
Seth Rao
CEO at FirstEigen
What an Automated Data Validation Tool Can Do For Operational and Transactional Data
Do you know how an automated data validation tool can benefit your business? Data validation ensures that you’re always working with clean and accurate data. You can try to validate your data manually but automating data validation is a much better approach for most businesses. Read to learn why.
Quick Takeaways
- Data validation ensures that data is current, conforms to standards, consistent, complete, unique and accurate.
- Automated data validation is faster and more accurate than manual methods.
- Automated data validation tools catch more existing errors and eliminate human error.
- Automating data validation standardizes and streamlines the data pipeline, ensures high-quality data while reducing costs.
What is Data Validation, and Why is it Important?
Data validation is any process that ensures that data is error-free and fit for use. The process involves checking many dimensions of data to ensure it is usable. Different scholars of Data Quality have defined different sets of dimensions, in many different ways (Ref-1). Based on our experience working with many Fortune -1000’s companies, the list below is a useful summary for the actual practitioner in the real world for operational and transactional data (this list can be slightly different for Master Data).
- Current (fresh or latest) – This is also referred to as Timeliness in some literature. This is to ascertain that the data being used is the latest and most relevant data. There is a huge risk of multiplying errors when cascading ETL jobs pick up older outdated data and move them through the data pipeline. All intermediate data repositories get populated with errors in the process.
- Conforms to standards – Check that every field conforms to the correct type and format of data. For eg., a date field cannot be an integer, or a 2 character state code cannot have 3 letters in it or a social security number cannot be an alpha-numeric.
- Consistent – Ensure consistency in (1) volume of data being processed, (2) structure/schema of the data, and (3) between different data repositories where data is stored. When the data structure changes, i.e., columns are added, deleted or rearranged, it causes havoc in downstream data processes. Errors get magnified with every subsequent ETL job that depends on consistency of data structure.
- Complete – All the critical fields in a record are populated and other fields, that could have nulls, are within the threshold of acceptability.
- Unique (no duplicates) – Ensure there are no duplicate records.
- Accurate – Is the behavior of data within expected bounds? This encompasses many different types of anomalies.
- Anomalous Value – This is the most common one users intuitively understand. It refers to ensuring the value in a field is within acceptable limits.
- Anomalous Micro-Volume – Checks if the volume of records within a microsegment of data of acceptable levels.
- Anomalous String – Some fields or columns can only be populated by pre-determined lists (e.g., State code). Check if new elements are appearing or the expected elements are missing. This is also referred to as Drift in the data.
- Anomalous Inter-column Relationships – Multi-column relationships exist within all data sets. For eg., ‘IF Col-A= …, AND Col-B= …, THEN is Col-C=…’. In the auto insurance space this can be something like: If the claim is for an accident, then the claim date must be after the policy active date and before the policy expiry date. If not, then the record has errors.
- Anomalous Microsegment – Every data set has 1,000’s of microsegments or microcosms that have uniquely different behavior. A small change to an upstream ETL job can change the data, in not just one record, but in an entire microsegment. Users must be vigilant about the behavior of entire groups of data.
If your organization doesn’t validate its data, you could end up with records that have missing or incomplete fields, duplicate records, records with the wrong data types entered, and data that simply is incorrect. According to Salesforce, bad data costs companies more than $700 billion annually. That averages out to 30% of an average company’s revenue. In addition, Gartner estimates poor data quality causes 40% of companies to fail to achieve their business objectives.
The Problem With Validating Data Manually
Organizations can try to validate data manually. The problem with manual data validation is that it is extremely labor-intensive. Workers have to examine each record to ensure that the data is entered properly, then either send those records back to be completed or extract them from the system. Workers must also check the accuracy of key operational and transactional information, then correct any fields entered incorrectly.
Validating data manually is so much work that few firms bother to check every single piece of data. Instead, most organizations doing manual data validation only randomly spot-check their data, enabling a large amount of bad data to slip between the cracks. Human data checkers also make their own human mistakes, potentially introducing a new set of errors to the data.
Reduce Data Errors by 80% with AI-Powered Validation- Start in Just 3 Clicks
How Automated Data Validation Works?
Automated data validation uses AI/ML and other advanced technologies to automatically identify low-quality data. When bad data is identified, the right stakeholders are alerted, cascading ETL jobs are suspended, reports and advanced analytics are stopped. Once the data is cleansed, the processes can be restarted. For operational and transactional data it is not recommended that an AI/ML software clean or delete data on its own without human input. This ensures overall high data quality with minimal human intervention.
We often find companies struggling to get a handle on their data validation processes because they try to do everything at once. Instead break down the data validation journey into a sequence of victories to build on. This keeps your budget under control and gains management trust. Start with Ingestion Validation and Systems Risk Validation.
Ingestion Validation
- Current (fresh or latest)
- Consistent – Ensure consistency in (1) volume of data being processed and (2) structure/schema of the data.
Systems Risk Validation
- Complete
- Unique (no duplicates)
- Conforms to standards – correct type and format of data (length, data type, pattern)
In Fortune-2000 companies we have found these contribute to a majority of errors the business users experience.
Companies should create their own validation rules that help identify data that violates their business expectations. But, it should be a second step. Some validation tools can generate new rules automatically, learning from historical data, patterns and trends.
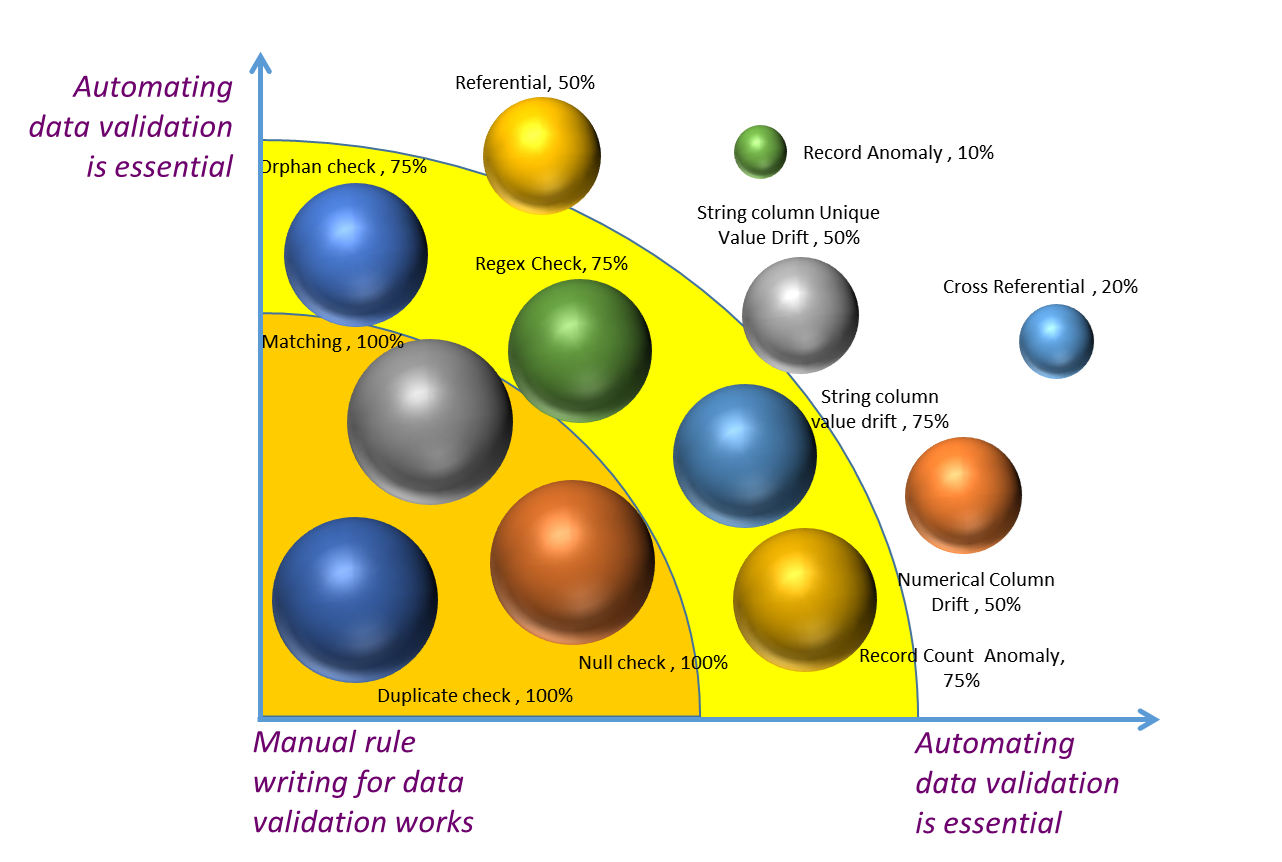
In all, automated data validation tools examine various characteristics to identify poor-quality data that needs to be cleansed. A tool should be able to perform the following tasks to ensure you receive only the highest-quality data:
- Duplicate checks
- Matching checks
- Orphan checks
- Null checks
- Various types of statistical analysis
6 Important Benefits of Using an Automated Data Validation Tool
The more data a company uses, the greater the benefits of automated data validation, and most businesses and organizations can realize multiple advantages from automating data validation.
1. Validates More Data Faster
An automated data validation tool can validate considerably more data much faster than manual validation methods. While it might take several minutes to manually validate a single record, an automated process can validate thousands of datasets in mere seconds. If your organization processes a large amount of data regularly, there is simply no comparison between the efficiency of an automated data validation tool and doing the same task manually.
2. Catches More Errors
Automated data validation tools are also more effective than manual methods especially when the data is dynamic, complex, inter-connected and comes from a variety of sources. All operational and transactional data originate in a dynamic environment and processes with all these characteristics. It is unrealistic to expect traditional static data validation approaches to trap dynamic data errors. An automated tool that organically evolves with the data catches a significantly higher percent of bad records than even your best employees can manually.
3. Reduces Human Interaction
An automated data validation solution eliminates the need for much manual labor. Using an automated system lets you reallocate those resources elsewhere instead of employing a team to sift through incoming data. The automated data validation tool replaces multiple employees performing tedious tasks.
4. Reduces Human Errors
Automated tools also don’t make mistakes like human employees do. Employees manually validating your data skip over some errors and tend to introduce new errors of their own. Using an automated validation tool can reduce or totally eliminate human errors from the process.
5. Guarantees High-Quality Data
The goal of any data validation scheme is to ensure that you’re using high-quality data. This is where automated data validation shines. By catching more errors in existing data and introducing fewer new errors, you end up with higher-quality data than was possible with manual validation.
In addition, automated data validation ensures that your datasets are fully up-to-date. Automated validation tools always check data against the most recent public and private databases. You end up with fewer outdated customer addresses and higher-quality results.
6. Reduces Costs
Automating data validation significantly reduces your data management costs. By reducing the need for human workers, you have lower labor costs. Having more accurate customer data also reduces sales and marketing waste, reducing costs in those areas as well.
Eliminate 80% of Manual Checks with Automated Data Validation
Let DataBuck Automate Your Data Validation
When you want to automate your organization’s data validation and ensure a constant stream of high-quality data, turn to DataBuck from FirstEigen. DataBuck is an autonomous data quality management solution powered by AI/ML technology that automates more than 80% of the data monitoring process, including data validation. It can automatically validate thousands of data sets in just a few clicks and constantly monitor data fed into and through your data pipeline.
Contact FirstEigen today to learn more about FirstEigen’s automated data validation tools!
Check out these articles on Data Trustability, Observability & Data Quality Management-
- 6 Key Data Quality Metrics You Should Be Tracking
- How to Scale Your Data Quality Operations with AI and ML?
- 12 Things You Can Do to Improve Data Quality
- How to Ensure Data Integrity During Cloud Migrations?
- Data Pipeline Automation Tools
References
1. “Dimensions of Data Quality: Toward Quality Data by Design”, Y. R. Wang and L. M. Guarascio
FAQ
An automated data validation tool checks the accuracy and consistency of data automatically. It helps ensure data is correct by applying validation rules, saving time compared to manual checks.
Data validation improves operational data quality by catching and correcting errors before they impact processes. It ensures only clean, accurate data flows into systems, leading to better decision-making.
Automated data validation for transactional data reduces manual effort, speeds up the process, and ensures that errors are identified quickly. This leads to more accurate transactions and reliable data records.
Automated data validation reduces errors by automatically checking data for inconsistencies, missing values, or incorrect formats. This prevents faulty data from entering workflows, minimizing risks and processing delays.
An automated data validation tool identifies errors such as missing data, duplicate entries, incorrect formats, and data mismatches. It ensures that only valid data is used in operations.
Data validation is crucial for business operations because it ensures data reliability. Accurate data leads to better decisions, fewer mistakes, and improved operational efficiency.
Manual data validation requires human effort to check for errors, which is time-consuming and prone to mistakes. Automated data validation uses tools to perform these checks faster and more accurately, saving time and resources.
Discover How Fortune 500 Companies Use DataBuck to Cut Data Validation Costs by 50%
![]()
Enter your email address to access to downloads
Recent Posts



Get Started!
