
Seth Rao
CEO at FirstEigen
Self-Service Data Ingestion Made Simple: 3 Essential Steps to Automate and Optimize
How much data does your organization ingest each day? If yours is like most companies, the amount of data you have to deal with is rapidly growing – and becoming a significant problem for your organization. According to the PBT Group, the total amount of data created worldwide is expected to grow to 180 zettabytes per year by 2025, almost three times the data created three years ago. If the amount of data your firm handles is growing at the same rate, you could have issues – especially if you try to manage all that data manually.
An effective way to deal with this growing data problem is to automate your data ingestion pipeline. When you employ self-service data ingestion, you can handle more data more efficiently than you could before. This guide describes how self-service data ingestion is, how it works, and how you can employ it in your organization.
Quick Takeaways
- Data ingestion imports data from multiple outside sources into a data pipeline
- Self-service data integration automates the integration process, enabling nontechnical workers to set up and manage data ingestion and flow
- To employ self-service data ingestion effectively, define your business objectives, design a robust data ingestion pipeline architecture, and leverage AI-driven ingestion service for automation.
What is Self-Service Data Ingestion?
Self-service data ingestion refers to the process of enabling non-technical users to automate the flow of data into a data ingestion pipeline without relying heavily on IT resources. It simplifies how organizations handle the rapidly increasing volume of data and ensures consistent quality throughout the data ingestion process flow.
Data ingestion is how outside data gets into a company’s data pipeline. It’s the process of importing data from multiple sources into a single repository, typically a database, data lake, or data warehouse. From there the data can be sorted, analyzed, and otherwise utilized by users throughout an organization.
How Data Ingestion Works?
Ingestion can involve importing large amounts of data in a single batch or smaller amounts of data in a continuous stream. Batch ingestion is more cost-effective as it works on large collections of data at a single time. Streaming ingestion, however, processes data in real time and can provide faster results.
Data can be ingested from a variety of sources and, depending on the data pipeline, be either structured or unstructured. (According to IDC, 80% of global data will be unstructured by 2025.) Data being ingested is typically monitored for quality and sanitized to work within the organization’s data framework. That can involve cleaning or deleting bad or inaccurate data, as well as transforming different types of data into a standard format of some sort.
Most data ingestion uses the ETL process. ETL stands for Extract, Transform, Load, where data is extracted from multiple sources, transformed into a standardized format, and loaded into a central data repository.

Understanding Self-Service Data Ingestion
Traditional data ingestion methods require manual setup and ongoing monitoring by skilled technical staff. This is both costly and time-consuming.
Self-service data ingestion tools automate a significant portion of the data ingestion process. They make it easy for nontechnical workers to connect incoming data from a variety of sources to a single destination, where it can be analyzed with additional self-service BI tools.
Once set up, self-service data ingestion requires minimal human intervention. It also enables real-time streaming ingestion, as the ingestion tools automatically transform known data types. This results in a more efficient, more scalable, and more reliable way to handle the increasing amounts of data your firm is likely to encounter.
Optimize your self-service data ingestion with AI-powered precision
Self-Service Data Ingestion in 3 Easy Steps
Setting up self-service data ingestion is a three-step process.
1. Identify Desired Business Outcomes
Before creating a new self-service data pipeline, you need to know what business objectives you want to achieve. This will allow you to design a system that leads toward the business outcomes you desire.
That means asking some essential questions before you initiate the process. Consider answering the following questions:
- What are your desired business outcomes?
- Do you want to store your data on-premises or in the cloud?
- How many data sources do you currently utilize – and which are most relevant to your business outcome?
- Do you know what data you need to extract?
- How quickly do you need data available?
- Who will be accessing your data – and how often?
Clear answers to these questions help shape the ideal data ingestion pipeline architecture, tailored to meet your specific needs.
2. Design the Data Pipeline Architecture
Having answered the previous set of questions, you’re now one step closer to designing the best data pipeline architecture for your needs. To choose the right design for your pipeline, you need to consider your desired outcomes, your current and anticipated business requirements, and any constraints (including both technical and financial) on your system.
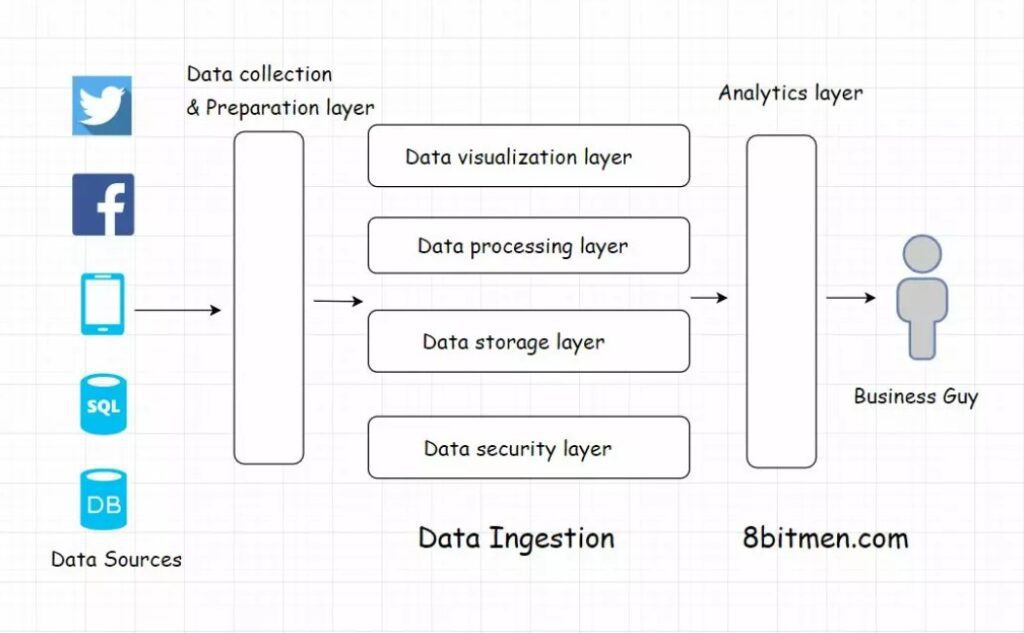
Whichever approach you choose, you need to include six essential layers in your architecture. These layers include the following:
- Data collection and preparation layer – Where the initial data ingestion takes place. It takes data from various sources, identifies and categorizes that data, and determines the appropriate data flow.
- Data security layer – Implements various measures to protect the transfer and storage of the ingested data.
- Data storage layer – Determines the most efficient storage location for the data in your system.
- Data processing layer – Processes the data for use in the following pipeline layers. This layer is the first step in the data analytics process, determining the appropriate destinations for the data flow.
- Data visualization layer – Prepares the data for users to access in an easily understandable, often visual, format.
- Data analytics layer – This enables key analytics based on the data collected.
3. Employ Artificial Intelligence
The final step in implementing self-service data ingestion is automating the process. This is most effectively done by using artificial intelligence, machine learning, and various statistical algorithms. These technologies analyze the data flowing through your system and infer key details about that data.
By continuously learning about the data being ingested, AI can create the rules necessary to automate the flow of data through the pipeline. Instead of requiring IT staff to manually map data sources to standardized file types and locations, AI can automatically determine what data is being ingested and the best ways to manage that data. It’s both faster and more accurate than former manual methods.
The end result is a fully self-serve data ingestion system – and more efficient data management for your organization.
This eliminates the need for manual intervention, reduces errors, and ensures faster delivery of insights. An AI-enabled data ingestion process flow is key to managing data efficiently in dynamic environments.
Discover How DataBuck Reduces Data Errors by 90%
The Final Step: Employ DataBuck for Data Ingestion Monitoring
Data ingestion can fail if you’re dealing with poor data quality. To ensure reliable data ingesting from a number of diverse sources, use FirstEigen’s DataBuck to monitor the quality of the data you ingest. DataBuck is an autonomous data quality monitoring solution that uses artificial intelligence and machine learning to monitor and clean ingested data in real time. Make DataBuck an essential component of your self-service data ingestion process.
Contact FirstEigen today to learn more about self-service data ingestion.
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQs
Self-service data ingestion allows non-technical users to control and manage the process of bringing data into a system without needing IT intervention. It simplifies data handling by empowering business users to set up and monitor their own ingestion workflows, improving efficiency and accessibility.
The data ingestion process flow involves collecting data from various sources, transforming it into a usable format, and loading it into a destination, such as a data warehouse. The steps usually include extraction, transformation, and loading (ETL), ensuring data is ready for analysis.
Data ingestion refers to the process of moving data from various sources into a storage or processing system. Data integration, on the other hand, combines data from different sources into a unified view. While ingestion focuses on collecting, integration emphasizes merging and harmonizing data.
A data ingestion service automates the collection and transfer of data into your storage or processing system. It can reduce the time spent on manual data handling and improve the consistency and availability of data, helping your business make informed decisions faster.
Setting up self-service data ingestion typically involves selecting a data ingestion tool, connecting data sources, configuring data pipelines, and setting up monitoring. These steps ensure that data flows smoothly into your desired system with minimal ongoing maintenance.
Self-service data ingestion helps modern businesses become more agile by reducing the dependency on IT for data operations. It empowers teams to manage data processes independently, leading to faster decision-making and improved data accessibility across departments.
DataBuck improves self-service data ingestion by automating the quality checks and validation processes, ensuring that only accurate and reliable data is ingested. It reduces the manual effort involved in data verification, improving the overall efficiency of the ingestion process.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts



Get Started!
