Authenticate Cloud Data Pipeline with Autonomous Data Trustability Validation
Scalable

Set up 1,000 data assets in less than 40 hours
Fast

Validate 100 million records in 60 seconds
Better

Look for 14 types
of data errors
Economical

Validate 10,000 Data Assets in less than $50
Secure

No Data leaves your Data Platform
Integrable

Data Pipeline Data Governance Alert System Ticketing System
How does DataBuck help authenticate the Data Pipeline?
DataBuck is an autonomous Data Trustability validation solution, purpose-built for validating data in the pipeline.
- 1,000’s of Data Trustability and Quality checks are auto-discovered and recommended.
- Thresholds for those checks are auto-recommended by the Artificial Intelligence program.
- Business users can adjust thresholds in a self-service dashboard, without IT involvement.
- Data Trust Score is auto-calculated for every file and table.
- The Data pipeline can be controlled by the Data Trust Score of the overall file or any individual Data Quality dimension.
- Errors can be stopped from contaminating downstream data by robust data pipeline control.
DataBuck as Part of the Pipeline
A) Run DataBuck on ADF (Azure Data Factory), AWS Glue, Databricks, Talend, DBT, Fivetran, Matillion, Informatica or any ETL tool that supports rest API/Python
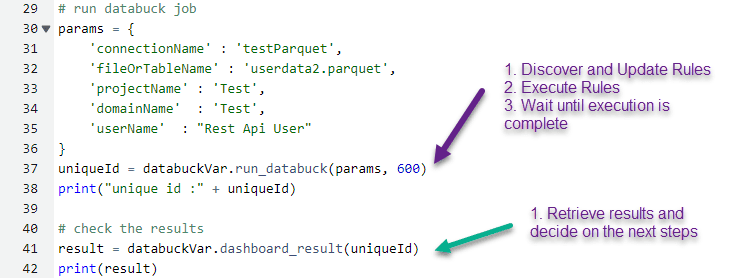
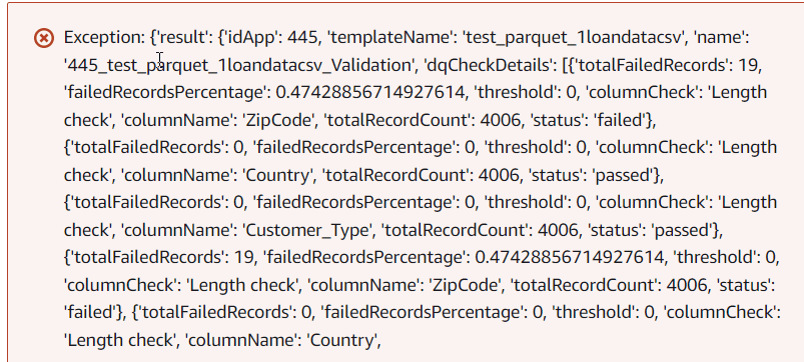
B) Integrate with enterprise scheduling system (e.g. Autosys)
C) Use the built-in scheduler
Benefit of automating Data Trustability and Quality validation with Machine Learning
Get drinkable, crystal clear stream of data from the pipeline along with these benefits…

People productivity
boost >80%

Reduction in unexpected errors: 70%

Cost reduction >50%

Time reduction to onboard data set ~90%

Increase in processing speed >10x

Cloud native
Our Popular Blogs

Managing Tariff Implications Through Data Integrity in Global Supply Chains
By Angsuman Dutta

Data Quality Issues Affecting the Pharmaceutical Industry: Finding a Solution
By Seth Rao

Agentic Data Trust: Next Frontier for Data Management
By Angsuman Dutta
Read our White Papers
A Framework for AWS S3/Azure ADL/GCP Data Lake Validation
With the accelerating adoption of AWS S3/Azure/GCP as the data lake of choice, the need for autonomously validating data has become critical. While solutions like Deequ, Griffin, and Great Expectations provide the ability to validate AWS/Azure/GCP data, these solutions rely on rule-based approach that are rigid, non-flexible, static, and not scalable for 100’s of data assets and often prone to rules coverage issues.
Solution: A scalable solution that can deliver trusted data for tens of 1,000’s of datasets has no option but to leverage AI/ML to autonomously track data and flag data errors. It also makes it an organic, self-learning system that evolves with the data.

13 Essential Data Validation Checks for Trustworthy Data in the Cloud and Lake
When data moves in and out of a Data Lake or a Cloud, the IT and the business users are faced with the same question- is the data trustworthy?
Automating these 13 essential data validation checks will immediately engender trust in the Cloud and Lake.
Download this white paper today!

Friday Open House
Our development team will be available every Friday from 12:00 - 1:00 PM PT/3:00 - 4:00 PM ET. Drop by and say "Hi" to us! Click the button below for the Zoom Link: