
Seth Rao
CEO at FirstEigen
Building a Unified Cloud Data Lake in 4 Simple Steps
Large, flexible, and powerful.
No, not the Stay Puft Marshmallow Man.
Cloud data lakes can store large amounts of data, are flexible enough to store a wide range of structured and unstructured information, and are a powerful tool for business analytics across diverse industries.
This guide is the only one you’ll need to understand what a data lake is, why you may need one, and how to build and implement your own unified, scalable cloud data lake.
Key Takeaways:
- Data lake vs. data warehouse serve different purposes, but both can coexist.
- You can build a cloud data lake by identifying sources, choosing the right storage, implementing data governance, and leveraging AI and ML.
- Data lake implementation steps involve several stages, from raw data ingestion to full integration with data operations.
What is a Data Lake and Why Does It Matter?
A data lake is a centralized repository that stores structured and unstructured data at scale. Unlike traditional data warehouses, data lakes allow you to store data as-is, enabling real-time analytics, machine learning, and business intelligence. By breaking down data silos, a well-implemented data lake becomes the foundation for modern data-driven enterprises.
Data Lake vs. Data Warehouse: Key Differences You Should Know
Depending on your organization’s needs, you may need a data lake and a data warehouse. They aren’t mutually exclusive, but they share many important similarities and differences.
The aptly-named “data warehouse” is ideal for structured, relational data. In that way, they are similar to their analog counterpart: just like a brick-and-mortar warehouse stores boxes using a consistent, organized system and with a specific purpose in mind, a data warehouse stores relational data that it cleans, enriches and transforms for a specific purpose.
Compare that to a lake: it’s full of fish, frogs, plants, snakes, and maybe even some trash. The water can sometimes be murky, but the lake is varied. A data lake lives up to its namesake: it stores a wide range of structured, unstructured, relational, non-relational, curated, and non-curated data. While a data lake can be disorganized and opaque compared to its cousin, the data warehouse also serves a fundamentally different purpose.
Data warehouses are useful to business analysts and are well-suited to storing relational data from operational databases and transactional systems. They have a faster query time but at the price of more expensive storage.
Data lakes are useful to data scientists (as well as business analysts). Their larger repository of information is ideal for machine learning and storing data from social media, IoT devices, and software applications. While data lakes are slower than data warehouses, storage is cheaper.
You wouldn’t store boxes in a lake like you wouldn’t go fishing in a warehouse. Both data warehouses and data lakes serve essential but separate functions.
How to Build a Data Lake in 4 Steps
Building a data lake involves several crucial steps that ensure scalability and efficiency.
1. Identify Data Sources
Where is your data coming from? Identify your data sources and the frequency with which you receive data. Data lakes can use push-and-pull-based methods of ingesting data.
The biggest paradigm shift between data warehouses and data lakes is that data warehouses start by defining a schema and then fitting data into it, while data lakes work in the opposite direction to ingest data and then create a schema to accommodate it.
Your data sources can be IoT devices, applications, databases, or data warehouses themselves. A data lake doesn’t replace a data warehouse but can utilize the same data for different purposes.
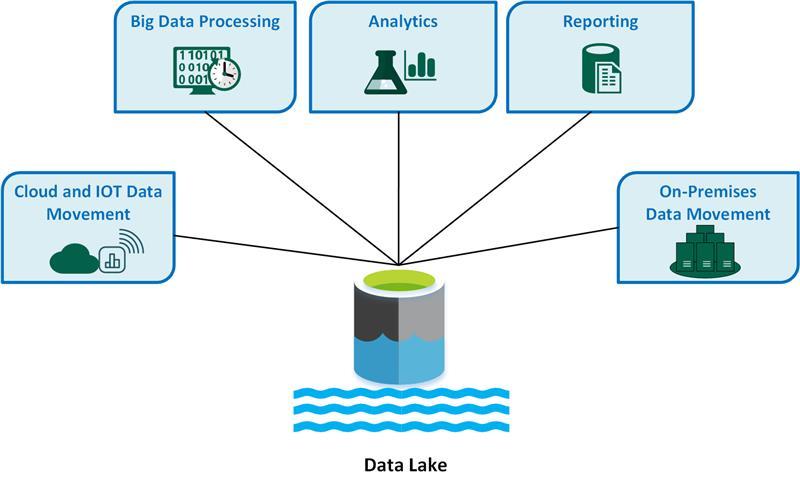
Image Source: Internet
2. Scalable Cloud Data Storage
There are innumerable ways to store your data, but the most popular storage solutions are Google Cloud Storage (GCS), Amazon Simple Storage Service (S3), and Microsoft Azure. These solutions are similar in what they can offer, so how do you choose the right one for you?
If you’re building a data lake, it should be there for the long haul. You want to scale it to meet your needs today and years down the line. Use a single cloud solution for your entire data lake. To create parity and cohesiveness across your organization, use your tech stack’s cloud solution.
3. Creating a Unified Cloud Data Lake
When creating a unified cloud data lake, it’s crucial to bring together diverse data sources into a single, accessible repository. This enables your organization to efficiently manage both structured and unstructured data while ensuring it’s available for analytics.
4. Governance for Cloud Data Lakes
You’ve set up your storage and started to dump data into it—this is fine for a while but can quickly spiral out of control without data governance. While cloud data lakes are flexible enough to ingest all kinds of data, it’s important that you keep your data organized. Once you’ve used your data lake to transform and curate data, business users should feel confident in its integrity.
Data governance ensures that data is secure, accessible, and trustworthy. Building a data lake is about bringing large amounts of data into one place and ensuring that data is accurate and useful so that business users can make data-driven decisions.
Using AI and ML in Data Lakes
While humans find visual patterns, computers excel at finding patterns in large data sets. With the right data governance and error detection, a data lake is a powerful sandbox for AI and ML to explore.
AI and ML are vital to your data lake as tools like DataBuck detect errors early in the process. It can save you countless hours of fixing errors after they’ve had time to propagate and metastasize—by detecting errors early, you can have higher trust in reports and analytics, lower data maintenance costs, and increased efficiency in scaling.
That’s only the beginning of what AI and ML can do with your cloud data lake. One advantage of cloud data lakes over data warehouses is that data lakes collect more data—more types, more formats, and more volume.
This data repository enables AI and ML to perform big, deep learning and interactive analytics. The ultimate use of your cloud data lake is to increase the efficiency and profitability of your organization, and AI and ML are the tools that allow you to achieve this.
Best Practices for Data Lake Implementation
Each component of a data lake works together to create accurate, accessible, actionable data. You can’t have data governance without data sources or data storage without data governance. It becomes a chicken-and-egg scenario, but these four stages of implementation can help you get started.
- Stage 1: Landing zone for raw data. In this stage, your data lake is separate from core IT systems. You aim to capture and store raw data in a cost-effective, scalable iteration.
- Stage 2: Data-science environment. In this stage, you begin data governance. You can begin to conduct tests on the raw data you collected in stage 1, and data scientists can start to build analytics tools.
- Stage 3: Offload for data warehouses. Up until now, your cloud data lake has been experimental. At this stage, you connect your data lake to other data warehouses. You will extract and import large amounts of data to and from your cloud data lake.
- Stage 4: Critical component of data operations. At the final stage of cloud data lake implementation, your data lake is a fully-connected. You implement full governance as data-intensive applications begin to use your data lake.
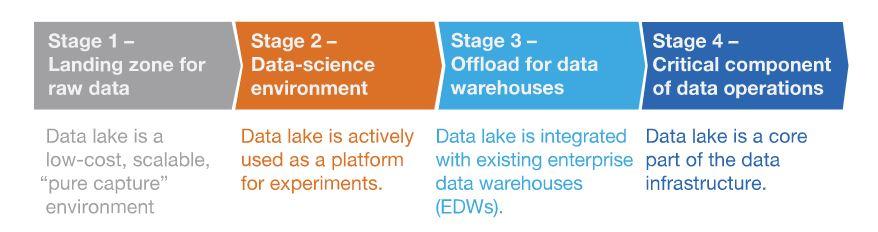
Image Source: Internet
Build a Smarter Data Lake with DataBuck
How Can a Data Lake be Part of a Modern Data Platform?
To integrate a data lake into a modern data platform that caters to evolving business needs, it’s essential to view the data lake as a foundational component. Here’s how this can be achieved:
Centralized Data Repository
- Unified Storage: A data lake acts as a centralized repository where all types of structured and unstructured data can be stored in its raw form. This creates a versatile data environment allowing businesses to collect data from various sources.
Scalability and Flexibility
- Elastic Scalability: As businesses grow, so do their data requirements. Data lakes are inherently scalable, accommodating increasing data volumes without the need for significant infrastructure overhaul.
- Adaptability: They support a wide range of data types and formats, providing flexibility to adapt as business needs and the types of data being collected evolve.
Enhanced Data Processing
- Advanced Analytics: By integrating with tools like Apache Spark and Hadoop, a data lake facilitates complex data processing and analytics. This helps businesses derive actionable insights and support data-driven decision-making.
Integration with BI and AI Tools
- Seamless Connectivity: Data lakes can connect seamlessly with various Business Intelligence (BI) and Artificial Intelligence (AI) tools, like Power BI, Tableau, or AWS SageMaker, enhancing the value derived from collected data.
Support for Real-Time Analytics
- Real-Time Data Streams: Incorporating technologies like Apache Kafka, a data lake can process real-time data streams. This is crucial for businesses needing up-to-the-minute insights.
Future-Proofing the Data Strategy
- Cost-Effectiveness: By reducing the need for redundant data storage systems, data lakes lower costs while maintaining high accessibility.
- Support for Innovation: As new technologies and data needs emerge, a data lake offers the flexibility to evolve without requiring a complete overhaul of the data infrastructure.
In summary, by being a versatile, scalable, and cost-effective solution, a data lake becomes a vital part of a modern data platform, ready to meet the dynamic needs of any business.
Ensure Data Accuracy for Better Insights
How DataBuck Ensures Data Accuracy in Your Data Lake
The risk of error grows with each piece of data your cloud data lake processes. Most companies monitor less than 5% of their data, resulting in expensive and frustrating mistakes. You don’t have to settle for 5%.
FirstEigen created DataBuck to eliminate unexpected errors and monitor data autonomously. As your business changes and grows, DataBuck can scale with you, ensuring you have access to valid, helpful data at all times.
DataBuck has helped organizations from top banks worldwide to leading telehealth providers and even municipal governments of major cities. To see how we can help you, contact us today to learn more.
Conclusion: Achieve Data Lake Excellence with Proven Strategies
Building a scalable cloud data lake requires a careful balance of data storage, governance, and modern technology like AI and ML. By following the data lake implementation steps, your organization can gain access to vast amounts of valuable data, enabling advanced analytics and machine learning applications.
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQs
While both store data, a data lake holds raw, unstructured data from multiple sources, making it ideal for data science and machine learning. A data warehouse, on the other hand, stores structured data in an organized format, optimized for fast querying and reporting. The main difference is in data organization and purpose—data lakes offer flexibility, whereas data warehouses provide structure.
The essential steps to build a data lake include:
- Identifying your data sources (IoT devices, applications, etc.).
- Choosing scalable cloud storage like AWS S3 or Google Cloud.
- Implementing robust data governance practices.
- Leveraging AI/ML tools for analytics and automation.
- Regularly monitoring and validating data quality.
Using a cloud data lake provides benefits like:
- Unlimited scalability to handle vast amounts of data.
- The ability to store structured and unstructured data in one place.
- Integration with AI and machine learning for advanced analytics.
- Cost-effective storage compared to on-premise solutions.
- Easier accessibility for teams across your organization.
Ensuring data quality in a data lake requires implementing strong data governance policies, automating data validation processes, and continuously monitoring for errors. Tools like DataBuck use AI to detect issues early, maintaining high-quality data throughout the lifecycle.
Some common challenges when creating a data lake include:
- Managing data governance and security across vast datasets.
- Ensuring high data quality and avoiding data swamps.
- Integrating the data lake with existing systems and workflows.
- Selecting a storage solution that is scalable and cost-effective.
- Maintaining data accessibility for users across different departments.
AI and machine learning are pivotal in extracting actionable insights from large datasets within a cloud data lake. They can detect patterns in massive data volumes, improve decision-making, and help businesses optimize their operations by automating analytics and predictive modeling.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts



Get Started!
