
Seth Rao
CEO at FirstEigen
What is Data Observability for Data Lakes and How It Transforms Management?
Do you know what data observability is or how to use it with data lakes? Large organizations are increasingly using data lakes to store large volumes of data from various sources, and data observability can make that data more usable. It’s all a matter of creating a more reliable and efficient data pipeline—at which data observability excels.
Quick Takeaways
- Data observability provides more visibility into a data system to create a more efficient data pipeline
- Data lakes store vast amounts of data from a variety of sources in a variety of formats—both structured and unstructured
- Data observability can help manage the different types of data in a data lake
- Data observability standardizes data, speeds up performance, improves reliability, and provides more robust analytics
What is Data observability for Data Lake?
Data observability for a data lake refers to the comprehensive monitoring, management, and analysis of data within a data lake environment. It involves collecting and centralizing telemetry data—such as logs, metrics, traces, and security events—from various sources.
This process ensures data accuracy, reliability, and performance across the entire data ecosystem. By implementing data observability, organizations can proactively detect issues, optimize data workflows, and maintain high data quality within their data lakes, making informed decisions and driving business success.
What is Data Observability?
Data observability is a tool used by data managers and engineers to obtain more visibility into a data system and better manage that system’s data health. It goes beyond traditional data monitoring, which monitors individual pieces of data, to monitor the entire data system. The goal is to ensure higher quality data by creating a more efficient and reliable data pipeline.
Poor data can cost an organization between 10% and 30% of its revenue. For large organizations, that’s an average of $12.9 million a year. Data observability aims to reduce the amount of bad data and its costs.
IT professionals like data observability because it provides a 360-degree view of an organization’s data. Data observability constantly monitors the health of a data system to identify and resolve potential issues in real time. Data engineers also use data observability to predict future data loads and plan for more effective future systems.
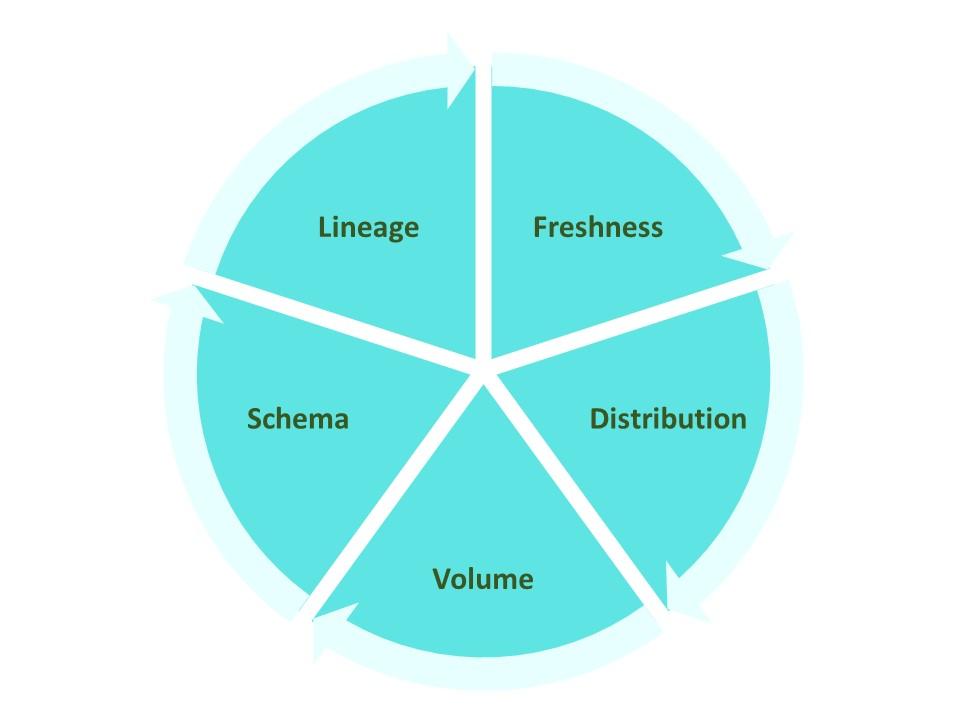
Data engineers cite five “pillars” of data observability that provide actionable insights into a data pipeline. These pillars include:
- Freshness, which tracks how current the data is in a system
- Distribution, which identifies how much data falls outside of an acceptable range
- Volume, which measures the completeness of data records
- Schema, which maps the organization of a data pipeline
- Lineage, which tracks the status of data as it flows through a data pipeline
Transform your data lake with DataBuck. Streamline observability and data quality management
What is a Data Lake?
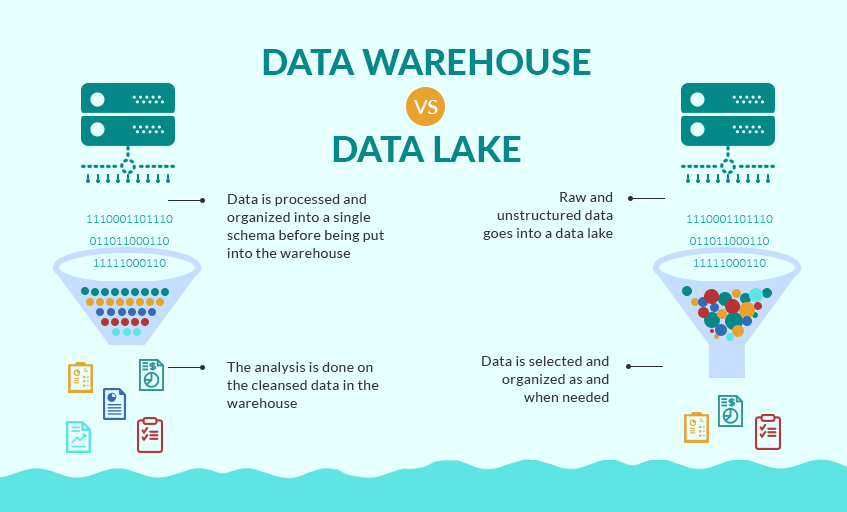
A data lake is like a collection of databases from various sources. It’s a storage repository that holds a large amount of raw data in the cloud. This data is typically stored in its native format, not in any standardized format. The data stays in its native format until it’s accessed.
Data lakes store data in a flat architecture, typically in unorganized individual files. This differs from a data warehouse that organizes data into hierarchical tables. This makes a data lake more flexible regarding data storage and management but more difficult to use for analysis.
Not surprisingly, many organizations use data lakes to store sets of big data. They’re also ideal for storing unstructured or structured data from different sources and schema. The data in a data lake doesn’t have to fit as neatly as in traditional relational data storage.
How Does Data Observability Work for Data Lakes?
Ensuring data quality is a major challenge with the wide variety of data stored in a data lake. This is where data observability shines, as data observability tools manage data health over various types and sources of data—exactly what you have in a data lake.
Data managers use data observability tools to monitor data events from various sources and across various applications. Data observability can monitor all that disparate data to identify, avert, and mitigate data-related issues in real time.
Data observability works to resolve several issues that can affect the quality of your data and the reliability of your operations and decision-making. These include monitoring, standardization, performance, reliability, analytical, and capacity issues.
1. Monitoring the System
Data observability lets data managers and engineers monitor system performance in real time. IT professionals use data observability tools to monitor memory usage, CPU performance, storage capacity, and data flow. This constant monitoring helps improve data flow, avoid congestion, and prevent outages. It also helps even out data workloads and workflow.
2. Standardizing Data
One of the primary characteristics of a data lake is the ability to hold different types of data from many different sources. The challenge is standardizing that data so your organization’s system can use it. Data optimization and data quality management tools work together to convert unstructured data into structured data with the same fields and characteristics as data from internal sources. It also helps to complete incomplete data and eliminate or merge duplicates.
3. Speeding Up Performance Issues
Data lakes often suffer from performance issues. The large volumes of data you must manage can bog down even the most robust systems. Performance is further affected if that data needs to be monitored and cleansed before use.
Data observability can significantly improve access speed to the data in a data lake. Data managers and engineers use data observability to collect large numbers of pipeline events, compare them, and identify significant variances. By focusing on anomalous data, data managers can track down the causes of the irregularities and resolve issues that might slow down the data flow.
4. Mitigating Reliability Issues
Data observability can also help improve system reliability. By constantly monitoring the system status, data observability tools can identify potential issues before they become major problems. Data keeps flowing through the pipeline, so you avoid unwanted downtime.
5. Improving Analytics
By constantly monitoring system performance, data observability generates large amounts of data to feed into your organization’s analytical engine. Artificial intelligence (AI) and machine learning (ML) technologies can better track system usage, allocate resources, streamline data flow, and control costs.
6. Managing Capacities
By constantly monitoring data flow, data observability tools can use AI and ML to predict potential data bottlenecks, redistribute workloads, and better manage system capacities. This helps data flow more smoothly through your system and avoids cost overruns.
Data observability can also forecast future needs and help you strengthen your system for growth. Data growth isn’t slowing anytime soon, and data observability helps you plan for it.
7. Improve Efficiency and Productivity
All of these individual benefits combine to improve your organization’s data efficiency and increase productivity. You’ll have more usable data, more robust analytics, and less downtime. It’s why data observability is essential for data lakes.
Improve data observability in your data lake with DataBuck. Automate monitoring and gain actionable insights
Improve Data Observability for Your Data Lake With DataBuck
If your organization stores data in a data lake, you need robust data observability. When it comes to data observability and data quality management, turn to the experts at FirstEigen. Our DataBuck data quality management solution automates more than 70% of the traditional data monitoring process and uses machine learning to automatically generate new data quality rules. With DataBuck as part of your organization’s data observability platform, you’ll be able to get more actionable insights from the data in your data lake.
To learn more about using data observability for data lakes Contact FirstEigen today.
Check out these articles on Data Trustability, Observability & Data Quality Management-
- What is Data Observability?
- Data Observability for Data Lake, Warehouse, and Pipeline
- Data Testing Vs. Data Observability
- Data Observability Platform
- Data Observability for Data Pipelines
- Differences Between Data Quality and Data Observability
- Observability and Monitoring Tools
- Data Pipeline Observability
- Building a Data Lake
FAQs
Observability data refers to the detailed telemetry data (logs, metrics, traces) collected within a data lake environment. It helps monitor and manage data quality, performance, and reliability across diverse data types, ensuring a healthier data pipeline and more informed decision-making.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

What Do Failed AI Projects Have in Common?
Most AI failures are not model failures — they are data, governance, operational trust, and weak AI-ready foundations. “AI alone is not the solution – trusted, validated, continuously governed data is the…

Why Data Trust Is the Real Foundation of AI Success
Enterprises are racing to adopt AI—LLMs, copilots, and autonomous agents that can trigger actions across systems. But as AI moves…

AI-Powered Data Quality Validation for Smarter AML Detection
Fraud, Anti-Money Laundering (AML) and counter-terrorist financing (CTF) programs are only as good as the data they consume. Advanced monitoring…
Bad Data Is Costing You More Than You Think
