
Angsuman Dutta
CTO, FirstEigen
Data Ingestion: Pipelines, Frameworks, and Process Flows
Do you know how data is ingested into a system? Can you distinguish between a data pipeline, data framework, and data process flow? Like all organizations, yours relies heavily on data to inform its operating and strategic decision-making. So, you need to know as much as possible about the data that flows into and is used by your organization, including data ingestion, pipelines, frameworks, and process flows.
Quick Takeaways
- Data ingestion is how new data is absorbed into a system.
- A data ingestion pipeline is how data is moved from its original sources to centralized storage.
- A data ingestion framework determines how data from various sources is ingested into a pipeline.
- The data process flow describes how data moves into and through the data pipeline.
What is Data Ingestion? An Easy Explanation
Data ingestion is the process of collecting and importing data files from various sources into a database for storage, processing, and analysis. The goal of data ingestion is to clean and store data in an accessible and consistent central repository, preparing it for use within the organization.
An enterprise system may use data ingestion tools to import data from dozens or even hundreds of individual sources, including:
- Internal databases
- External databases
- SaaS applications
- CRM systems
- Internet of Things sensors
- Social media
Types of Data Ingestion:
- Batch Ingestion: Transfers large volumes of data at scheduled intervals. It is cost-effective and well-suited for periodic updates.
- Real-Time Streaming: Continuously streams data into the system, enabling immediate access and analysis. This is critical for applications like IoT monitoring and live dashboards.
| Feature | Batch Ingestion | Real-Time Ingestion |
|---|---|---|
| Timeliness | Scheduled updates | Immediate updates |
| Resource Use | Lower computational need | Higher computational need |
| Use Cases | Historical reporting | Live dashboards, IoT |
Data ingestion can occur in batches or in real-time streams. Batch ingestion involves transferring large chunks of data at regular intervals. With streaming ingestion, data is continuously transferred into the system. Typically, real-time streaming ingestion delivers more timely data into the system faster than batch ingestion does.
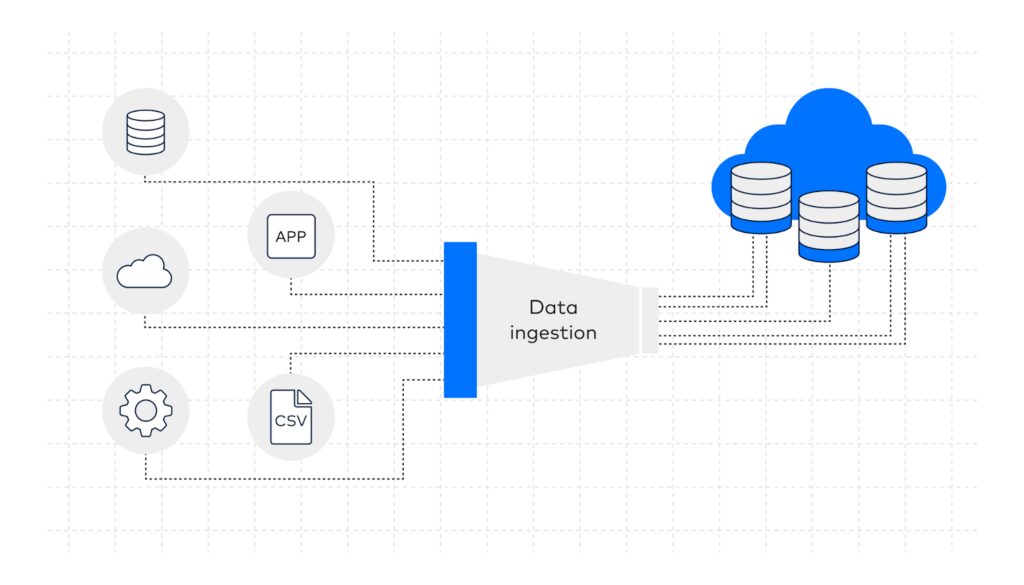
Data Ingestion Pipelines: Understanding Their Role and Functionality
A data ingestion pipeline is a system that connects multiple data sources to centralized storage, such as a data warehouse or lake. It ensures the smooth movement of data, enabling organizations to structure and organize it for analysis.
Streamline Your Data Pipelines and Eliminate Errors with Automated Validation Tools
Designing a Robust Data Ingestion Pipeline Architecture
A well-designed data ingestion pipeline architecture ensures that data flows seamlessly from its sources to its destination. It must handle diverse formats, support scalability, and incorporate monitoring to maintain data quality.
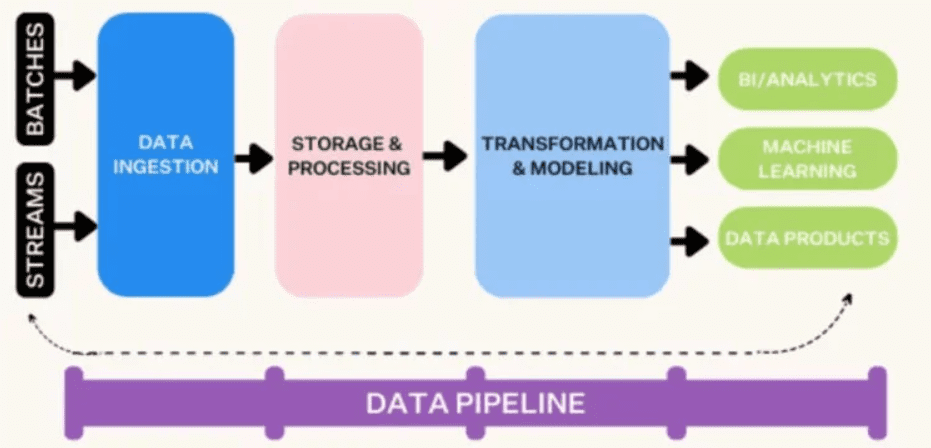
Step-by-Step: How Data Ingestion Process Flows Work
Process Flow:
- Ingestion: Data is collected from various sources.
- Processing: Data is cleaned, validated, and transformed.
- Storage: Data is centralized in repositories for further analysis.
- Analysis: Data is accessed for insights, reporting, or machine learning applications.
A typical data pipeline has six key data ingestion layers
- Data ingestion: This layer accommodates either batched or streamed data from multiple sources.
- Data storage and processing: Here, the data is processed to determine the best destination for various analytics, and then stored in a centralized data lake or warehouse.
- Data transformation and modeling: Given that ingested data comes in diverse sizes and shapes, not all of it is formally structured (with IDC estimating that 80% of all data is unstructured), this layer transforms all data into a standard format for usability.
- Data analysis: This final layer is where users access the data to generate reports and analyses.
Organizations with different data needs may design their data pipelines differently. For instance, a company that only uses batch data may have a simpler ingestion layer. Similarly, a firm that ingests all data in a common format might not need the transformation layer. The data pipeline should be customized to the needs of each organization.
Data Ingestion vs ETL
Data ingestion and ETL (Extract, Transform, Load) are similar processes but serve different purposes.
Data ingestion is a broad term that encompasses the methods used to source, collect, and prepare data for storage or use. It involves bringing data from various sources and making it ready for applications that require it to meet specific formats or quality standards. Typically, the data sources in ingestion processes are not tightly linked to the destination systems.
ETL, on the other hand, is a more specific process used in preparing data for storage in data warehouses or data lakes. ETL involves extracting data from one or more sources, transforming it to meet business requirements, and loading it into a destination system. The goal of ETL is often to enable business intelligence, reporting, and analytics.
Data Ingestion vs Data Integration:
Though related, data ingestion and data integration have distinct roles in a data strategy.
- Data Ingestion: Focuses on importing raw data into a centralized system.
- Data Integration: Combines and harmonizes ingested data from various sources to create actionable datasets.
| Feature | Data Ingestion | Data Integration |
|---|---|---|
| Purpose | Importing raw data | Harmonizing and preparing data |
| Scope | Initial phase | Downstream process |
| Output | Raw, unstructured data | Structured, usable datasets |
Understanding Data Ingestion Frameworks
A data ingestion framework outlines the process of transferring data from its original sources to data storage. The right framework enables a system to collect and integrate data from a variety of data sources while supporting diverse data transport protocols.
As noted, data can be ingested in batches or streamed in real time, each approach requiring a unique ingestion framework. Batch data ingestion, a time-honored way of handling large amounts of data from external sources, often involves receiving data in batches from third parties. In other instances, real-time data is accumulated to be ingested in larger batches. A batch data ingestion framework is often less costly and uses fewer computing resources than a streaming framework. However, it’s slower and doesn’t provide real-time access to the most current data.
In contrast, real-time data ingestion streams all incoming data directly into the data pipeline. This enables immediate access to the latest data but requires more computing resources to monitor, clean, and transform the data in real time. It’s particularly useful for data constantly flowing from IoT devices and social media.
Organizations can either design their own data ingestion framework or employ third-party data ingestion tools. Some data ingestion tools support both batch and streamed ingestion within a single framework.
Understanding Data Ingestion Process Flows
The data ingestion process flow describes exactly how data is ingested into and flows through a data pipeline. Think of the process flow as a roadmap outlining that data’s journey through the system.
When designing a data pipeline, you need to visualize the process flow in advance. This foresight allows the pipeline to be built optimally to handle the anticipated data and its likely usage. Building a pipeline without adequately assessing the process flow could result in an inefficient system prone to errors.
A typical process flow starts at the pipeline’s entry point, where data from multiple sources is ingested. The flow continues through layers of the pipeline as the data is stored, processed, transformed, and then analyzed.
Why High-Quality Data Matters in Data Ingestion?
Throughout the data pipeline and the process flow, constant monitoring is necessary to ensure the data is clean, accurate, and free from errors. To be useful, data must be:
- Accurate
- Complete
- Consistent
- Timely
- Unique
- Valid
Some experts estimate that 20% of all data is bad—and organizations cannot function with poor-quality, unreliable data. So, any data ingestion process must include robust data quality monitoring, often using third-party tools, to identify poor-quality data and either clean or remove it from the system.
Advanced data pipeline monitoring tools, such as DataBuck from FirstEigen, use artificial intelligence (AI) and machine language (ML) technology to:
- Detect any errors in data ingested into the system
- Detect any data errors introduced by the system
- Alert staff of data errors
- Isolate or clean bad data
- Generate reports on data quality
High-quality data helps an organization make better operational and strategic decisions. If the data is of low quality, business decisions may be compromised.
Ensure High Data Ingestion with FirstEigen’s DataBuck
To ensure high-quality data, it must be monitored throughout the data pipeline, from ingestion to analysis. FirstEigen’s DataBuck is a data quality monitoring solution that uses artificial intelligence and machine learning technologies to automate more than 70% of the data monitoring process. It monitors data throughout the entire pipeline and identifies, isolates, and cleans inaccurate, incomplete, and inconsistent data.
Contact FirstEigen today to learn more about improving data quality in the data ingestion process.
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQs
A data ingestion pipeline includes these key steps:
- Data Collection: Gathering data from multiple sources such as databases, SaaS applications, or IoT devices.
- Data Transfer: Moving data to a central system, such as a data lake or warehouse, using batch or real-time ingestion methods.
- Data Validation: Ensuring the data is accurate, complete, and meets required standards.
- Data Storage: Saving the processed data in a repository for analysis or reporting.
A data ingestion framework defines the architecture, tools, and processes used to move data from its sources into a central repository. It supports batch and real-time ingestion, integrates diverse data types, and ensures consistency throughout the pipeline.
The data ingestion flow outlines how data is collected, validated, and transferred to a centralized system. It typically starts with data sourcing, followed by ingestion into a pipeline, validation for quality, and storage in a data lake or warehouse for further use.
Data ingestion is the process of collecting and importing data from various sources into a central system for storage, processing, or immediate use. It ensures that data is ready for applications like business intelligence, analytics, or machine learning.
No, data ingestion and ETL are different processes:
- Data Ingestion: Involves collecting and moving raw data to a storage system.
- ETL (Extract, Transform, Load): Focuses on transforming data into specific formats before loading it into a data warehouse for analytics.
API data ingestion refers to using APIs (Application Programming Interfaces) to collect and transfer data from various platforms, systems, or applications into a central repository. It’s often used for real-time data ingestion where data is continuously streamed from the source.
- Data Collection: Focuses on gathering data from various sources like IoT devices, social media, or databases.
- Data Ingestion: Involves transferring this collected data to a storage system for processing and analysis.
- Data Ingestion: The process of moving raw data from sources to a central system.
- Data Preparation: Involves cleaning, transforming, and structuring the ingested data to make it ready for analysis or machine learning applications.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts



Get Started!
