
Angsuman Dutta
CTO, FirstEigen
Why Most Data Quality Programs Fail: Key Insights and Strategies to Succeed
Fortune 1000 organizations spend approximately $5 billion each year to improve the trustworthiness of data. Yet only 42 percent of the executives trust their data. According to multiple surveys, executives across industries do not completely trust the data in their organization for accurate, timely business critical decision-making. In addition, organizations routinely incur operational losses, regulatory fines, and reputational damages because of data quality errors.
Per Gartner, companies lose on an average $14 million per year because of poor data quality.
These are startling facts – given that most Fortune 500 organizations have been investing heavily in people, processes, best practices, and software to improve the quality of the data.
Despite heroic efforts by data quality teams – data quality programs simply failed to deliver a meaningful return on investments.
This failure can be attributed to primarily following two factors:
- Iceberg Syndrome: In our experience, data quality programs in most organizations focus on what they can easily see as data risk based on past experiences which is only the tip of the iceberg. Completeness, integrity, duplicate, and range checks are the most common types of checks implemented. While these checks help in detecting data errors – they represent only 20% of the data risk universe.
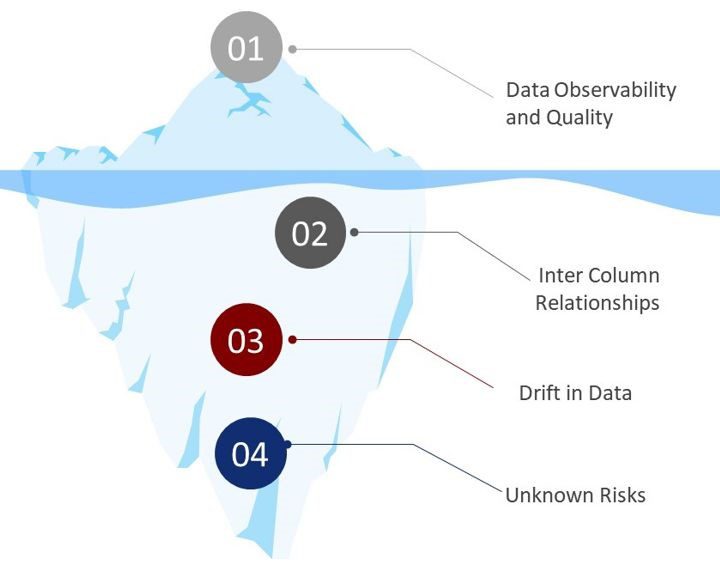
- Data Deluge: The number of data sources, data processes, and applications have increased exponentially in recent times due to the rapid adoption of cloud technology, big data application, and analytics. Each of these data assets and process requires adequate data quality control to prevent data errors in the downstream processes.
While the data engineering teams can onboard hundreds of data assets in weeks, Data Quality teams usually take between one to two weeks to establish a data quality check for a data asset. As a result, data quality teams prioritize data assets for data quality rule implementation leaving many data assets without any type of data quality controls.
DataBuck from FirstEigen addresses these issues for the modern data stack (e.g. AWS S3, GCP, Azure Data Lake) and data warehouse (Snowflake) environment.
Addressing Invisible Risks
DataBuck establishes a data fingerprint and an objective data trust score for each data asset (Schema, Tables, Columns) presents in Data Lake and Data Warehouse.
More specifically, it leverages machine learning to identify data risks through the lens of standardized data quality dimensions as shown below:
- Freshness — determine if the data has arrived before the next step of the process
- Completeness — determine the completeness of contextually important fields. Various mathematical and machine learning techniques should identify Contextually important fields.
- Conformity — determine conformity to a pattern, length, and format of contextually important fields.
- Uniqueness — determine the uniqueness of the individual records.
- Relationship – determine conformity to the intercolumn relationship within micro-segments of data
- Drift — determine the drift of the key categorical and continuous fields from the historical information
- Anomaly — determine volume and value anomaly of critical columns
Addressing Productivity Issues
With DataBuck, data owners do not need to write data validation rules or engage the data engineers to perform any tasks. DataBuck uses machine learning algorithms to generate an 11-vector data fingerprint to identify records with issues.
Summary
Data is the most valuable asset for modern organizations. Current approaches for validating data, in particular Data Lake and Data Warehouses, are full of operational challenges leading to trust deficiency, time-consuming, and costly methods for fixing data errors. There is an urgent need to adopt a standardized ML-based approach for validating the data to prevent data warehouses from becoming a data swamp.
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQs
A data quality management tool ensures the accuracy, consistency, and reliability of data by identifying and fixing errors like duplicates, missing data, or inconsistencies. You need it to improve decision-making, prevent financial losses, and meet compliance standards.
Machine learning automates the detection of data issues, adapting to patterns and identifying errors more efficiently than manual processes. It can continuously improve as data changes, ensuring accurate and up-to-date information.
Data anomaly detection identifies unexpected patterns or outliers in data that may indicate errors or fraud. Catching these anomalies early helps prevent financial losses, regulatory penalties, and other operational risks.
Data lakes store vast amounts of raw data from multiple sources, making them prone to quality issues. Effective data risk management prevents errors from entering downstream processes, ensuring data reliability and preventing the data lake from becoming a “data swamp.”
DataBuck automates data quality checks using machine learning, identifying data risks without the need for manual rules or intervention. This reduces the workload on data teams and ensures continuous monitoring of data assets.
The "Iceberg Syndrome" refers to focusing only on visible data quality issues, such as completeness or duplicates, while ignoring deeper, hidden risks. This leaves organizations vulnerable to errors that can have significant impacts.
DataBuck handles the overwhelming volume of data generated from various sources by automating the validation process. It ensures that data assets across cloud platforms like AWS and GCP are continuously monitored for quality.
Data quality issues can cause incorrect reports, missed opportunities, and regulatory penalties, leading to financial losses. Preventing these errors through automated data checks reduces the risk of costly mistakes.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts



Get Started!
