
When you want to ensure that your data management systems are working properly and not introducing new errors into your data, employ data observability. It’s essential for the long-term data health of any organization.
Transform Your Data System with Ingestion Monitoring and Data Observability
How Ingestion Monitoring and Data Observability Complement Each Other
Ingestion Monitoring focuses on fixing the immediate issue of poor-quality data entering your system, while Data Observability works to identify and resolve deeper, systemic issues that could lead to data quality problems in the future.
Together, they provide a comprehensive approach to data quality:
- Ingestion Monitoring ensures only clean data enters the system by addressing immediate problems.
- Data Observability works to prevent future data issues by improving the data pipeline itself.
By using both techniques, organizations can maintain high-quality data today and continue to improve the quality of future data streams.
Ingestion Monitoring vs Data Observability: Key Differences and Examples
The main difference between ingestion monitoring vs data observability lies in their focus. While Ingestion Monitoring focuses on the quality of the data as it enters the system, Data Observability focuses on the performance and health of the data pipeline and system as a whole.
Monitoring vs Observability Example:
- Ingestion Monitoring: You detect and correct a problem with an incoming order record, such as a missing field for the customer address, before it enters your data warehouse.
- Data Observability: You notice that the data pipeline experiences slow processing times during the peak of data ingestion, indicating that the system itself may need optimization to handle future loads more effectively.
Ingestion Monitoring addresses immediate data issues, while Data Observability helps identify and resolve systemic problems that could affect the health of the entire data management system. Both are essential, but they work at different layers of the data pipeline.
How Ingestion Monitoring and Data Observability Can Work Together to Improve Data Usefulness?
Organizations of all types and sizes need high-quality data to inform their daily operations and long-term decision-making. Experts say that poor-quality data can cost an organization between 10% and 30% of its revenue.
For these reasons alone, organizations can and should employ both ingestion monitoring and data observability with the shared goal of ensuring high-quality data.
Ingestion monitoring is essential to ensure that no inaccurate or incomplete data enters the system. This addresses immediate issues with data quality.
Data observability is essential to ensuring the quality of data over the longer term. By identifying and helping to resolve systemic issues in a data pipeline, data observability should result in fewer data quality issues affecting the ingestion process.
How can your organization make ingestion monitoring and data observability work together? Here are a few proven successful approaches:
- Identifying key relationships between a variety of data sources
- Designing new data quality rules for the ingestion process
- Developing new data workflows based on evolving data patterns
- Raising red flags when there is a deterioration in data quality during the ingestion process and beyond
When ingestion monitoring and data observability work together, your data management processes will run smoother, your data pipeline will be more efficient, and your data quality will improve. You need to both identify data errors and prevent future errors from occurring, which you can only do by employing ingestion monitoring and data observability.
Leverage Ingestion Monitoring and Data Observability for Better Data Quality
Best Practices for Implementing Both Ingestion Monitoring and Data Observability
Implementing both Ingestion Monitoring and Data Observability requires a comprehensive strategy. Below are best practices for integrating these two approaches:
- Define clear data quality metrics: Establish clear definitions for what constitutes “good” data at both the ingestion stage and throughout the system.
- Choose the right tools: Use automated tools like DataBuck to streamline the monitoring and observability processes. DataBuck helps organizations automate up to 70% of data quality management tasks and uses machine learning to continuously improve data quality rules.
- Foster collaboration across teams: Align data engineering, data science, and business intelligence teams to ensure a holistic approach to data quality.
- Continuously monitor and adjust: Data systems and sources evolve over time, so continuously monitor both the ingestion process and the overall system health to ensure optimal data quality.
Common Pitfalls in Data Monitoring and Observability and How to Avoid Them
While implementing both techniques can greatly improve data quality, some common challenges may arise:
- Overlooking the need for continual updates: Data systems change, and so should your monitoring and observability processes. Regularly update your data rules and metrics.
- Neglecting data lineage: Without understanding how data flows through your system, it’s difficult to identify where issues arise. Ensure comprehensive data lineage tracking is in place.
- Ignoring alerts and anomalies: Make sure your team acts on insights from monitoring and observability tools to prevent minor issues from escalating.
By being aware of these potential pitfalls, you can ensure that your data quality strategy remains effective and proactive.
Real-World Applications: How Companies Benefit from Both Ingestion Monitoring and Data Observability
Many organizations today rely on both Ingestion Monitoring and Data Observability to maintain a high standard of data quality. By identifying errors early and fixing systemic issues, these companies are able to avoid costly data problems and improve decision-making accuracy.
For example, a retail business could use Ingestion Monitoring to ensure that customer data from various sources is clean and complete. At the same time, Data Observability can help ensure that the entire data pipeline remains intact and efficient, preventing future issues as new data is ingested.
Let DataBuck Help Improve Your Organization’s Data Quality
The more your organization depends on data, the more you should turn to the data-quality experts at FirstEigen. Our DataBuck data quality management solution automates more than 70% of the data monitoring process and uses machine learning to automatically generate new data quality rules. DataBuck works with both ingestion monitoring and data observability to endure you’re ingesting and using the highest-quality data possible.
Contact FirstEigen today to learn more about ingestion monitoring and data observability.
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQ
Monitoring focuses on tracking predefined metrics (e.g., CPU, network traffic) to ensure systems are functioning correctly, often using dashboards and alerts. Observability, on the other hand, is a broader concept that provides deeper insights by correlating logs, metrics, and traces to understand the internal states of a system. Observability answers the "why" behind issues, even when they are unanticipated.
Observability encompasses monitoring but goes beyond it by offering a comprehensive view of the entire system’s behavior. Instead of only identifying known issues, observability enables teams to explore unknown issues by correlating different types of data (e.g., logs, traces, metrics) and identifying patterns in complex environments, such as microservices and distributed architectures.
With observability, you gain detailed insights into why a system is behaving in a particular way. This is achieved through continuous collection and correlation of data from various sources, which helps in understanding the relationships between different system components. Root cause analysis becomes faster and more accurate, enabling teams to address not only the symptoms but also the underlying problems.
Monitoring is ideal for tracking simple, predictable system behavior and ensuring uptime and performance, especially in traditional IT environments. Observability is essential for cloud-native and distributed systems where complexity makes it harder to predict failures. Both are important, but observability is crucial when dealing with dynamic environments that require a deeper understanding of unknown issues.
Observability in cloud-native environments helps manage the complexity of microservices, containers, and serverless applications. It provides real-time insights into the health of distributed systems, making it easier to debug, optimize performance, and improve resilience. Observability tools can also predict issues before they impact users by analyzing telemetry data across the entire system.
Tools like Prometheus, Grafana, and Elastic are great for monitoring and collecting metrics. For observability, tools like Jaeger for tracing, Elastic for log aggregation, and Dynatrace for full-stack observability offer deep insights into system performance and help with root cause analysis.
DataBuck specifically enhances data observability by offering real-time data quality monitoring and anomaly detection across data pipelines. It automates the identification of data quality issues, ensuring businesses have clean and reliable data. DataBuck provides both ingestion monitoring and observability, helping teams quickly identify and resolve data issues, improving overall system efficiency.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts



Get Started!
