
Seth Rao
CEO at FirstEigen
10 Common Data Quality Issues (And How to Solve Them)
Data quality is essential for any data-driven organization. Poor data quality results in unreliable analysis. High data quality enables actionable insights for both short-term operations and long-term planning. Identifying and correcting data quality issues can mean the difference between a successful business and a failing one.
What data quality issues is your organization likely to encounter? Read on to discover the ten most common data quality problems—and how to solve them.
Quick Takeaways
- Data quality issues can come from cross-system inconsistencies and human error
- The most common data quality issues include inaccurate data, incomplete data, duplicate data, and aging data
- Robust data quality monitoring can solve many data quality issues
1. Inaccurate Data
Gartner says that inaccurate data costs organizations $12.9 million a year, on average. Inaccurate data is data that is wrong—customer addresses with the wrong ZIP codes, misspelled customer names, or entries marred by simple human errors. Whatever the cause, whatever the issue, inaccurate data is unusable data. If you try to use it, it can throw off your entire analysis.
How can you solve the problem of inaccurate data? The first place to start is by automating data entry. The more you can automate, the fewer human errors you’ll find.
Next, you need a robust data quality monitoring solution, such as FirstEigen’s DataBuck, to identify and isolate inaccurate data. You can then try to fix the flawed fields by comparing the inaccurate data with a known accurate dataset. If the data is still inaccurate, you’ll have to delete it to keep it from contaminating your data analysis.
2. Incomplete Data
Another common data quality is incomplete data. These are data records with missing information in key fields—addresses with no ZIP codes, phone numbers without area codes, and demographic information without age or gender entered.
Incomplete data can result in flawed analysis. It can also make daily operations more problematic, as staff scurries to determine what data is missing and what it was supposed to be.
You can minimize this issue on the data entry front by requiring key fields to be completed before submission. Use systems that automatically flag and reject incomplete records when importing data from external sources. You can then try to complete any missing fields by comparing your data with another similar (and hopefully more complete data source).
3. Duplicate Data
When importing data from multiple sources, it’s not uncommon to end up with duplicate data. For example, if you’re importing customer lists from two sources, you may find several people who were customers of both retailers. You only want to count each customer once, which makes duplicative records a major issue.
Identifying duplicate records involves the process of “deduplication,” which uses various technologies to detect records with similar data. You can then delete all but one of the duplicate records—ideally, the one that better matches your internal schema. Even better, you may be able to merge the duplicative records, which can result in richer analysis as the two records might contain slightly different details that can complement each other.
4. Inconsistent Formatting
Much data can be formatted in a multitude of ways. Consider, for example, the many ways you can express a date—June 5, 2023, 6/5/2023, 6-5-23, or, in a less-structured format, the fifth of June, 2023. Different sources often use different formatting, so these inconsistencies can result in major data quality issues.
Working with different forms of measurement can cause similar issues. If one source uses metric measurements and another feet and inches, you must settle on an internal standard and ensure that all imported data correctly converts. Using the wrong measurements can be catastrophic—as when NASA lost a $125 million Mars Climate Orbiter because the Jet Propulsion Laboratory used metric measurements and contractor Lockheed Martin Astronautics worked with the English system of feet and pounds.
Solving this issue requires a data quality monitoring solution that profiles individual datasets and identifies these formatting issues. Once identified, it should be a simple matter of converting data from one format to another.
5. Cross-System Inconsistencies
Inconsistent formatting is often the result of combining data from two different systems. It’s common for two otherwise-similar systems to format data differently. These cross-system inconsistencies can cause major data quality issues if not identified and rectified.
You need to decide on one standard data format when working with data from multiple sources. All incoming data must then convert to that format, which can require using artificial intelligence (AI) and machine learning (ML) technologies that can automate the matching and conversion process.
Wish to transform how your organization trusts and acts on data?
6. Unstructured Data
While much of the third-party data you ingest will not conform to your standardized formatting, that might not be the worst problem you encounter. Some of the data you ingest may not be formatted at all.
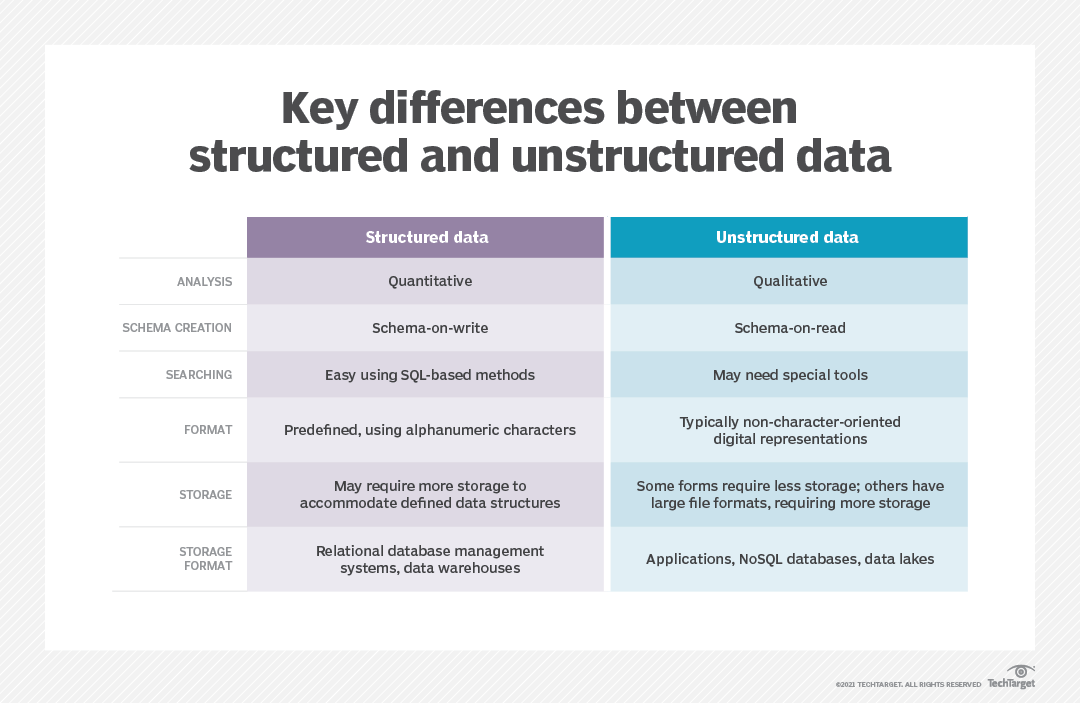
Image Source: Internet
This unstructured data can contain valuable insights but doesn’t easily fit into most established systems. To convert unstructured data into structured records, use a data integration tool to identify and extract data from an unstructured dataset and convert it into a standardized format for use with your internal systems.
7. Dark Data
Hidden data, sometimes known as dark data, is collected and stored by an organization that is not actively used. IBM estimates that 80% of all data today is dark data. In many cases, it’s a wasted resource that many organizations don’t even know exists—even though it can account for more than half of an average organization’s data storage costs.
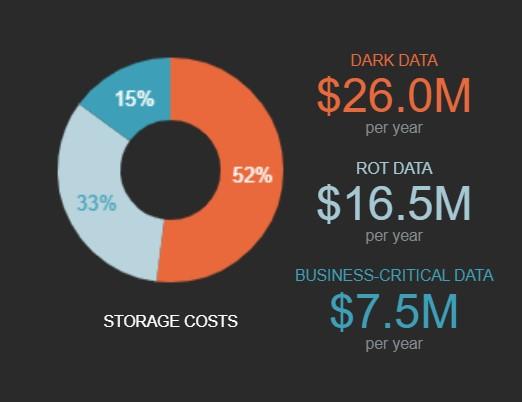
Image Source: Internet
Dark data should either be used or deleted. To do either requires identifying this confidential data, evaluating its usability and usefulness, and making that data visible to key stakeholders in your organization.
8. Orphaned Data
Orphaned data isn’t hidden. It’s simply not readily usable. In most instances, data is orphaned when it’s not fully compatible with an existing system or not easily converted into a usable format. For example, a customer record that exists in one database but not in another could be classified as an orphan.
Data quality management software should be able to identify orphaned data. Thus identified, the cause of the inconsistency can be determined and, in many instances, rectified for full utilization of the orphaned data.
9. Stale Data
Data does not always age well. Old data becomes stale data that is more likely to be inaccurate. Consider customer addresses, for example. People today are increasingly mobile, meaning that addresses collected more than a few years previous are likely to reflect where customers used to live, not where they currently reside.
Older data needs constant culling from your system to mitigate this issue. It’s often easier and cheaper to delete data past a certain expiration date than to deal with the data quality issues of using that stale data.
10. Irrelevant Data
Many companies capture reams of data about each customer and every transaction. Not all of this data is immediately useful. Some of this data is ultimately irrelevant to the company’s business.
Capturing and storing irrelevant data increases an organization’s security and privacy risks. It’s better to keep only that data of immediate use to your company and either delete or not collect in the first place data of which you have little or no use.
Identify and fix 95% of data errors before they impact your business
Use DataBuck to Solve Your Data Quality Issues
When you want to solve your organization’s data quality issues, turn to FirstEigen. Our DataBuck solution uses AI and ML technologies to automate more than 70% of the data monitoring process. DataBuck identifies and fixes inaccurate, incomplete, duplicate, and inconsistent data, which improves your data quality and usability.
Contact FirstEigen today to learn more about solving data quality issues.
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQs
Common data quality issues include inaccurate data, incomplete data, duplicate records, inconsistent formatting, cross-system inconsistencies, unstructured data, dark data, orphaned data, stale data, and irrelevant data. Each of these issues can impact data accuracy and reliability, leading to challenges in making data-driven decisions.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts

AI-Powered Data Quality Validation for Smarter AML Detection
Fraud, Anti-Money Laundering (AML) and counter-terrorist financing (CTF) programs are only as good as the data they consume. Advanced monitoring…
Managing Tariff Implications Through Data Integrity in Global Supply Chains
In today's global marketplace, supply chains span continents. From consumer electronics to industrial machinery, companies rely on global sourcing and...

Data Quality Issues Affecting the Pharmaceutical Industry: Finding a Solution
Pharmaceutical enterprises worldwide navigate a complex ecosystem where vast amounts of sensitive datasets are central to their operations. The data…
Get Started!
