
Seth Rao
CEO at FirstEigen
7 Data Engineering Principles You Should Be Aware Of
What is data engineering, and why is it important? Data engineering is about turning the data you collect into data you can use. For more effective data management, it’s important to follow seven key data engineering principles—and ensure that your data is of the highest quality possible.
Quick Takeaways
- Data engineering transforms raw data into usable data
- Inaccurate, incomplete, and incorrectly formatted data can result in unusable information
- Businesses must standardize data and centralize processes
- Data engineering is easier when processes are automated
What Is Data Engineering?
Data engineering is a key component of your data management process. It involves transforming raw data into organized data useable by groups and individuals within your organization.
The data engineering process sits between the data creation/capture and analysis processes. It takes data from various sources and formats and cleans, standardizes and stores it in a fashion that is easily searchable and accessible by others.
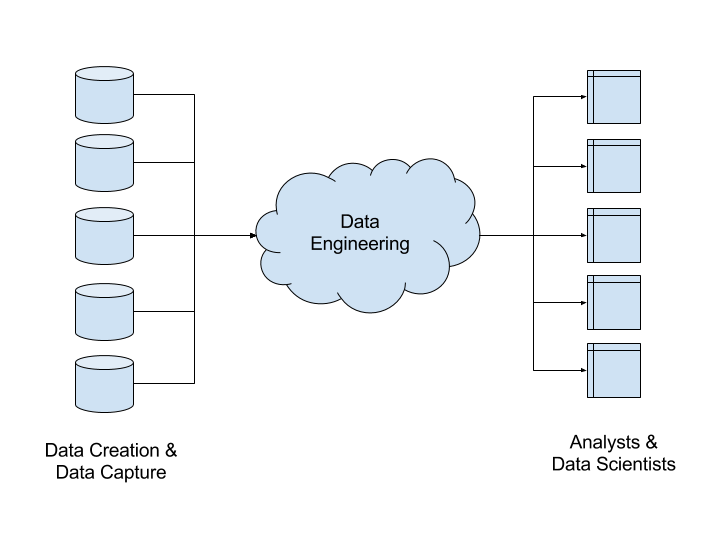
Data engineering is important because of the vast amounts of data collected today and the need to glean actionable insights from that data. The more data an organization collects, the more difficult it is to sift through it to find the specific information you need. You also risk making decisions based on bad or incomplete data.
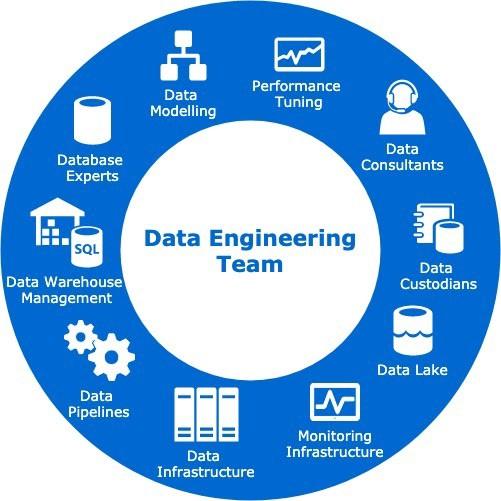
Data engineering addresses all these issues, typically accomplished by a team of data experts working with sophisticated data management tools. The more effective the data engineering team, the more value they can extract from the data your company collects.
(The following video examines what data engineers do.)
7 Key Data Engineering Principles
When you’re looking to embrace data engineering in your organization, you must adhere to a group of core principles. Here, then, are seven key data engineering principles you need to be aware of.
1. You Don’t Need to Keep Everything
Traditionally, companies have collected every last piece of data they could—whether they needed that data or not. Over time, we’ve realized that not all data is necessary, and keeping unnecessary data can result in several issues for an organization.
For one thing, you must secure all the data you collect, whether you use it or not. Securing data takes time and money and lots of storage space (which also costs money), so why spend that time and money securing data you don’t need? It’s better to determine at the outset which data is necessary for your operations and planning and not ingest that data that isn’t necessary.
Keeping too much data also exposes your firm to data privacy issues. Many governments and industries are enacting data privacy regulations with heavy fines for noncompliance. The more customer data you collect, the more at risk you are for noncompliance—and the bigger target you are for malicious actors who want to get their hands on that private data. Limiting the customer data you collect to reduce exposure in these matters is better.
2. Hope for the Best, But Expect the Worst
Although you can hope that the data you enter into your system is high-quality, that doesn’t always happen. In fact, it seldom happens. The data you intake into your system is often incorrectly formatted, incomplete, duplicative, and, to one degree or another, inaccurate. In other words, expect the worst in terms of data quality.
Unfortunately, poor-quality data is more the rule than the exception. Gartner estimates that 20% of all data is bad, and Experian says that bad data affects 88% of companies. Knowing this, expecting the worst makes sense.
Why is poor quality data so common—especially in data input from other systems? There are several potential causes, including:
- Poorly designed input forms
- Sloppy data entry
- Use of unstructured fields when structured data is necessary
- Formatting that has changed over time or that doesn’t match your current standard
- Schemas that have changed over time or that don’t match your current standard
- Old file formats
- Duplication between multiple databases
What should you do when data quality doesn’t meet your expectations?
Well, you can’t use bad data as-is. Injecting inaccurate, incomplete, or incorrectly formatted data into your system can result in all kinds of issues. Instead, you need to analyze all incoming data, identify errors, and delete bad or duplicative data or clean it. You can best accomplish this with a data monitoring and validation solution, such as FirstEigen’s DataBuck.
3. Standardize Your Data
You should normalize any data that does not adhere to your existing standards. This process can involve some or all of the following:
- Transforming incoming schema (fields) and formatting to match internal database standards
- Reformatting data into formats used internally
- Standardizing file and character encoding
- Completing incomplete fields (for example, entering missing city or state info based on existing ZIP codes)
- Comparing data to existing sources and correcting as necessary
4. Centralize Processes and Definitions
It’s imperative to centralize all data-related processes and definitions in your organization. Maintaining data silos in individual departments and locations only increases the complexity of managing and standardizing your data.
To do this, you need to:
- Combine all currently siloed databases into a central data repository
- Create a central data dictionary with standardized schemas
- Establish approved processes that all staff must follow
5. There Will Be Dupes
Ingesting data from multiple sources is bound to result in data duplication. For example, the same customers might exist in different databases, and you don’t want them in your system twice. Correcting this involves identifying duplicates, merging duplicate data, and determining which data is best to use if there is conflicting data.
6. Track All Changes and Retain the Original Data—Just in Case
As you process ingested data, you must track all the changes you make. You need to be able to identify each transformation in case issues arise and diagnose where they occurred. Not every change you make may be warranted or correct, so the ability to backtrack through the changes is important.
It’s also important to keep a copy of the original data separate from the cleansed data in case the new data proves corrupt or unreliable. Comparing the changed data to the original aids in any necessary troubleshooting and enables you to revert to that original data if necessary. Never throw anything away—just isolate it and archive it in case you need it later.
7. Automate as Much as You Can
Any part of the data entry or ingestion program handled manually is prone to human error. The more you can automate data entry or ingestion, the cleaner your data will be.
Similarly, automating the data quality management process can improve accuracy and make a more efficient process. DQM solutions, like DataBuck, use artificial intelligence and machine learning technology to monitor and validate thousands of datasets in mere seconds. Humans can’t work that fast or that accurately.
Let DataBuck Help Support Your Data Engineering Process
When you want to ensure clean, accurate, up-to-date data in your organization, turn to the experts at FirstEigen. Our DataBuck software is an autonomous data quality management solution that automates more than 70% of the data monitoring process. Use DataBuck to support your data engineering process and get the most possible value out of all the data you collect. Contact FirstEigen today to learn more about the data engineering process.
Check out these articles on Data Trustability, Observability & Data Quality Management-
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts



Get Started!
