
Angsuman Dutta
CTO, FirstEigen
5 Proven Strategies to Ensure Data Quality and Trust Across Pipelines, Warehouses, and Lakes
If data is the new oil, then high-quality data is the new black gold. Just like with actual oil, if you don’t have good data quality, you’re not going to get very far. In fact, you might not even make it out of the starting gate. So, what can you do to make sure your data is up to par?

Data lakes, Data pipelines, and Data Warehouses have become core to the modern enterprise. Operationalizing these data stores requires observability to ensure that they are running as expected and meeting performance goals. Once observability has been achieved, how can we be confident that the data within is trustworthy? Does data quality provide actionable answers?
Data Observability has been all the rage in data management circles for a few years now. What is data observability? It’s a question that more and more businesses are asking as they strive to become more data-driven. Simply put, data observability is the ability to easily see and understand how data is flowing through your system. Data Observability is the ability to see your data as it changes over time and to understand how all the different parts of your system are interacting with each other. With observability in place, you’ll have a much easier time tracking down certain types of data errors and solving problems.
But What Makes Up Data Observability? And How Can You Implement It in Your Business?
There is no one definition of data observability, but it usually includes things like detecting freshness, changes in record volume, changes in the data schema, duplicate files and records, and mismatches between record counts at different points in the data pipeline.
There are other factors such as system performance, data profile, and user behavior that can also be monitored. However, these are generally not considered to be part of data observability.
Data Observability Has Primarily Two Limitations:
A) Focus on Just Data Warehouse and Corresponding Process
Most data observability solutions are developed and deployed around data warehouses. This is often too late in the process, though.
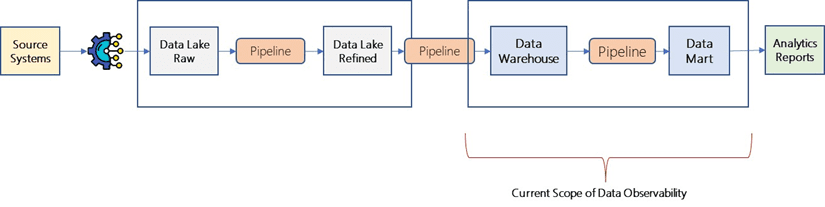
Deploying data observability at the data lake and pipeline is better than just around the data warehouse. This will give the data team more visibility into any issues that might occur during each stage of the process.
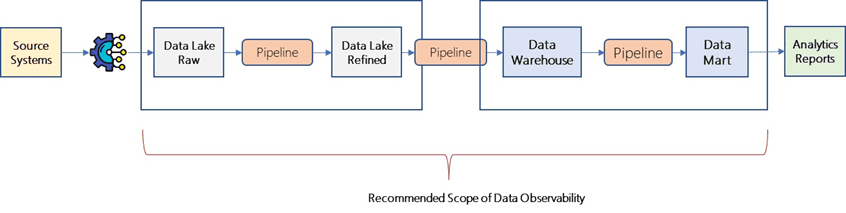
However, different companies have different needs, so it is important to tailor the deployment of data observability to fit the needs of the organization.
B) Focus on Metadata Related Errors
There are two types of data issues encountered by data teams: metadata errors and data errors.
Metadata errors are errors in the data that describe the data, such as the structure of the data, the volume of the data, or the profile of the data. Metadata errors are caused by incorrect or obsolete data, changes in the structure of the data, a change in the volume of the data, or a change in the profile of the data.
Data errors, which are errors in the actual data itself, can cause companies to lose money and impact their ability to make decisions. Some common data errors include record-level completeness, conformity, anomaly, and consistency issues.
There are two types of errors that can cause problems with making decisions and slow down the work process. Data Observability largely addresses Metadata errors. In our estimation, metadata errors only constitute 20-30% of all data issues encountered by data teams.
In theory, data errors are detected by data quality initiatives. Unfortunately, data quality programs are often ineffective in detecting and preventing data issues.
This is often because:
- These programs often target data warehouses and data marts. It is too late to prevent the business impact.
- In our experience, most organizations focus on data risk that is easy to see. This is based on past experiences. However, this is only a small part of the iceberg. Completeness, integrity, duplicate, and range checks are the most common types of checks implemented. While these checks help in detecting known data errors, they often miss other problems, like relationships between columns, anomalous records, and drift in the data.
- The number of data sources, data processes, and applications has increased a lot recently because of the rise in cloud technology, big data applications, and analytics. Each of these data assets and processes needs good data quality control so that there are no errors in the downstream processes. The data engineering team can add hundreds of data assets to their system very quickly. However, the data quality team usually takes around one or two weeks to put in place checks for each new data asset. This means that the data quality team often can’t get to all the data assets, so some of them don’t have any quality checks in place.
What is Data Trustability? And How Can You Implement It in Your Business?
Data Trustability bridges the gap between data observability and data quality. It leverages machine learning algorithms to construct data fingerprints. Deviation from the data fingerprints is identified as data errors. It focuses on identifying “data errors” as opposed to metadata errors at a record level. Data Trustability is the process of finding errors using machine learning, instead of relying on human-defined business rules. This allows data teams to work more quickly and efficiently.
More specifically, the Data Trustability finds the following types of data quality issues:
- Dirty Data: Data with invalid values, such as incorrect zip codes, missing phone numbers, etc.
- Completeness: incomplete Data, such as customers without addresses or order lines without product IDs.
- Consistency: inconsistent Data, such as records with different formats for dates or numerical values.
- Uniqueness: Records that are duplicates
- Anomaly: Records with anomalous values of critical columns
There are two benefits of using data trustability. The first is that it doesn’t require human intervention to write rules. This means that you can have a lot of data risk coverage without significant effort. The second benefit is that it can be deployed at multiple points throughout the data journey. This gives data stewards and data engineers the ability to scale and react early on to problems with the data.
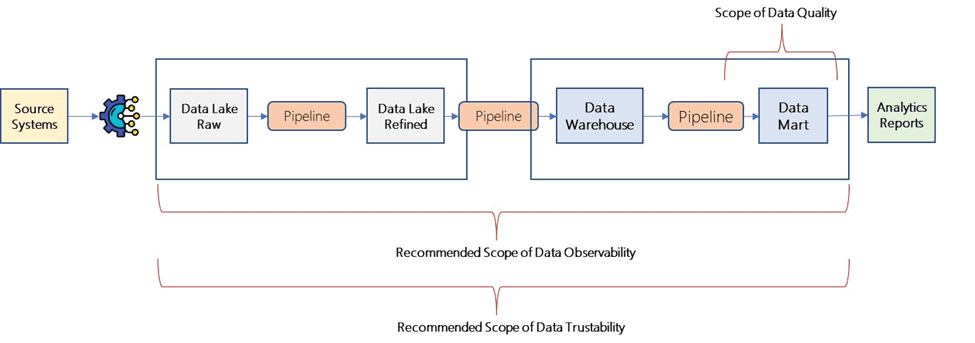
Data Quality Programs will continue to co-exist and cater to specific compliance requirements. Data Trustability can be a key component to achieving high data quality and observability in your data architecture.
Conclusion
High-quality data is essential to the success of any business. Data observability and data quality fall short in detecting and preventing data errors for several reasons, including human error, process deficiencies, and technology limitations.
Data Trustability bridges the gap in data quality and data observability. By detecting data errors further upstream, data teams can prevent disruptions to their operations.
Previously published on dataversity.com
Check out these articles on Data Trustability, Observability & Data Quality Management-
- 6 Key Data Quality Metrics You Should Be Tracking
- How to Scale Your Data Quality Operations with AI and ML?
- 12 Things You Can Do to Improve Data Quality
- How to Ensure Data Integrity During Cloud Migrations?
- Difference Between Data Quality and Data Integrity
- Data Warehouse vs Data Lake vs Data Lakehouse
- Cloud Data Warehouse Architecture
FAQs
Data quality checks ensure that data entering or passing through a pipeline is accurate, complete, and reliable by applying tests like volume checks, uniqueness, and referential integrity.
Improving data quality in a data warehouse involves implementing regular data audits, using data governance frameworks, and employing automated data profiling tools to check for issues like duplicates, null values, and incomplete data.
Data quality in a data lake refers to ensuring that the stored data is accurate, reliable, and suitable for analytics by applying validation techniques like schema enforcement, anomaly detection, and real-time monitoring.
Data completeness is ensured by performing completeness checks during the ETL process, which involves validating that all expected data is present and no records are missing.
Tools like DataBuck, Talend, and Informatica provide automated solutions for running real-time data quality checks, ensuring that the data flowing through your pipeline meets predefined quality standards.
Improving data quality involves implementing governance frameworks, regular data audits, and using automated tools like DataBuck to profile and cleanse the data regularly.
Ensuring data consistency requires using tools that enforce schema validation, performing referential integrity checks, and ensuring proper data governance.
Data quality refers to the accuracy, completeness, and consistency of data stored in the warehouse, ensuring it is fit for reporting, analytics, and decision-making purposes.
DataBuck automates data quality monitoring by using machine learning models to detect anomalies, validate completeness, and check for consistency across various data sources, ensuring that data entering pipelines or stored in warehouses meets business requirements.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts



Get Started!
