
Seth Rao
CEO at FirstEigen
Azure Data Factory and Synapse: Powering Data Quality with Advanced Tools and Services
Any enterprise that relies on raw data from multiple sources can benefit from the data ingestion features of Microsoft’s Azure Data Factory. Coupled with Azure Synapse Analytics, users can extract detailed analysis and insights from that data.
Azure Data Factory and Synapse both require clean, high-quality data, which isn’t always available when ingesting data from disparate sources. So, how can you ensure high-quality data for your data pipeline and analysis? Fortunately, FirstEigen offers a version of its DataBuck data quality tool designed to work with Azure Data Factory and Synapse, ensuring reliable insights from all types of data.
Quick Takeaways
- Azure Data Factory, a cloud-based ETL service, integrates data from multiple sources.
- Azure Synapse Analytics works with Azure Data Factory to provide analysis and insights from ingested data.
- Azure Data Factory and Synapse Analytics depend on high-quality data to provide reliable results—but do not include data quality monitoring functionality.
- To ensure Azure data quality, FirstEigen is now offering the DataBuck Essential Quality Module for Azure.
What is Azure Data Factory?
Azure Data Factory is a cloud-based data integration service provided by Microsoft. It serves as an Extract-Transform-Load (ETL) tool, enabling the integration of data from various sources into a unified data store.
ETL is a process that extracts data from the original source, transforms it into a predefined format, and then stores it in a database, data warehouse, or data lake. This differs from the Extract-Load-Transform (ELT) process, which loads the data first in multiple formats and only transforms it when it needs to be used.
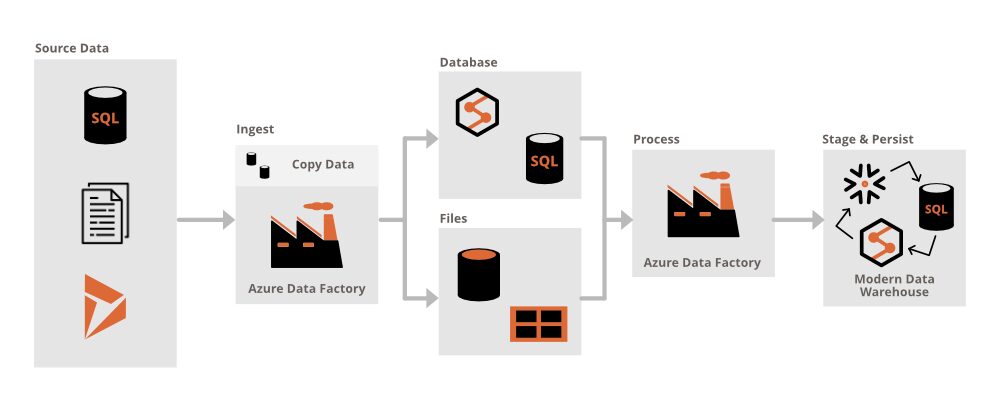
ADF ingests and transforms data of various types, sizes, and formats. It employs a code-free user interface, enabling users to easily create complex data-driven workflows, called pipelines, and transform data at scale. The transformed data can then be published to Azure Synapse Analytics for further analysis via various business intelligence (BI) applications.
Azure Data Factory comprises a series of interconnected components, including:
- Activities—Actions performed on selected data.
- Pipelines—A grouping of activities that perform a task.
- Linked services—Used to connect ADF to other sources.
- Datasets—Points that reference data.
- Dataflows—Processes that develop graphical data transformation logic.
- Integration runtimes—Infrastructure that provides data flow, data movement, and other capabilities across different environments.
As a cloud-based service, ADF does not require on-premises servers, reducing the hardware load for participating enterprises. This also makes ADF more cost-effective and scalable than competing solutions.
What is Azure Synapse Analytics?
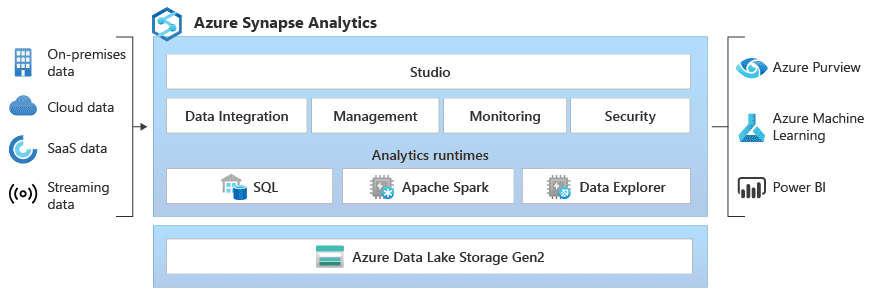
Azure Synapse Analytics is an enterprise analytics service that helps users gain insights from data. It uses SQL technology to extract insights across multiple data stores, including data lakes, data warehouses, and operational databases.
Transform Your Azure Pipeline with 1,000+ AI-Driven Validations in 3 Clicks
What is Azure Synapse Analytics Used for?
With Azure Synapse Analytics, users can query both relational and nonrelational data using their preferred language. It leverages both predictive and prescriptive analytics, as well as descriptive and diagnostic analytics.
Azure Synapse Analytics consists of four key components:
- Synapse SQL: A dedicated pool of SQL serves that function as the backbone for all analytics data storage and enable users to execute T-SQL queries. Its serverless model uses data visualization to gain insights without the need to set up a data warehouse.
- Synapse Pipelines: Uses ETL to integrate data from disparate sources.
- Apache Spark: Uses scalable high-performance computing resources to develop machine learning solutions and big-data workloads.
- Synapse Link: Provides real-time operational analytics from internal data sources.
How Do Azure Data Factory and Synapse Ensure Data Quality and Validation?
To obtain optimal insights from Azure Synapse Analytics, you need high-quality data. Ingesting low-quality data can result in incomplete or faulty analysis, affecting a company’s decision-making process.
So, all ingested data, whether originating internally or externally, as well as all stored data, needs to be monitored for quality. Data quality monitoring evaluates six key metrics of all data:
- Accuracy: The data is correct.
- Completeness: All data fields are fully populated.
- Consistency: Similar data is identical across multiple sources.
- Timeliness: Data is recent.
- Uniqueness: Data is not duplicated.
- Validity: Data is properly formatted.
Data that fails in any of these measurements must be isolated from the main data. It can then be deleted or cleaned, if possible.
While Azure Data Factory enables a transparent 360-degree view of the data pipeline, it does not offer data quality monitoring functionality. Instead, Microsoft depends on partners, such as FirstEigen, to provide solutions for Azure Data Factory data quality and validation.
FirstEigen’s DataBuck Essential Data Quality Module is Now Available in Azure Market Place
To ensure high-quality data for Azure Data Factory and Synapse Analytics, FirstEigen has introduced its new DataBuck Essential Data Quality Module. This data quality tool is now available on the Azure Market Place.
The DataBuck Quality Module is a data tool that enables Azure Synapse data quality professionals to autonomously identify data errors within the Azure ecosystem. It uses artificial intelligence (AI) and machine learning (ML) technologies to detect data quality errors, with no coding required. The Module scans data assets within the Azure ecosystem, identifies inaccuracies that may affect the data pipeline, and flags them to provide data owners with the most dependable and accurate data.
DataBuck also automates the tedious and time-consuming process of creating rules and mechanisms to detect potential data issues. It can be programmatically integrated into any data pipeline and works with various platforms, including Azure Data Lake, Databricks Delta Lake, Cosmos DB, Snowflake, Synapse, and MSSQL.
When the software identifies a critical issue, it automatically alerts data engineers and teams. It also sets thousands of validation checks for continuous data testing and data matching, monitoring health metrics and Data Trust Scores. DataBuck’s machine learning algorithms generate an 11-vector data fingerprint that quickly identifies records with issues. This approach ensures customers have full transparency and more trust in their reports, analytics, and models.
FirstEigen estimates that using the DataBuck Quality Module for data maintenance can lower an organization’s costs by $1 million for every $100 million in revenues. It can also increase efficiency in scaling data quality operations by a factor of ten.
FirstEigen’s DataBuck Data Quality and Data Trustability Module offers companies an alternative to Informatica Data Quality (IDQ) and can replace Informatica DQ by providing autonomous solutions that don’t require any coding. The resulting data can be directly integrated into Informatica Axon, Alation, or any other data governance tool.
Improve Azure Data Accuracy by 90% with Automated Validation
You can learn more about the DataBuck Data Quality Module by clicking here or by visiting its listing on the Azure Market Place.
Contact FirstEigen today to learn more about the DataBuck Data Quality and Data Trustability Module for Azure.
Check out these articles on Data Trustability, Observability & Data Quality Management-
FAQ
Azure Data Factory helps manage data quality by automating data validation and cleaning processes during data integration. It ensures data flows are accurate and reliable across the pipeline.
Azure Data Factory integrates with Synapse Analytics to provide data validation, monitoring, and error handling. It helps ensure that data is accurate when moving between different systems in the Synapse environment.
Azure offers tools like Data Factory for pipeline validation and Azure Purview for data governance. These tools automate data checks, clean data in transit, and monitor the quality of datasets.
Azure provides services like Data Factory for validation, Purview for data governance, and Monitor for tracking data flow performance, ensuring high-quality data across its systems.
Best practices include setting validation rules for data pipelines, using data cleansing features, and regularly monitoring data flows for errors or anomalies.
Azure Data Factory can check data quality in real time by integrating with services like Azure Monitor, enabling immediate validation and error detection as data moves through the pipeline.
Challenges include inconsistent data formats, data silos, and handling large-scale data validation. Azure Data Factory helps by providing automated tools to standardize and clean data across systems.
DataBuck integrates with Azure Data Factory to automate data quality checks using AI. It ensures accurate data by detecting anomalies and errors in real time, making data reliable before it reaches storage.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts



Get Started!
