
Seth Rao
CEO at FirstEigen
10 Best Data Pipeline Monitoring Tools in 2025
What Are Data Pipeline Monitoring Tools?
Data pipeline monitoring tools ensure the performance, quality, and reliability of data as it moves across systems. These platforms are indispensable for identifying anomalies, detecting bottlenecks, and proactively resolving errors in data flow. With the growing complexity of data pipelines, robust monitoring tools are essential for ensuring seamless operations.
Key Functions of Data Pipeline Monitoring Tools:
- Real-time tracking of data flow and pipeline health
- Detection and notification of data errors or system outages
- Automatic isolation and correction of bad data
- Insights into pipeline performance to support business intelligence
Why Data Pipeline Monitoring Matters?
Modern data-driven businesses rely heavily on data pipelines to integrate, process, and analyze information from diverse sources. Errors in these pipelines can compromise decision-making and operational efficiency. Advanced monitoring tools not only identify issues but also prevent them, enhancing data accuracy and compliance.
How to Evaluate Data Pipeline Monitoring Tools?
When choosing a data pipeline monitoring tool, consider these critical factors:
- Compatibility and Integration: The tool must seamlessly integrate with your existing data infrastructure and handle various data formats.
- Features and Functionality: Key features to look for include real-time monitoring, anomaly detection, automated notifications, and robust visualization.
- Scalability and Performance: The tool should support increasing data volumes and complexity without performance degradation.
- AI/ML Capabilities: Advanced tools like FirstEigen’s DataBuck leverage AI and machine learning to detect errors based on data fingerprints, ensuring proactive monitoring and issue resolution.
- Usability: A user-friendly interface and low-code capabilities are essential for quick adoption by technical and non-technical teams alike.
Top 10 Data Pipeline Monitoring Tools in 2025
1. DataBuck
Key Features:
- AI-powered data validation and anomaly detection
- Automated data quality checks (14 checks, exceeding competitors’ offerings)
- Seamless integration with cloud environments like GCP and BigQuery
- Comprehensive data quality reporting
FirstEigen’s DataBuck stands out as a leader in automated data pipeline monitoring. It uses AI/ML to continuously analyze data, detect anomalies, and correct issues in real-time. With 14 data trustability checks, it surpasses most competitors, making it a top choice for enterprises prioritizing data quality and compliance.
2. Integrate.io
Key Features:
- Low-code/no-code platform for quick pipeline setup
- Real-time monitoring and customizable alerts
- Support for ETL and ELT processes
Integrate.io simplifies data pipeline monitoring with its intuitive interface and robust integrations, making it suitable for teams with limited technical expertise.
3. Fivetran
Key Features:
- Automated data governance and lineage tracking
- Centralized alerts for simplified troubleshooting
Fivetran is ideal for enterprises that need detailed data lineage and governance for better pipeline control.
4. Hevo
Key Features:
- Intuitive dashboards for real-time pipeline visibility
- Preload transformations for flexible data loading
Hevo’s fault-tolerant architecture ensures zero data loss and high reliability, making it a strong contender for real-time pipeline monitoring.
5. Stitch (by Talend)
Key Features:
- Built-in connectors for 140+ data sources
- Advanced data profiling and cleansing features
Stitch works seamlessly with Talend’s suite of tools, ensuring data quality across integrations.
6. Gravity Data
Key Features:
- Real-time monitoring with automated notifications
- Extensive pre-built connectors
Gravity Data ensures reliable pipelines and provides full visibility into pipeline health.
7. Splunk
Key Features:
- AI-powered insights for enhanced security and outcomes
- Powerful dashboards for real-time data visualization
Splunk’s advanced analytics capabilities make it a versatile tool for data pipeline monitoring.
8. Mozart Data
Key Features:
- Clear pipeline observability and dependency tracking
- Fast troubleshooting with intuitive indicators
Mozart Data excels in simplifying complex pipelines with its observability features.
9. Monte Carlo
Key Features:
- Automated field-level data lineage
- SOC 2 Type 2 certified for security
Monte Carlo provides comprehensive data observability with a focus on security and reliability.
10. Datadog
Key Features:
- Customizable dashboards for data flow tracking
- Log analysis for troubleshooting
Datadog integrates seamlessly with data processing platforms, ensuring efficient pipeline monitoring.
What is Data Pipeline Monitoring and Control?
Data pipeline monitoring is a set of processes that observe the data flowing through the pipeline and control the flow when incidents are detected and data quality is compromised. It monitors both the pipeline and the data flowing through it.
A data pipeline monitoring system helps you examine the state of your data pipeline, using a variety of metrics and logs. By constantly observing data in the pipeline and the flow of that data, the system can catch data errors as they happen – and before they affect your operations.
Advanced data pipeline monitoring tools use artificial intelligence (AI) and machine language (ML) technology to sense changes in the data’s fingerprint. It operates automatically to find and correct data errors and notify you and your staff of any issues in the pipeline process.
The best data pipeline monitoring and control tools will do the following:
- Detect data errors as they occur
- Immediately notify staff of data errors
- Automatically isolate or clean bad data
- Alert staff of any system outages or incidents
- Identify any systemic data-related issues
- Generate data quality reports
Without data pipeline monitoring, the risk of bad data infiltrating your system is very high. Some sources estimate that 20% of all data is bad. With data pipeline monitoring, you can be assured that bad data will be immediately identified, and that you’ll be notified if any errors are introduced in the pipeline process.
Why is the Quality of Your Cloud Data Pipeline Important?
All data collected by your company is processed through a data pipeline. A data pipeline is simply a set of processes you use to collect data from various sources, transform the data into a usable form, and then deliver that data for analysis. Data can flow through the pipeline in batches or as a continuous stream of information.
Understanding the data pipeline is necessary to guarantee the data quality your business needs to operate effectively and efficiently. Poor quality data introduced at any pipeline stage can result in poor decision-making, operational chaos, and reduced profit. (According to Gartner, poor data quality costs organizations an average of $12.9 million a year.)
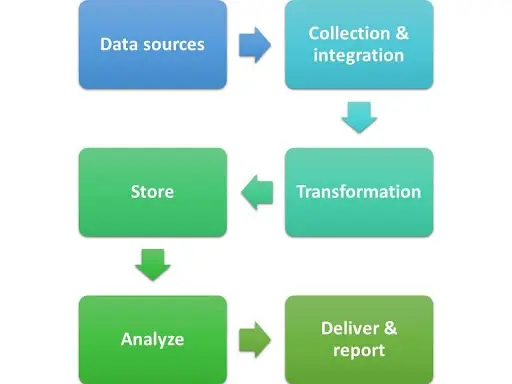
Unfortunately, data pipelines can be subject to several issues that put the quality of your data at risk. Not only can bad data enter the pipeline from the original source, but data can be compromised at any stage of the flow. Data leaks are a common problem, with pipelines dropping data when they get out of sync (“Cloud Data Pipeline Leaks: Challenge of Data Quality in the Cloud”, Joe Hilleary, Eckerson Group).
For all of these reasons, monitoring all data as it flows through the pipeline helps ensure the integrity of that data. From the initial source to final delivery, it’s important to monitor the data to make sure that it is intact and accurate and that no errors creep into the data. This is done by providing visibility into the entire process and examining the quality of the data compared to a series of key metrics.

Understanding Cloud Data Pipeline Monitoring Metrics
Essential to monitoring your data pipeline are four key metrics: latency, traffic, errors, and saturation. Tracking these data pipeline monitoring metrics will ensure the highest data quality at the end of the pipeline.
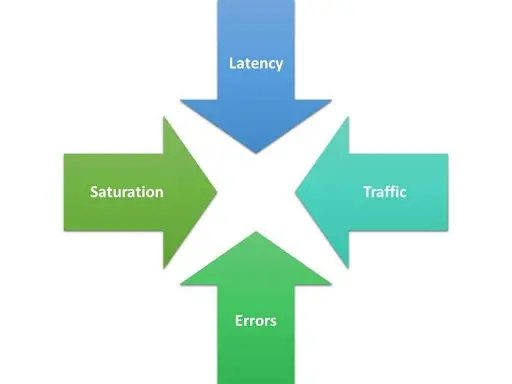
1. Latency
Latency measures how much time it takes to fulfill a given request. In a typical data pipeline, requests should be handled in a matter of seconds. The greater the latency, the less efficient your data pipeline.
2. Traffic
Traffic measures how many data monitoring requests are received over a specified period. This is often measured in terms of requests per second. Your data pipeline must be able to handle your traffic load with a minimal amount of latency.
3. Saturation
Saturation measures resources allocation for your data pipeline system. A saturated pipeline, typically caused by higher-than-expected traffic, will run slower than normal, introducing greater latency into the process.
4. Errors
Errors can be problems with your system or problems with individual data points. System errors make it difficult to process data and fulfill requests. Data errors can result from incomplete data, inaccurate data, duplicative data, and old data.
Choosing the Right Cloud Data Pipeline Monitoring and Control Tools
It’s important to choose a data pipeline monitoring and control tool that not only identifies and cleans bad data, but also integrates with the way your company’s specific data pipeline operates.
Five Essential Qualities
A robust data pipeline monitoring and control tool should possess the following five essential qualities:
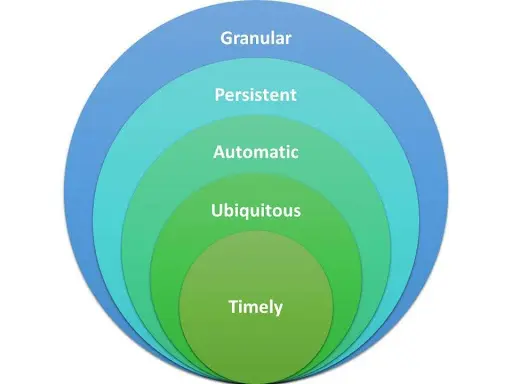
- Granular, to identify specifically which microsegment of your data are the issues occurring
- Persistent, to monitor data over time and also such that the results are auditable in the future
- Automatic, using AI and ML to replace manual monitoring
- Ubiquitous, to monitor data throughout the entire pipeline
- Timely, so alerts are generated in real-time when errors are identified and data flow is stopped when required
Ask These Questions
Taking those essential qualities into account, ask the following questions of any tool you’re considering:
- Does it work with both batch and real-time data processing?
- How much data can it monitor and control during a given period?
- How quickly can it monitor a given amount of data?
- Can it detect when data is flowing?
- Can it detect if data is complete?
- Can it detect if data is accurate?
- Can it detect if data structure or schema has evolved from the past?
- Can it detect if the actual data itself has been changed during the pipeline process?
- Does it operate autonomously with a minimal amount of human intervention?
If you can answer yes to all of these questions, you have a data pipeline monitoring and control tool that can do the job for your organization.
How Does DataBuck Enhance Monitoring Across Data Pipelines?
In the complex world of data management, maintaining data integrity through each phase of the pipeline is crucial. Errors, once introduced, can multiply and affect the entire dataset, leading to costly mistakes and misinformed decisions.
Identifying the Challenge:
- Data Integrity Risks: Errors in data can propagate, affecting everything from analytics to operational decisions.
- Complex Correction Processes: Manually identifying and correcting these errors is time-consuming and prone to further errors.
DataBuck’s Solution: DataBuck steps in as an autonomous Data Trustability validation solution, specifically crafted to enhance monitoring and validation of data across pipelines with the following features:
- Automated Quality Checks:
- Thousands of Checks: Automatically identifies and applies thousands of data quality and trustability checks.
- AI-Recommended Thresholds: Uses AI to recommend precise thresholds for each check, which users can adjust as needed.
- User-Friendly Adjustments:
- Self-Service Dashboard: Allows business users to adjust thresholds without IT involvement, simplifying the data governance process.
- Data Trust Score:
- Comprehensive Scoring System: Automatically calculates a trust score for each file and table, providing a clear metric to assess data quality.
- Proactive Error Prevention: Uses the trust score to prevent poor quality data from moving downstream, safeguarding subsequent processes.
- Seamless Integration and Scheduling:
- Broad Compatibility: Compatible with major ETL tools like Azure Data Factory, AWS Glue, and Databricks via REST API/Python.
- Flexible Scheduling: Integrates with enterprise systems or utilizes built-in scheduling to ensure timely data processing.
Benefits of Using DataBuck:
- Increase in Productivity: Boosts team productivity by over 80% by reducing the time spent on manual data checks.
- Reduction in Errors: Cuts unexpected data errors by 70%, ensuring more reliable data flows.
- Cost and Time Efficiency: Achieves over 50% in cost savings and reduces data onboarding times by approximately 90%.
- Enhanced Processing Speed: Improves data processing speeds by more than 10 times, facilitating quicker decision-making.
By implementing DataBuck, organizations can ensure that their data pipelines not only function more efficiently but also contribute to more accurate and reliable business insights.
Simplify Pipeline Monitoring With DataBuck
FirstEigen’s DataBuck is a game-changer for data pipeline monitoring. Unlike traditional tools, it offers AI-driven insights, automated error resolution, and unmatched data trustability checks. With its ability to detect anomalies and ensure compliance in real-time, DataBuck empowers businesses to focus on growth without worrying about data quality issues.
Experience the difference with FirstEigen’s DataBuck. Schedule a demo to see how it can transform your data pipeline monitoring.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts



Get Started!
