
Seth Rao
CEO at FirstEigen
How to Achieve AWS Data Quality: 6 Proven Strategies for Cloud Success
Data stored in the cloud is notoriously error-prone. In this post, you’ll learn why data quality is important for cloud data management – especially data stored with Amazon Web Services (AWS).
With every step that error-ridden data moves downstream, those errors get compounded – and it takes 10 times the original cost to fix them. Unfortunately, most companies monitor less than 5% of their cloud data, meaning the remaining 95% is invalidated and unreliable.
How can you improve the quality of your cloud data? It requires automating data quality monitoring, as you’ll soon learn.
Quick Takeaways
- Data quality has six distinct dimensions: accuracy, completeness, consistency, timeliness, uniqueness, and validity.
- High-quality data is essential to provide accurate business analytics and ensure regulatory compliance.
- Cloud data quality is notoriously error-prone.
- The only practical way to ensure data quality is with an AI-driven data quality monitoring solution.
What is Data Quality?
Data quality (DQ) is determined by six primary dimensions. You can evaluate the DQ of your cloud data by tracking these metrics.
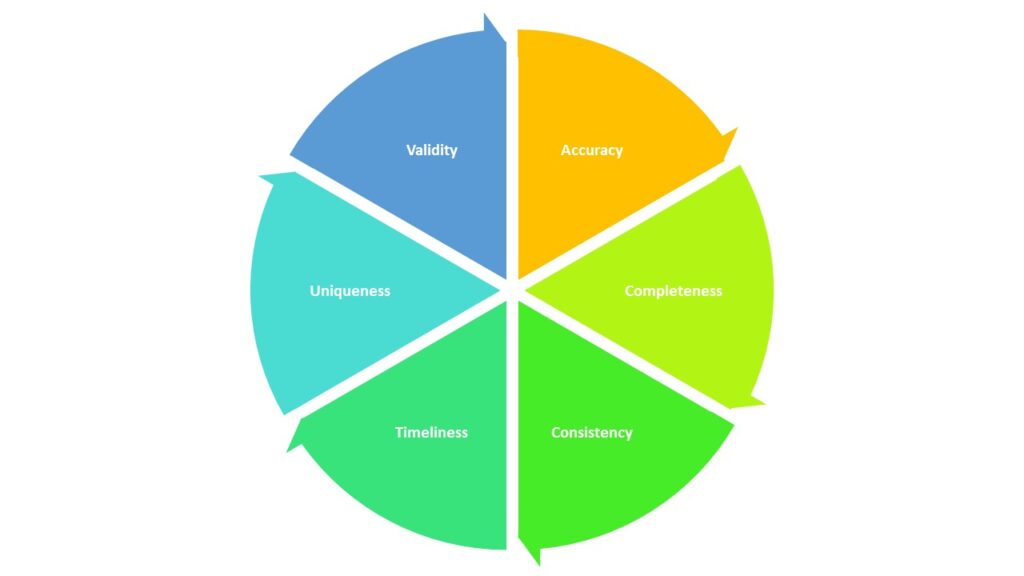
The six dimensions of data quality
Accuracy
Quality data must be factually correct. The data values reported must reflect the data’s actual value. Inaccurate data leads to inaccurate results and bad decision-making.
Completeness
A data set with missing values is less than completely useful. All data collected must be complete to ensure the highest quality results.
Consistency
Data must be consistent across multiple systems and from day to day. Data values cannot change as it moves from one touchpoint to another.
Timeliness
Old data is often bad data. Data needs to be current to remain relevant. Since data accuracy can deteriorate over time, it’s important to constantly validate and update older data.
Uniqueness
Data cannot appear more than once in a database. Data duplication reduces the overall quality of the data.
Validity
Validity measures how well data conforms to defined value attributes. For example, if a data field is supposed to contain date/month/year information, the data must be entered in the correct format, not in year/date/month or some other configuration. The data entered must reflect the data template.
What is AWS Data Quality?
AWS Data Quality refers to the ability to maintain accurate, consistent, and complete data within the AWS ecosystem. As cloud data becomes increasingly vital to business operations, ensuring its quality becomes critical. AWS Data Quality provides organizations with tools to monitor, manage, and improve the accuracy of data within their AWS environment. By leveraging services like AWS Glue Data Quality, businesses can ensure that their data pipelines are functioning with high precision, reducing errors and improving the overall effectiveness of cloud-based data.
The AWS Glue Data Quality service is a key component of AWS’s cloud data strategy, offering automated solutions for maintaining data integrity. Whether you’re using AWS for data storage, processing, or analytics, AWS Data Quality ensures that your cloud data is always clean, reliable, and ready for decision-making. Integrating AWS Glue Data Quality into your workflow is essential for organizations aiming to build a trustworthy data infrastructure.
Enhance Cloud Data Accuracy by 99% With DataBuck’s AI-powered Monitoring
Benefits and Key Features of AWS Data Quality
Integrating AWS Data Quality into your cloud data infrastructure brings significant advantages, especially when combined with AWS Glue Data Quality. Here are some of the top benefits and features of AWS Data Quality:
- Automation: AWS Glue Data Quality automates the continuous monitoring of your cloud data, ensuring that issues are detected and resolved in real-time, reducing manual efforts.
- Seamless Integration with AWS Ecosystem: Since AWS Glue Data Quality is part of the AWS suite, it integrates seamlessly with other AWS services such as Amazon S3, Redshift, and RDS, offering a cohesive and robust solution for cloud data management.
- Improved Data Accuracy: By employing automated data validation, AWS Data Quality ensures that your data is consistently accurate, making it reliable for analysis and reporting.
- Error Detection and Correction: Powered by machine learning (ML) and artificial intelligence (AI), AWS Glue Data Quality helps automatically detect and correct errors in real-time, reducing the need for manual intervention.
- Scalability: Whether your organization manages small datasets or large-scale cloud data, AWS Data Quality can scale to meet your growing needs, ensuring reliable data management at any scale.
- Customizable Rules: AWS Glue Data Quality enables businesses to define custom validation rules to match their specific requirements, ensuring that all data entering the system adheres to the desired quality standards.
Why High-Quality Data is Key to Driving Business Success?
High-quality, reliable data is important for all organizations in all industries. Data can drive revenues and minimize costs – but only if that data is accurate. The impact of data error on analytics can be substantial.
Quality data is also essential in complying with industry and government regulations. For example, banks and financial institutions must demonstrate to regulators that their data programs are accurate, which requires strict data controls. If a bank’s data is inaccurate, it could face hefty fines from regulators. Both Forbes and PwC report that poor DQ is a major contributor to noncompliance.
Ensuring this type of accurate data depends on good data quality systems. Unfortunately, anywhere from 60% to 85% of data initiatives fail because of poor quality data.
Poor data quality data can also destroy business value. Gartner reports that poor data quality costs the average organization between $9.7 million and $14.2 million each year – a number that’s only going to increase as the business environment becomes more complex.
Data Errors in the Cloud
Data warehouses, lakes, and clouds are notoriously error-prone, which can have significant issues for any data-driven project or process. What are the primary data quality challenges you’re likely to encounter? Here’s a short list:
- Missing data
- Unusable data
- Expired data
- Incorrectly or inconsistently formatted data
- Duplicate records
- Missing linkages
Monitoring and ensuring data quality is a complex undertaking. (Gartner outlines 12 actions you can take to improve your DQ – it’s a lot of work!)

Source: https://www.gartner.com/smarterwithgartner/how-to-improve-your-data-quality
Our research estimates that for the average big-data project, 25% to 30% of the time is spent on identifying and fixing these data quality issues. And, if your data is stored on AWS and other cloud providers, the number of data quality issues is significantly higher. Cleaning this “dirty data” is not the responsibility of AWS or other cloud hosts – it’s purely your problem to solve.
Reduce Data Monitoring Efforts by 70% With DataBuck’s Automated AWS Data Quality Checks
How AI Can Help Improve Data Quality in the Cloud?
How can you ensure the quality of the data you use to run your business? While you could try to manually examine each record in your database, that’s practically impossible. Just setting rules for thousands of data tables – each with thousands of columns – is unrealistic and increasingly so as your data evolves.
Manually trying to find errors in large amounts of data is much like looking for the proverbial needle in a haystack. It’s a virtually impossible task when you have large data sets flowing at high speeds from a variety of different sources and platforms.
Consider a bank that onboards several hundred new applications to their IT platform. If there are four data sources per application and 100 checks required per source, more than 100,000 individual checks would be required. It simply isn’t doable.
The only practical way to improve data quality for large data sets is to employ a robust data quality monitoring (DQM) solution powered by artificial intelligence (AI) and machine language (ML) technology. An AI/ML-powered solution provides autonomous data quality monitoring without the need for constant human intervention. The system is not constrained by a fixed set of rules but instead learns and evolves as circumstances change. It also scales as your needs change. The AI-based system is capable of handling the DQ needs of even the largest and most complex organizations.
In short, you can reduce the risk arising from unreliable cloud data and increase your employees’ productivity by leveraging AI-based DQM. Automating this process should be the first step in hardening your organization’s data pipeline.
In the following video, Microsoft’s Aitor Murguzur further discusses how AI can automate data quality.
Let DataBuck’s Autonomous Data Quality Monitoring Ensure Data Quality for Your Cloud Data
FirstEigen’s DataBuck is an autonomous data quality monitoring solution powered by AI/ML technology. It automates more than 70% of the laborious work for data monitoring and provides you with dependable reports, analytics, and models. It also lowers your cost of data maintenance and is fully scalable.
Think of DataBuck as a digital assembly line for creating and enforcing data quality validation rules. DataBuck can autonomously validate thousands of data sets in just a few clicks. It not only automates data monitoring processes but also improves and updates them over time. Contact us today to learn more and begin improving your cloud data quality almost immediately.
Contact FirstEigen today to learn how DataBuck can improve the data quality of your cloud data!
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQs
AWS data quality refers to the accuracy, consistency, and reliability of data stored and processed within AWS services. Ensuring data quality in AWS is crucial for making informed business decisions, improving performance, and reducing errors during data analytics.
AWS Glue Data Quality rules help verify the accuracy and validity of data by setting conditions such as null checks, value range checks, and format validations. These rules ensure that data meets specified standards before being processed further.
AWS data quality rules help reduce data errors, improve decision-making, and maintain compliance. They ensure that the data being used in the analysis is accurate and meets predefined standards.
AWS Glue automates data quality checks by using predefined rules and validations to detect errors. This reduces manual intervention, allowing for faster identification of data issues and improving overall data reliability.
Common AWS Glue data quality rules include null checks, regex validations, value ranges, and custom rules based on specific business requirements. These rules help in maintaining consistent and reliable data.
AWS Glue integrates with services like Amazon S3, Redshift, and Athena to ensure that data moving between these services is validated for quality. This helps maintain the consistency and reliability of the data across the AWS ecosystem.
DataBuck integrates with AWS Glue to provide automated validation and monitoring of data quality. It offers additional layers of protection by checking data across multiple stages to ensure high accuracy and reliability in AWS environments.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts



Get Started!
