
Seth Rao
CEO at FirstEigen
What is Data Preparation? A 6-Step Guide to Clean, Transform, and Optimize Data for Analysis
Do you know why data preparation is important to your organization? Poor-quality or “dirty” data can result in unreliable analysis and ill-informed decision-making. This problem worsens when data flows into your system from multiple, unstandardized sources.
The only way to ensure accurate data analysis is to prepare all ingested data to meet specified data quality standards. That is why understanding the data preparation process is crucial.
With the rise of real-time data processing, efficient data preparation is more crucial than ever. Businesses need to handle and prepare data swiftly to match the pace of decision-making and operational demands. This shift requires robust processes to maintain data quality and accuracy, enabling timely and informed decisions based on up-to-date information
This guide will walk you through key steps in data preparation, including data cleansing and transformation, to ensure your data is ready for accurate analysis.
Quick Takeaways
- Data preparation turns raw data into processed, reliable information for an organization.
- Without proper data preparation, inaccurate and incomplete data may enter the system, resulting in flawed reporting and analysis.
- Data preparation improves data accuracy, enhances operational efficiency, and reduces data processing costs.
- The data preparation process comprises six key stages: collection, discovery and profiling, cleansing, structuring, transformation and enrichment, and validation and publishing.
What is Data Preparation?
Data preparation is the process of converting raw, unstructured data into a clean, structured, and standardized format for analysis. It involves cleansing, transforming, and validating data to ensure it meets organizational quality standards. This process is essential for making data usable and reliable for decision-making.
Though the data preparation process can be long and involved, it’s essential in making data usable. Without proper preparation, there is no guarantee that the data your organization ingests will be accurate, complete, accessible, or reliable.
Why is Data Preparation Important?
The average business today faces a deluge of data from an ever-increasing number of sources, much of which is dirty. Cleaning this dirty data is a lot of work. According to Anaconda’s State of Data Science Survey, data specialists spend 39% of their time on data preparation and cleansing. That’s more than they spend on data model selection, training, and deployment combined.
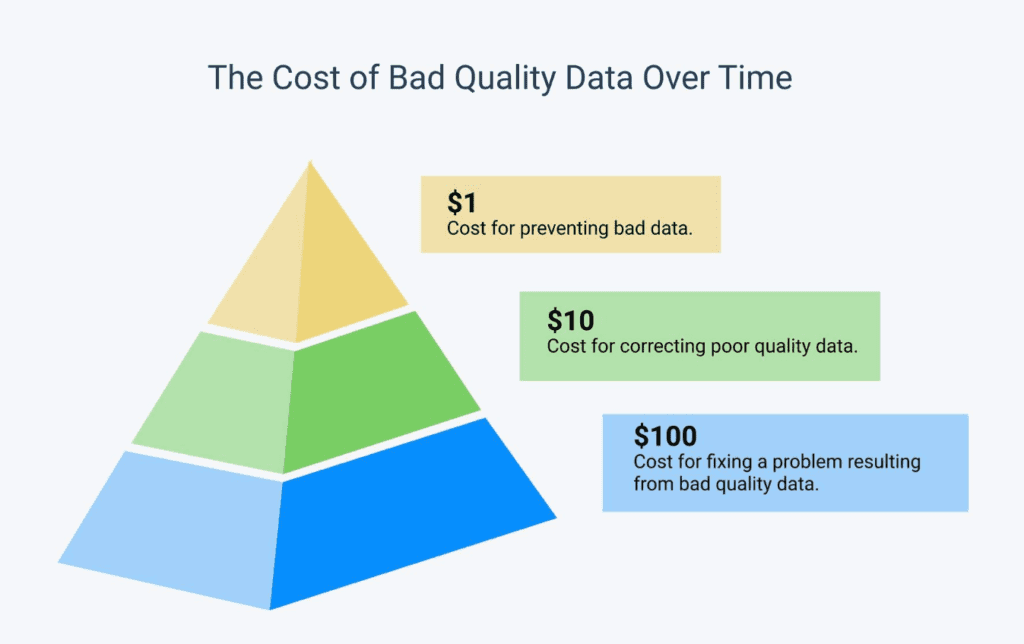
Dealing with all this dirty data requires robust data preparation—especially when that data comes from multiple internal and external sources. Data from multiple sources often appears in different, incompatible formats. Some may be incomplete, inaccurate, or duplicated. Such data simply isn’t usable, at least not reliably.
That’s where data preparation comes in, preparing the data you collect for use across your organization.
Benefits of Effective Data Preparation
Data preparation offers multiple benefits, especially for those working with large amounts of data. The most significant benefits include:
- Identifying and fixing obvious errors in ingested data
- Improving the accuracy of data flowing through the system
- Ensuring consistency of data across sources and applications
- Enabling data curation and cross-team collaboration
- Improving scalability and accessibility to valuable data across the organization
- Ensuring high-quality data for analysis
- Providing more reliable results
- Improving both operational and strategic decision-making
- Reducing data management costs
- Freeing up time for more important tasks
Preparing Data for Analysis: Essential 6 – Step Data Preparation Techniques
The data preparation process varies between industries and organizations within an industry. That said, there are five key components of data preparation that are common across most use cases.
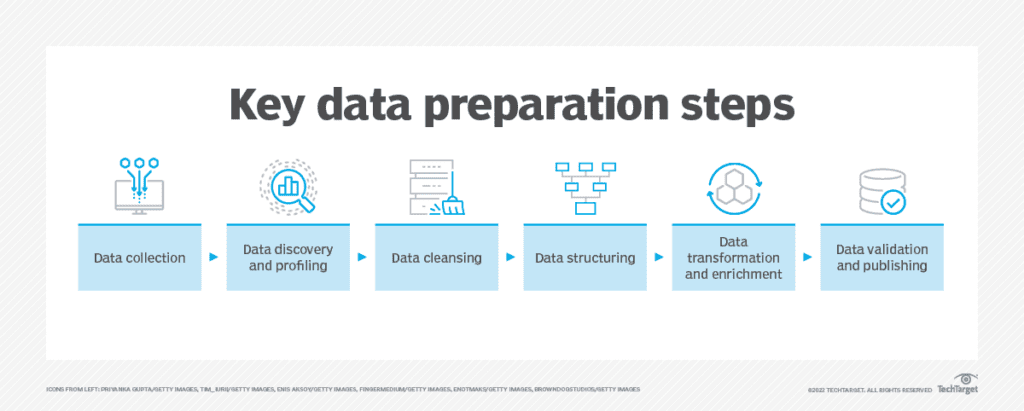
1. Data Collection
The first step in data preparation is acquiring the data. You need to know what data you need, what data is available, and how to gather that data.
Data today can come from a variety of sources, including:
- Internal databases, data warehouses, and data lakes
- CRM and other systems
- External databases
- Internet of Things devices
- Social media
Data can be ingested in batches or streamed in real time. The preparation process must accommodate all these types of data, no matter how they enter the system
2. Data Discovery and Profiling
All ingested data must be examined to understand what it contains and how it can be used. This typically involves data profiling, which identifies key attributes and extracts common patterns and relationships in the data.
This stage marks the beginning of data quality management. You should thoroughly examine the data to identify any inconsistencies, missing values, and other potential issues.
3. Data Cleansing
Any data with issues identified in the discovery and profiling stage should be separated from the presumably higher-quality data ingested. At this point, attempts should be made to cleanse the dirty data, using a variety of techniques such as:
- Removing duplicate data
- Identifying and removing data outside an acceptable range of values
- Filling in missing values
- Synchronizing similar-but-inconsistent entries from multiple sources
- Correcting obvious errors
- Removing outdated data
Data that can be successfully cleansed can be returned to the data set. Data that cannot be reliably repaired should be deleted.
4. Data Structuring
Data from a variety of sources may come in numerous formats. Some will be structured, some unstructured. Standardizing data structure is important for future access. All ingested data must eventually conform to your organization’s standard data structure, which means analyzing that data’s original structure and mapping it to your standard structure.
5. Data Transformation and Enrichment
Beyond structuring, ingested data must be transformed into a format usable by others in your organization. This may involve something as simple as converting date formats or as complex as creating new data fields that aggregate information contained in multiple previously existing fields.
Transforming data enriches it, providing additional insights beyond that contained in the raw data itself and contributing to better decision-making.
6. Data Validation and Publishing
The final stage is data validation and publishing. Data validation involves running automated routines that verify the data’s accuracy, completeness, and consistency. The validated data can then be published to applications or stored in a data warehouse or lake for future use.
Self-Service Data Preparation Tools
- Automating repetitive tasks.
- Enhancing collaboration across teams.
- Reducing dependency on technical expertise.
What Are the Challenges Of Data Preparation?
- Handling Diverse Data Sources: Inconsistent formats and incomplete datasets slow preparation.
- Time-Intensive Processes: Manual efforts delay decision-making.
- Scalability Issues: Legacy systems struggle to process large volumes of data.
- High Costs: Incorrect preparation results in higher operational expenses.
Data Preparation Principles and Best Practices
- Define Objectives: Begin with a clear understanding of what you aim to achieve with your prepared data. Establish key metrics, performance indicators, and outcomes that align with business goals. Defining these objectives will provide direction and help prioritize efforts throughout the data preparation process.
- Automate Repetitive Tasks: Modern AI-driven tools can handle repetitive tasks like data cleansing and transformation with speed and accuracy. Automating these processes reduces human error, saves time, and allows teams to focus on higher-value tasks like data analysis and interpretation.
- Regularly Audit Data: Data evolves, and so should your monitoring efforts. Conduct periodic audits to identify inconsistencies, outdated information, or gaps in data quality. Regular checks ensure your data remains accurate, consistent, and aligned with organizational standards.
- Ensure Security: Safeguard sensitive data during the preparation process by implementing robust security measures. Limit access to authorized personnel, adhere to compliance standards, and use encryption where necessary to protect data integrity and confidentiality.
How to Get Started on Data Preparation?
Starting with data preparation may seem daunting, but breaking it down into manageable steps can simplify the process and set your team up for success. Here’s how to begin:
- Assess Your Needs: Take stock of your organization’s data requirements. Identify the sources of data—be it internal databases, cloud applications, or external APIs—and evaluate their quality and relevance. This assessment helps prioritize data sources that are most critical to your goals.
- Choose the Right Tools: The choice of tools can significantly impact the efficiency of data preparation. Platforms like DataBuck offer AI-driven solutions to automate tasks like cleansing, profiling, and validation. Selecting the right tool ensures scalability and precision in handling large or complex datasets.
- Train Your Team: Equip your team with the knowledge and skills to leverage data preparation tools effectively. Provide training sessions, resources, and best practices to ensure smooth adoption and collaboration across departments.
- Monitor Progress: Continuous evaluation is key to refining the data preparation process. Regularly track progress to identify bottlenecks, optimize workflows, and adapt to changing business needs. Monitoring ensures that your data preparation efforts remain efficient and aligned with organizational goals.
AI-Driven Data Preparation: How Automation Transforms the Process
Automating data preparation with AI offers several key benefits. It reduces manual effort and minimizes errors, leading to more accurate and reliable data. AI-driven automation speeds up the process and ensures consistency across datasets. Additionally, it enables scalable and efficient handling of large volumes of data, making it easier to manage and analyze complex information.
Data Preparation Reimagined: What the Future Holds?
It is certain that in the coming times, the data preparation process is going to be transformed in ways that are commensurate with the technological changes and the growing complexity of data landscapes. Some of the pioneering factors driving this transition include:
Automation and AI Integration: AI and machine learning will take over the processes of cleansing, transforming, and validating data, which is labor-intensive with a risk of human error.
Real-Time Data Processing: Such technologies will mean that data preparation can be done in no time, thus making any decisions that are required at the moment much faster.
Expansion of Data Sources: With globalization and emergence of social media, more data sources will come into play and this will create demand for sophisticated data preparation.
Enhanced Data Governance: There will be a lot of focus on data governance to improve future data preparation that will ensure protection against data collection abuse and preservation of data accuracy.
Scalability and Efficiency: There will be a focus on the changing of tackling methods in response to the changes in the data owing to the ever increasing and growing complexities of the data.
Advanced Data Tools: The development of advanced tools for data integration, visualization, and quality assurance will support organizations in managing and utilizing data more effectively.
These trends will define the future of data preparation, making it more automated, efficient, and responsive to the evolving data landscape.
Improve Data Preparation with FirstEigen’s DataBuck
Data quality monitoring and validation is essential in the data preparation process. DataBuck from FirstEigen monitors data throughout the process, from initial collection to publishing and analysis. It uses artificial intelligence and machine learning technologies to automate more than 70% of the data monitoring process. This reduces data management costs while identifying, isolating, and cleansing poor-quality data.
Contact FirstEigen today to learn more about improving data quality in the data ingestion process.
Check out these articles on Data Trustability, Observability & Data Quality Management-
Frequently Asked Questions (FAQs)
The key steps typically include:
- Data Collection
- Data Cleaning
- Data Transformation
- Data Integration
- Data Validation
- Data Enrichment
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

What Do Failed AI Projects Have in Common?
Most AI failures are not model failures — they are data, governance, operational trust, and weak AI-ready foundations. “AI alone is not the solution – trusted, validated, continuously governed data is the…

Why Data Trust Is the Real Foundation of AI Success
Enterprises are racing to adopt AI—LLMs, copilots, and autonomous agents that can trigger actions across systems. But as AI moves…

AI-Powered Data Quality Validation for Smarter AML Detection
Fraud, Anti-Money Laundering (AML) and counter-terrorist financing (CTF) programs are only as good as the data they consume. Advanced monitoring…
Bad Data Is Costing You More Than You Think
